这篇文章主要介绍了Java集合框架是什么,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
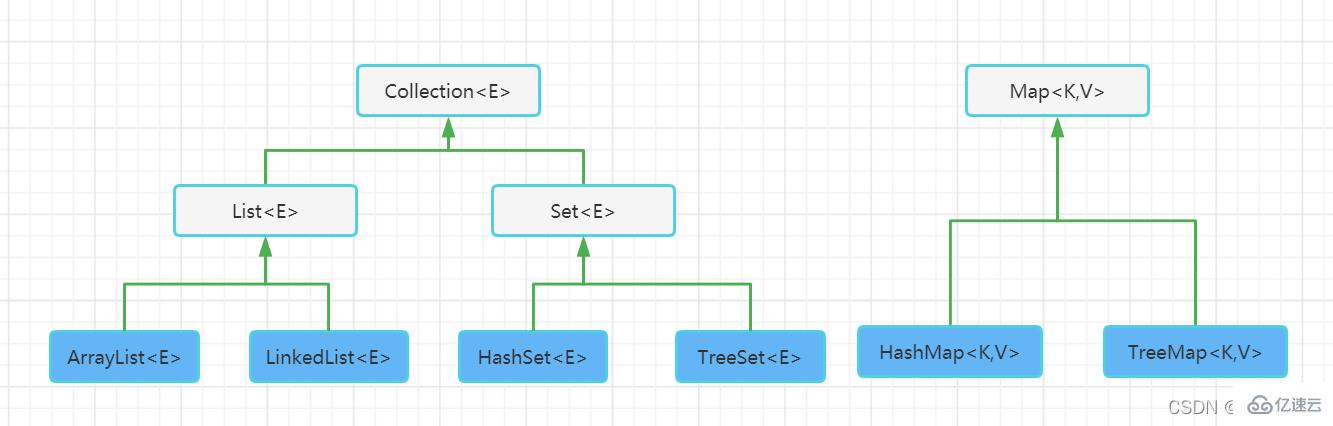
Java集合框架提供了一套性能优良,使用方便的接口和类,他们位于java.util包中。容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表
TreeSet
基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)
HashSet
基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
LinkedHashSet
具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
ArrayList
基于动态数组实现,支持随机访问。
Vector
和 ArrayList 类似,但它是线程安全的。
LinkedList
基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
LinkedList
可以实现双向队列。
PriorityQueue
基于堆结构实现,可以用它来实现优先队列。
TreeMap
基于红黑树实现。
HashMap
基于哈希表实现。
HashTable
和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
LinkedHashMap
使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序
Collection 接口存储一组不唯一,无序的对象
List 接口存储一组不唯一,有序的对象。
Set 接口存储一组唯一,无序的对象
Map 接口存储一组键值对象,提供key到value的映射
ArrayList实现了长度可变的数组,在内存中分配连续的空间。遍历元素和随机访问元素的效率比较高
LinkedList采用链表存储方式。插入、删除元素时效率比较高
HashSet采用哈希算法实现的Set
HashSet的底层是用HashMap实现的,因此查询效率较高,由于采用hashCode算法直接确定 元素的内存地址,增删效率高
| 方法 | 说明 |
|---|---|
| boolean add(Object o) | 在列表的末尾顺序添加元素,起始索引位置从0开始 |
| void add(int index, Object o) | 在指定的索引位置添加元素,索引位置必须介于0和列表中元素个数之间 |
| int size() | 返回列表中的元素个数 |
| Object get(int index) | 返回指定索引位置处的元素。取出的元素是Object类型,使用前品要进行益制类型转换 |
| boolean contains(Object o) | 判断列表中是否存在指定元素 |
| boolean remove(Object o) | 从列表中删除元素 |
| Object remove(int index) | 从列表中删除指定位置元素,起始索引位量从0开始 |
ArrayList是可以动态增长和缩减的索引序列,它是基于数组实现的List类
该类封装了一个动态再分配的Object[]数组,每一个类对象都有一个capacity[容量]属性,表示它们所封装的Object[]数组的长度,当向ArrayList中添加元素时,该属性值会自动增加。如果想ArrayList中添加大量元素,可使用ensureCapacity方法一次性增加capacity,可以减少增加重分配的次数提高性能
ArrayList的用法和Vector向类似,但是Vector是一个较老的集合,具有很多缺点,不建议使用
另外,ArrayList和Vector的区别是:ArrayList是线程不安全的,当多条线程访问同一个ArrayList集合时,程序需要手动保证该集合的同步性,而Vector则是线程安全的。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable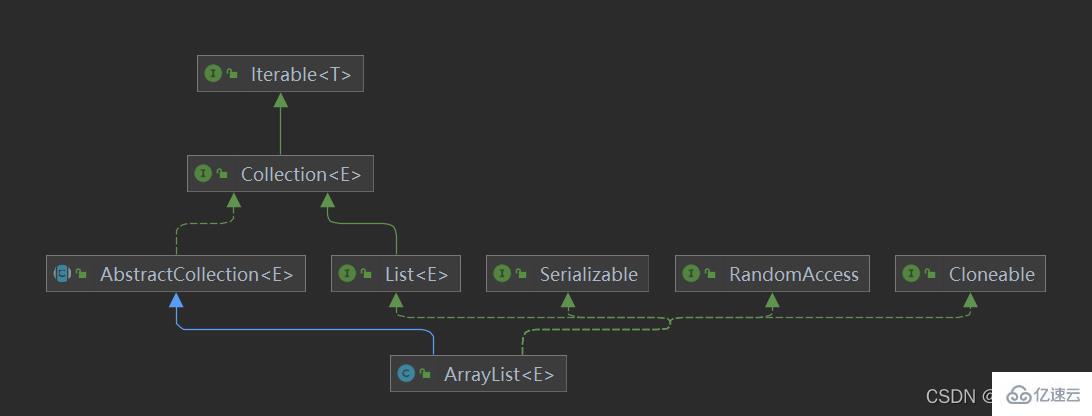
这里简单解释一下几个接口
RandomAccess接口
这个是一个标记性接口,通过查看api文档,它的作用就是用来快速随机存取,有关效率的问题,在实现了该接口的话,那么使用普通的for循环来遍历,性能更高,例如ArrayList。而没有实现该接口的话,使用Iterator来迭代,这样性能更高,例如linkedList。所以这个标记性只是为了 让我们知道我们用什么样的方式去获取数据性能更好。
Cloneable接口
实现了该接口,就可以使用Object.Clone()方法了。
Serializable接口
实现该序列化接口,表明该类可以被序列化。什么是序列化?简单的说,就是能够从类变成字节流传输,然后还能从字节流变成原来的类。
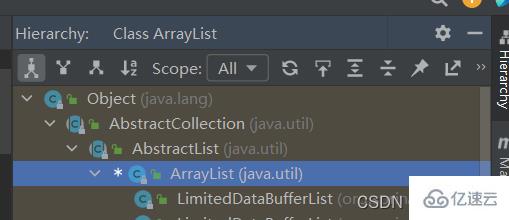
这里的继承结构可通过IDEA中Navigate>Type Hierarchy查看
//版本号
private static final long serialVersionUID = 8683452581122892189L;
