PythonжҖҺд№Ҳе®һзҺ°еҫ®еҚҡеҠЁжҖҒеӣҫзүҮзҲ¬еҸ–
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңPythonжҖҺд№Ҳе®һзҺ°еҫ®еҚҡеҠЁжҖҒеӣҫзүҮзҲ¬еҸ–вҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңPythonжҖҺд№Ҳе®һзҺ°еҫ®еҚҡеҠЁжҖҒеӣҫзүҮзҲ¬еҸ–вҖқеҗ§!
жҲ‘们жүҫеҲ°еҫ®еҚҡеңЁжөҸи§ҲеҷЁдёҠйқўз”ЁдәҺжүӢжңәз«Ҝзҡ„и°ғиҜ•зҡ„APLпјҢеҰӮдҪ•жүҫеҲ°е‘ўпјҹ

1.жЁЎжӢҹжҗңзҙўз”ЁжҲ·

жҗңзҙўдёҖдёӘз”ЁжҲ·иҺ·еҸ–еҲ°зҡ„api:
https://m.weibo.cn/api/container/getIndex?containerid=100103type=1&q=еҚҠеҚҠеӯҗ&page_type=searchall
1.1 еҜ№apiеҶ…еҸӮж•°иҝӣиЎҢеӨ„зҗҶ
containerid=100103type=1&q=еҚҠеҚҠеӯҗ ——> containerid=100103type%3D1%26q%3D%E5%8D%8A%E5%8D%8A%E5%AD%90_
иҝҷдёӘеҸӮж•°йңҖиҰҒжҸҗеүҚиҪ¬з ҒпјҢеҗҰеҲҷж— жі•иҺ·еҸ–ж•°жҚ®
1.2 еҜ№з”ЁжҲ·еҗҚиҝӣиЎҢеҲӨж–ӯпјҢйҖҡиҝҮеҗҺжҸҗеҸ–uid
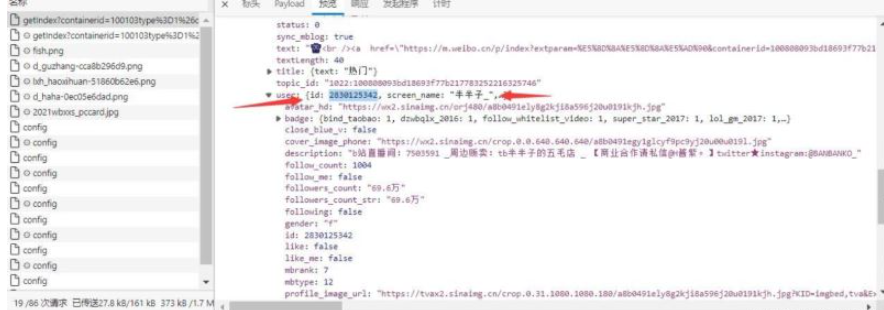
2.иҺ·еҸ–moreеҸӮж•°
GET
api : https://m.weibo.cn/profile/info?uid=2830125342
2.1 жҸҗеҸ–并еӨ„зҗҶmoreеҸӮж•°
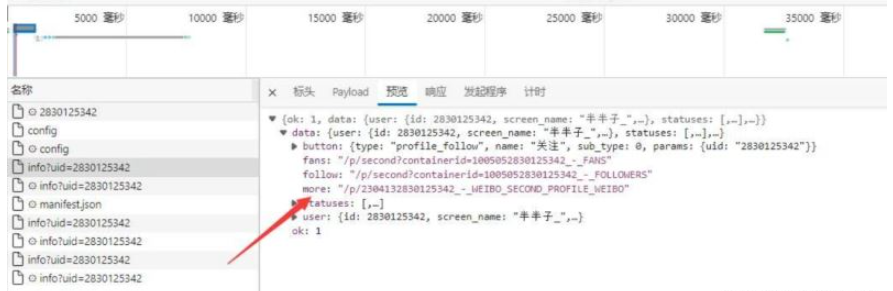
3.еҫӘзҺҜжҸҗеҸ–еӣҫзүҮid
GET
api : https://m.weibo.cn/api/container/getIndex?containerid=2304132830125342_-_WEIBO_SECOND_PROFILE_WEIBO&page_type=03&page=1
3.1 жҸҗеҸ–еӣҫзүҮid——>pic_id
3.2 иҺ·еҸ–еҸ‘йҖҒеӣҫзүҮз”ЁжҲ·
3.3 ж №жҚ®еҠЁжҖҒеҲӣе»әж—¶й—ҙз”ҹжҲҗз”ЁжҲ·е”ҜдёҖиҜҶеҲ«з Ғ
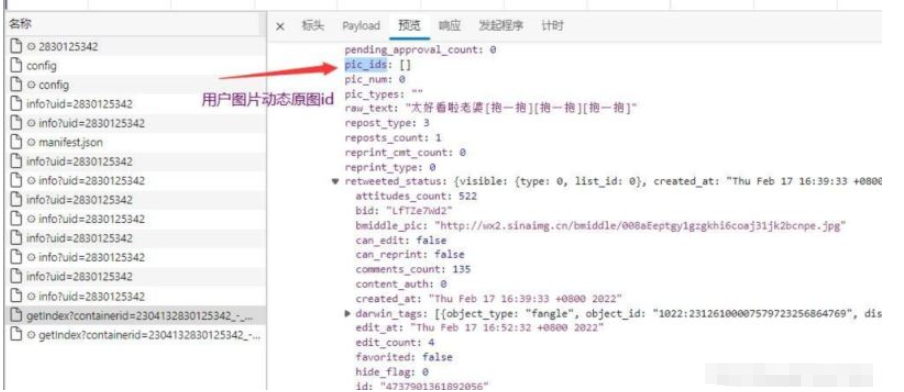
4.дёӢиҪҪеӣҫзүҮ
жҲ‘们д»ҺжөҸи§ҲеҷЁжҠ“еҢ…дёӯе°ұдјҡиҺ·еҸ–еҲ°еҗҺеҸ°жңҚеҠЎеҷЁеҸ‘з»ҷжөҸи§ҲеҷЁзҡ„еӣҫзүҮй“ҫжҺҘ
https://wx2.sinaimg.cn/large/pic_id.jpg
жөҸи§ҲеҷЁжү“ејҖиҝҷдёӘй“ҫжҺҘе°ұеҸҜд»ҘзӣҙжҺҘдёӢиҪҪеӣҫзүҮ
зҲ¬еҸ–е®Ңж•ҙд»Јз Ғпјҡ
import os
import sys
import time
from urllib.parse import quote
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
def time_to_str(c_at):
ti = time.strptime(c_at, '%a %b %d %H:%M:%S +0800 %Y')
time_str = time.strftime('%Y%m%d%H%M%S', ti)
return time_str
# 1. жҗңзҙўз”ЁжҲ·пјҢиҺ·еҸ–uid
# 2. йҖҡиҝҮuidиҺ·еҸ–з©әй—ҙеҠЁжҖҒе…ій”®еҸӮж•°
# 3. иҺ·еҸ–еҠЁжҖҒеҶ…е®№
# 4. жҸҗеҸ–еӣҫзүҮеҸӮж•°
# 5. дёӢиҪҪеӣҫзүҮ
# 1. жҗңзҙўз”ЁжҲ·пјҢиҺ·еҸ–uid
# ========= з”ЁжҲ·еҗҚ =========
# иҫ“е…ҘдёҚеҗҢзҡ„з”ЁжҲ·еҗҚеҸҜеҲҮжҚўдёӢиҪҪзҡ„з”ЁжҲ·еӣҫзүҮ
# з”ЁжҲ·еҗҚйңҖиҰҒе®Ңе…ЁеҢ№й…Қ
name = 'еҚҠеҚҠеӯҗ_'
# =========================
con_id = f'100103type=1&q={name}'
# иҝҷдёӘжқЎд»¶йңҖиҰҒиҪ¬з Ғ
con_id = quote(con_id, 'utf-8')
user_url = f'https://m.weibo.cn/api/container/getIndex?containerid={con_id}&page_type=searchall'