//缺省容量
private static final int DEFAULT_CAPACITY = 10;
//空对象数组
private static final Object[] EMPTY_ELEMENTDATA = {};
//缺省空对象数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//存储的数组元素
transient Object[] elementData; // non-private to simplify nested class access
//实际元素大小,默认为0
private int size;
//最大数组容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;/**
* 构造具有指定初始容量的空列表
* 如果指定的初始容量为负,则为IllegalArgumentException
*/public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}}/**
* 默认空数组的大小为10
* ArrayList中储存数据的其实就是一个数组,这个数组就是elementData
*/public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}/**
* 按照集合迭代器返回元素的顺序构造包含指定集合的元素的列表
*/public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 转换为数组
//每个集合的toarray()的实现方法不一样,所以需要判断一下,如果不是Object[].class类型,那么久需要使用ArrayList中的方法去改造一下。
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 否则就用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}}每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。数组扩容通过一个公开的方法ensureCapacity(int minCapacity)来实现。在实际添加大量元素前,我也可以使用ensureCapacity来手动增加ArrayList实例的容量,以减少递增式再分配的数量。
数组进行扩容时,会将**老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。**这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}private static int calculateCapacity(Object[] elementData, int minCapacity) {
//判断初始化的elementData是不是空的数组,也就是没有长度
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//因为如果是空的话,minCapacity=size+1;其实就是等于1,空的数组没有长度就存放不了
//所以就将minCapacity变成10,也就是默认大小,但是在这里,还没有真正的初始化这个elementData的大小
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
//确认实际的容量,上面只是将minCapacity=10,这个方法就是真正的判断elementData是否够用
return minCapacity;}private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//minCapacity如果大于了实际elementData的长度,那么就说明elementData数组的长度不够用
/*第一种情况:由于elementData初始化时是空的数组,那么第一次add的时候,
minCapacity=size+1;也就minCapacity=1,在上一个方法(确定内部容量ensureCapacityInternal)
就会判断出是空的数组,就会给将minCapacity=10,到这一步为止,还没有改变elementData的大小。
第二种情况:elementData不是空的数组了,那么在add的时候,minCapacity=size+1;也就是
minCapacity代表着elementData中增加之后的实际数据个数,拿着它判断elementData的length
是否够用,如果length不够用,那么肯定要扩大容量,不然增加的这个元素就会溢出。*/
if (minCapacity - elementData.length > 0)
grow(minCapacity);}//ArrayList核心的方法,能扩展数组大小的真正秘密。private void grow(int minCapacity) {
//将扩充前的elementData大小给oldCapacity
int oldCapacity = elementData.length;
//newCapacity就是1.5倍的oldCapacity
int newCapacity = oldCapacity + (oldCapacity >> 1);
/*这句话就是适应于elementData就空数组的时候,length=0,那么oldCapacity=0,newCapacity=0,
所以这个判断成立,在这里就是真正的初始化elementData的大小了,就是为10.前面的工作都是准备工作。
*/
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果newCapacity超过了最大的容量限制,就调用hugeCapacity,也就是将能给的最大值给newCapacity
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//新的容量大小已经确定好就copy数组,改变容量大小。
elementData = Arrays.copyOf(elementData, newCapacity);}//用来赋最大值private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//如果minCapacity都大于MAX_ARRAY_SIZE,那么就Integer.MAX_VALUE返回,反之将MAX_ARRAY_SIZE返回。
//相当于给ArrayList上了两层防护
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;}/**
* 添加一个特定的元素到list的末尾。
* 先size+1判断数组容量是否够用,最后加入元素
*/public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;}/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/public void add(int index, E element) {
//检查index也就是插入的位置是否合理。
rangeCheckForAdd(index);
//检查容量是否够用,不够就自动扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
//这个方法就是用来在插入元素之后,要将index之后的元素都往后移一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;}当调用add()方法时,实际函数调用:
add→ensureCapacityInternal→ensureExplicitCapacity(→grow→hugeCapacity)
例如刚开始初始化一个空数组后add一个值,会首先进行自动扩容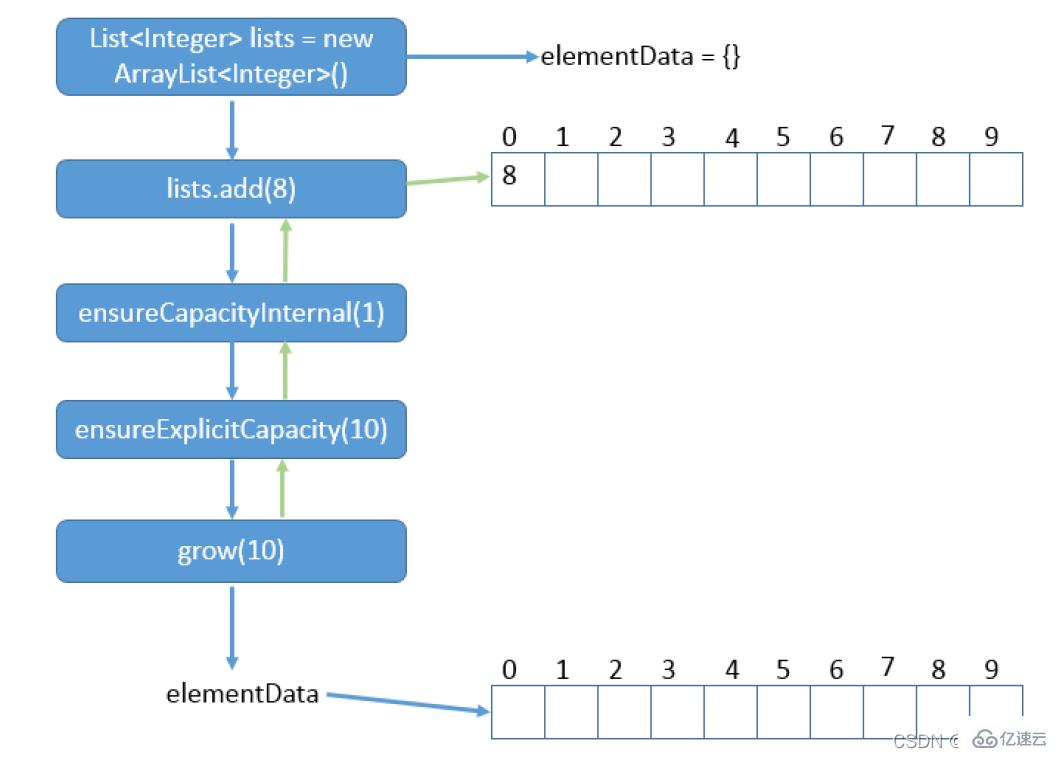
将底层数组的容量调整为当前列表保存的实际元素的大小的功能
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA : Arrays.copyOf(elementData, size);
}}remove()方法也有两个版本,一个是remove(int index)删除指定位置的元素,另一个是remove(Object o)删除第一个满足o.equals(elementData[index])的元素。删除操作是add()操作的逆过程,需要将删除点之后的元素向前移动一个位置。需要注意的是为了让GC起作用,必须显式的为最后一个位置赋null值。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; //清除该位置的引用,让GC起作用
return oldValue;
}这里简单介绍了核心方法,其他方法查看源码可以很快了解
ArrayList采用了快速失败的机制,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,并抛出ConcurrentModificationException异常,而不是冒着在将来某个不确定时间发生任意不确定行为的风险
ArrayList可以存放null
ArrayList本质上就是一个elementData数组
ArrayList区别于数组的地方在于能够自动扩展大小,其中关键的方法就是gorw()方法
ArrayList中removeAll(collection c)和clear()的区别就是removeAll可以删除批量指定的元素,而clear是全是删除集合中的元素
ArrayList由于本质是数组,所以它在数据的查询方面会很快,而在插入删除这些方面,性能下降很多,有移动很多数据才能达到应有的效果
ArrayList实现了RandomAccess,所以在遍历它的时候推荐使用for循环
| 方法名 | 说明 |
|---|---|
| void addFirst(Object o) | 在列表的首部添加元素 |
| void addLast(Object o) | 在列表的未尾添加元素 |
| Object getFirst() | 返回列表中的第一个元素 |
| Object getLast() | 返回列表中的最后一个元素 |
| Object removeFirst() | 删除并返回列表中的第一个元素 |
| Object removeLast() | 删除并返回列表中的最后一个元素 |