user_json = requests.get(url=user_url, headers=headers).json()
user_cards = user_json['data']['cards']
for card_num in range(len(user_cards)):
if 'mblog' in user_cards[card_num]:
if user_cards[card_num]['mblog']['user']['screen_name'] == name:
print(f'жӯЈеңЁиҺ·еҸ–{name}зҡ„з©әй—ҙ')
# 2. йҖҡиҝҮuidиҺ·еҸ–з©әй—ҙеҠЁжҖҒе…ій”®еҸӮж•°
user_id = user_cards[card_num]['mblog']['user']['id']
info_url = f'https://m.weibo.cn/profile/info?uid={user_id}'
info_json = requests.get(url=info_url, headers=headers).json()
more_card = info_json['data']['more'].split("/")[-1]
break
file_name = 'weibo'
if not os.path.exists(file_name):
os.mkdir(file_name)
if len(more_card) == 0:
sys.exit()
page_type = '03'
page = 0
while True:
# 3. иҺ·еҸ–еҠЁжҖҒеҶ…е®№
page += 1
url = f'https://m.weibo.cn/api/container/getIndex?containerid={more_card}&page_type={page_type}&page={page}'
param = requests.get(url=url, headers=headers).json()
cards = param['data']['cards']
print(f'第 {page} йЎө')
for i in range(len(cards)):
card = cards[i]
if card['card_type'] != 9:
continue
mb_log = card['mblog']
# 4. жҸҗеҸ–еӣҫзүҮеҸӮж•°
# иҺ·еҸ–жң¬дәәзҡ„еӣҫзүҮ
pic_ids = mb_log['pic_ids']
user_name = mb_log['user']['screen_name']
created_at = mb_log['created_at']
if len(pic_ids) == 0:
# иҺ·еҸ–иҪ¬еҸ‘зҡ„еӣҫзүҮ
if 'retweeted_status' not in mb_log:
continue
if 'pic_ids' not in mb_log['retweeted_status']:
continue
pic_ids = mb_log['retweeted_status']['pic_ids']
user_name = mb_log['retweeted_status']['user']['screen_name']
created_at = mb_log['retweeted_status']['created_at']
time_name = time_to_str(created_at)
pic_num = 1
print(f'======== {user_name} ========')
# 5. дёӢиҪҪеӣҫзүҮ
for pic_id in pic_ids:
pic_url = f'https://wx2.sinaimg.cn/large/{pic_id}.jpg'
pic_data = requests.get(pic_url, headers)
# ж–Ү件еҗҚ з”ЁжҲ·еҗҚ_ж—Ҙжңҹ(е№ҙжңҲж—Ҙж—¶еҲҶз§’)_зј–еҸ·.jpg
# дҫӢ:еҚҠеҚҠеӯҗ__20220212120146_1.jpg
with open(f'{file_name}/{user_name}_{time_name}_{pic_num}.jpg', mode='wb') as f:
f.write(pic_data.content)
print(f' жӯЈеңЁдёӢиҪҪпјҡ{pic_id}.jpg')
pic_num += 1
time.sleep(2)еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңPythonжҖҺд№Ҳе®һзҺ°еҫ®еҚҡеҠЁжҖҒеӣҫзүҮзҲ¬еҸ–вҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ