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue_的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
LinkedList的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable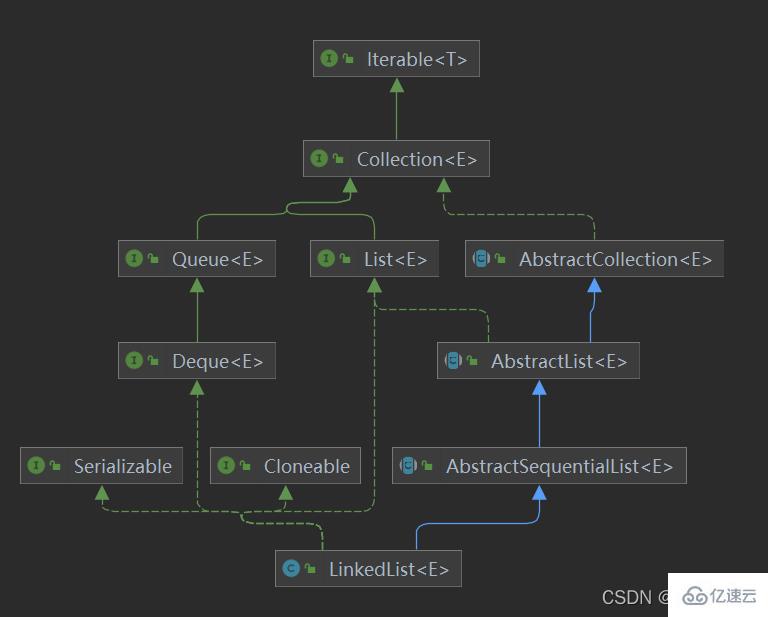
这里可以发现LinkedList多了一层AbstractSequentialList的抽象类,这是为了减少实现顺序存取(例如LinkedList)这种类的工作。如果自己想实现顺序存取这种特性的类(就是链表形式),那么就继承 这个AbstractSequentialList抽象类,如果想像数组那样的随机存取的类,那么就去实现AbstracList抽象类。
List接口
列表add、set等一些对列表进行操作的方法
Deque接口
有队列的各种特性
Cloneable接口
能够复制,使用那个copy方法
Serializable接口
能够序列化。
没有RandomAccess
推荐使用iterator,在其中就有一个foreach,增强的for循环,其中原理也就是iterator,我们在使用的时候,使用foreach或者iterator
transient关键字修饰,这也意味着在序列化时该域是不会序列化的
//实际元素个数transient int size = 0;
//头结点transient Node<E> first;
//尾结点transient Node<E> last;public LinkedList() {}public LinkedList(Collection<? extends E> c) {
this();
//将集合c中的各个元素构建成LinkedList链表
addAll(c);}//根据前面介绍双向链表就知道这个代表什么了,linkedList的奥秘就在这里private static class Node<E> {
// 数据域(当前节点的值)
E item;
//后继
Node<E> next;
//前驱
Node<E> prev;
// 构造函数,赋值前驱后继
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}}public boolean add(E e) {
linkLast(e);
return true;}void linkLast(E e) {
//临时节点l(L的小写)保存last,也就是l指向了最后一个节点
final Node<E> l = last;
//将e封装为节点,并且e.prev指向了最后一个节点
final Node<E> newNode = new Node<>(l, e, null);
//newNode成为了最后一个节点,所以last指向了它
last = newNode;
if (l == null)
//判断是不是一开始链表中就什么都没有,如果没有,则new Node就成为了第一个结点,first和last都指向它
first = newNode;
else
//正常的在最后一个节点后追加,那么原先的最后一个节点的next就要指向现在真正的 最后一个节点,原先的最后一个节点就变成了倒数第二个节点
l.next = newNode;
//添加一个节点,size自增
size++;
modCount++;}addAll()有两个重载函数,addAll(Collection<? extends E>)型和addAll(int,Collection<? extends E>)型,我们平时习惯调用的addAll(Collection<?extends E>)型会转化为addAll(int,Collection<? extends<E>)型
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);}public boolean addAll(int index, Collection<? extends E> c) {
//检查index这个是否为合理
checkPositionIndex(index);
//将集合c转换为Object数组
Object[] a = c.toArray();
//数组a的长度numNew,也就是由多少个元素
int numNew = a.length;
if (numNew == 0)
//如果空的就什么也不做
return false;
Node<E> pred, succ;
//构造方法中传过来的就是index==size
//情况一:构造方法创建的一个空的链表,那么size=0,last、和first都为null。linkedList中是空的。
//什么节点都没有。succ=null、pred=last=null
//情况二:链表中有节点,size就不是为0,first和last都分别指向第一个节点,和最后一个节点,
//在最后一个节点之后追加元素,就得记录一下最后一个节点是什么,所以把last保存到pred临时节点中。
//情况三index!=size,说明不是前面两种情况,而是在链表中间插入元素,那么就得知道index上的节点是谁,
//保存到succ临时节点中,然后将succ的前一个节点保存到pred中,这样保存了这两个节点,就能够准确的插入节点了
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
/*如果succ==null,说明是情况一或者情况二,
情况一、构造方法,也就是刚创建的一个空链表,pred已经是newNode了,
last=newNode,所以linkedList的first、last都指向第一个节点。
情况二、在最后节后之后追加节点,那么原先的last就应该指向现在的最后一个节点了,
就是newNode。*/
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;}//根据引下标找到该结点并返回Node<E> node(int index) {
//判断插入的位置在链表前半段或者是后半段
if (index < (size >> 1)) {
Node<E> x = first;
//从头结点开始正向遍历
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
//从尾结点开始反向遍历
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}}/*如果我们要移除的值在链表中存在多个一样的值,那么我们
会移除index最小的那个,也就是最先找到的那个值,如果不存在这个值,那么什么也不做
*/public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;}不能传一个null值E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
//x的前后指向都为null了,也把item为null,让gc回收它
x.item = null;
size--;
modCount++;
return element;}**get(index)、indexOf(Object o)**等查看源码即可
在LinkedList中除了有一个Node的内部类外,应该还能看到另外两个内部类,那就是ListItr,还有一个是DescendingIterator内部类
/*这个类,还是调用的ListItr,作用是封装一下Itr中几个方法,让使用者以正常的思维去写代码,
例如,在从后往前遍历的时候,也是跟从前往后遍历一样,使用next等操作,而不用使用特殊的previous。
*/private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}}linkedList本质上是一个双向链表,通过一个Node内部类实现的这种链表结构。linkedList能存储null值
跟ArrayList相比较,就真正的知道了,LinkedList在删除和增加等操作上性能好,而ArrayList在查询的性能上好,从源码中看,它不存在容量不足的情况
linkedList不光能够向前迭代,还能像后迭代,并且在迭代的过程中,可以修改值、添加值、还能移除值
linkedList不光能当链表,还能当队列使用,这个就是因为实现了Deque接口
ArrayList底层是用数组实现的顺序表,是随机存取类型,可自动扩增,并且在初始化时,数组的长度是0,只有在增加元素时,长度才会增加。默认是10,不能无限扩增,有上限,在查询操作的时候性能更好
LinkedList底层是用链表来实现的,是一个双向链表,注意这里不是双向循环链表,顺序存取类型。在源码中,似乎没有元素个数的限制。应该能无限增加下去,直到内存满了在进行删除,增加操作时性能更好。
两个都是线程不安全的,在iterator时,会发生fail-fast:快速失效。
ArrayList线程不安全,在用iterator,会发生fail-fast
Vector线程安全,因为在方法前加了Synchronized关键字,也会发生fail-fast
在java.util下的集合都是发生fail-fast,而在java.util.concurrent下的发生的都是fail-safe
fail-fast
快速失败,例如在arrayList中使用迭代器遍历时,有另外的线程对arrayList的存储数组进行了改变,比 如add、delete等使之发生了结构上的改变,所以Iterator就会快速报一个java.util.ConcurrentModificationException异常(并发修改异常),这就是快速失败
fail-safe
安全失败,在java.util.concurrent下的类,都是线程安全的类,他们在迭代的过程中,如果有线程进行结构的改变,不会报异常,而是正常遍历,这就是安全失败
为什么在java.util.concurrent包下对集合有结构的改变却不会报异常?
在concurrent下的集合类增加元素的时候使用Arrays.copyOf()来拷贝副本,在副本上增加元素,如果有其他线程在此改变了集合的结构,那也是在副本上的改变,而不是影响到原集合,迭代器还是照常遍历,遍历完之后,改变原引用指向副本,所以总的一句话就是如果在此包下的类进行增加删除,就会出现一个副本。所以能防止fail-fast,这种机制并不会出错,所以我们叫这种现象为fail-safe
vector也是线程安全的,为什么是fail-fast呢?
出现fail-safe是因为他们在实现增删的底层机制不一样,就像上面说的,会有一个副本,而像arrayList、linekdList、verctor等他们底层就是对着真正的引用进行操作,所以才会发生异常
vector实现线程安全的方法是在每个操作方法上加锁,这些锁并不是必须要的,在实际开发中,一般都是通过锁一系列的操作来实现线程安全,也就是说将需要同步的资源放一起加锁来保证线程安全
如果多个Thread并发执行一个已经加锁的方法,但是在该方法中,又有Vector的存在,Vector
本身实现中已经加锁了,那么相当于锁上又加锁,会造成额外的开销
Vector还有fail-fast的问题,也就是说它也无法保证遍历安全,在 遍历时又得额外加锁,又是额外的开销,还不如直接用arrayList,然后再加锁
总结:Vector在你不需要进行线程安全的时候,也会给你加锁,也就导致了额外开销,所以在jdk1.5之后就被弃用了,现在如果要用到线程安全的集合,都是从java.util.concurrent包下去拿相应的类。
通过key、value封装成一个entry对象,然后通过key的值来计算该entry的hash值,通过entry的hash 值和数组的长度length来计算出entry放在数组中的哪个位置上面,每次存放都是将entry放在第一个位置。
HashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素;除该类未实现同步外,其余跟Hashtable大致相同;跟TreeMap不同,该容器不保证元素顺序,根据需要该容器可能会对元素重新哈希,元素的顺序也会被重新打散,因此不同时间迭代同一个HashMap的顺序可能会不同。 根据对冲突的处理方式不同,哈希表有两种实现方式,一种开放地址方式(Open addressing),另一种是冲突链表方式(Separate chaining with linked lists)。Java7 HashMap采用的是冲突链表方式。

Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。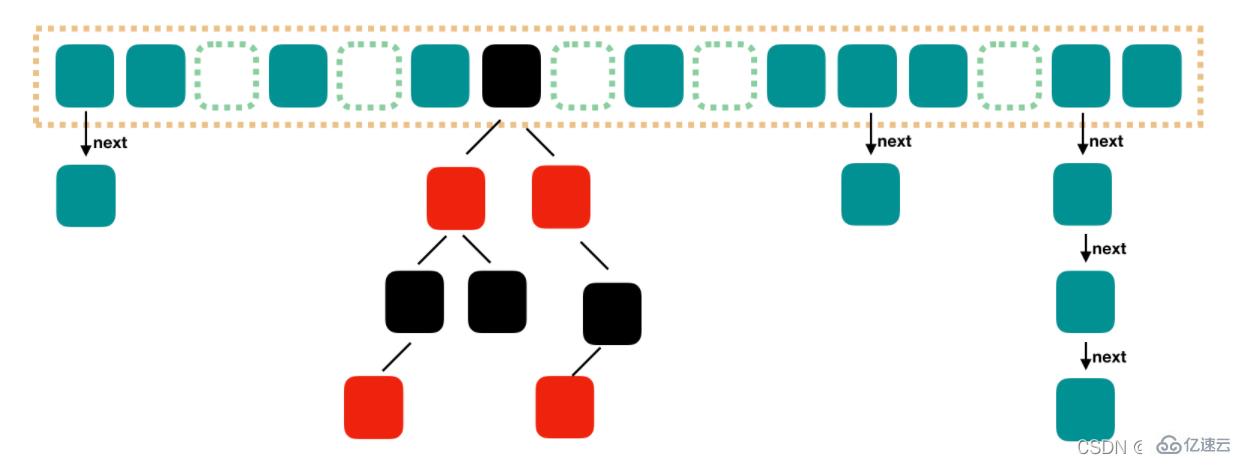
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
//序列号private static final long serialVersionUID = 362498820763181265L;
//默认的初始容量static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// aka 16
//最大容量static final int MAXIMUM_CAPACITY = 1 << 30;
//默认加载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;
//当桶(bucket)上的结点数大于这个值时会转成红黑树static final int TREEIFY_THRESHOLD = 8;
//当桶(bucket)上的结点数小于这个值时树转链表static final int UNTREEIFY_THRESHOLD = 6;
//桶中结构转化为红黑树对应的table的最小大小static final int MIN_TREEIFY_CAPACITY = 64;
//存储元素的数组,总是2的幂次倍transient Node<K,V>[] table;
//存放具体元素的集transient Set<Map.Entry<K,V>> entrySet;
//存放元素的个数,注意这个不等于数组的长度transient int size;
//每次扩容和更改map结构的计数器transient int modCount;
//临界值,当实际大小(容量*填充因子)超过临界值时,会进行扩容int threshold;
//填充因子,计算HashMap的实时装载因子的方法为:size/capacityfinal float loadFactor;public HashMap(int initialCapacity, float loadFactor) {
// 初始容量不能小于0,否则报错
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始容量不能大于最大值,否则为最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//填充因子不能小于或等于0,不能为非数字
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//初始化填充因子
this.loadFactor = loadFactor;
//初始化threshold大小
this.threshold = tableSizeFor(initialCapacity);}//这个方法将传进来的参数转变为2的n次方的数值static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}/**
* 自定义初始容量,加载因子为默认
*/public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);}/**
* 使用默认的加载因子等字段
*/public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}public HashMap(Map<? extends K, ? extends V> m) {
//初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
//将m中的所有元素添加至HashMap中
putMapEntries(m, false);}//将m的所有元素存入该实例final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
//判断table是否已经初始化
if (table == null) { // pre-size
//未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
//计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
//将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}}put()方法
先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则查找是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链表尾部,注意JDK1.7中采用的是头插法,即每次都将冲突的键值对放置在链表头,这样最初的那个键值对最终就会成为链尾,而JDK1.8中使用的是尾插法。此外,若table在该处没有元素,则直接保存。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//第一次put元素时,table数组为空,先调用resize生成一个指定容量的数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//hash值和n-1的与运算结果为桶的位置,如果该位置空就直接放置一个Node
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果计算出的bucket不空,即发生哈希冲突,就要进一步判断
else {
Node<K,V> e; K k;
//判断当前Node的key与要put的key是否相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断当前Node是否是红黑树的节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//以上都不是,说明要new一个Node,加入到链表中
else {
for (int binCount = 0; ; ++binCount) {
//在链表尾部插入新节点,注意jdk1.8是在链表尾部插入新节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果当前链表中的元素大于树化的阈值,进行链表转树的操作
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//在链表中继续判断是否已经存在完全相同的key
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//走到这里,说明本次put是更新一个已存在的键值对的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//在hashMap中,afterNodeAccess方法体为空,交给子类去实现
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果当前size超过临界值,就扩容。注意是先插入节点再扩容
if (++size > threshold)
resize();
//在hashMap中,afterNodeInsertion方法体为空,交给子类去实现
afterNodeInsertion(evict);
return null;}resize() 数组扩容
用于初始化数组或数组扩容,每次扩容后,容量为原来的 2 倍,并进行数据迁移
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // 对应数组扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将数组大小扩大一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 将阈值扩大一倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 对应使用 new HashMap(int initialCapacity) 初始化后,第一次 put 的时候
newCap = oldThr;
else {// 对应使用 new HashMap() 初始化后,第一次 put 的时候
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 用新的数组大小初始化新的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // 如果是初始化数组,到这里就结束了,返回 newTab 即可
if (oldTab != null) {
// 开始遍历原数组,进行数据迁移。
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果该数组位置上只有单个元素,那就简单了,简单迁移这个元素就可以了
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是红黑树,具体我们就不展开了
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 这块是处理链表的情况,
// 需要将此链表拆成两个链表,放到新的数组中,并且保留原来的先后顺序
// loHead、loTail 对应一条链表,hiHead、hiTail 对应另一条链表,代码还是比较简单的
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 第一条链表
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第二条链表的新的位置是 j + oldCap,这个很好理解
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;}get()过程
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判断第一个节点是不是就是需要的
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
// 判断是否是红黑树
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 链表遍历
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;}HashSet是对HashMap的简单包装,其他还有迭代器等
关于数组扩容,从putVal源代码中我们可以知道,当插入一个元素的时候size就加1,若size大于threshold的时候,就会进行扩容。假设我们的capacity大小为32,loadFator为0.75,则threshold为24 = 32 * 0.75,此时,插入了25个元素,并且插入的这25个元素都在同一个桶中,桶中的数据结构为红黑树,则还有31个桶是空的,也会进行扩容处理,其实此时,还有31个桶是空的,好像似乎不需要进行扩容处理,但是是需要扩容处理的,因为此时我们的capacity大小可能不适当。我们前面知道,扩容处理会遍历所有的元素,时间复杂度很高;前面我们还知道,经过一次扩容处理后,元素会更加均匀的分布在各个桶中,会提升访问效率。所以说尽量避免进行扩容处理,也就意味着,遍历元素所带来的坏处大于元素在桶中均匀分布所带来的好处。
HashMap在JDK1.8以前是一个链表散列这样一个数据结构,而在JDK1.8以后是一个数组加链表加红黑树的数据结构
通过源码的学习,HashMap是一个能快速通过key获取到value值得一个集合,原因是内部使用的是hash查找值得方法
另外LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有**entry**连接起来,这样是为保证元素的迭代顺序跟插入顺序相同
此类完全由在 collection 上进行操作或返回 collection 的静态方法组成。它包含在 collection 上操作的多态算法,即“包装器”,包装器返回由指定 collection 支持的新 collection,以及少数其他内容。如果为此类的方法所提供的 collection 或类对象为 null,则这些方法都将抛出NullPointerException
//反转列表中元素的顺序
static void reverse(List<?> list)
//对List集合元素进行随机排序
static void shuffle(List<?> list)
//根据元素的自然顺序 对指定列表按升序进行排序
static void sort(List<T> list)
//根据指定比较器产生的顺序对指定列表进行排序
static <T> void sort(List<T> list, Comparator<? super T> c)
//在指定List的指定位置i,j处交换元素
static void swap(List<?> list, int i, int j)
//当distance为正数时,将List集合的后distance个元素“整体”移到前面;当distance为负数时,将list集合的前distance个元素“整体”移到后边。该方法不会改变集合的长度
static void rotate(List<?> list, int distance)//使用二分搜索法搜索指定列表,以获得指定对象在List集合中的索引
//注意:此前必须保证List集合中的元素已经处于有序状态
static <T> int binarySearch(List<? extends Comparable<? super T>>list, T key)
//根据元素的自然顺序,返回给定collection 的最大元素
static Object max(Collection coll)
//根据指定比较器产生的顺序,返回给定 collection 的最大元素
static Object max(Collection coll,Comparator comp):
//根据元素的自然顺序,返回给定collection 的最小元素
static Object min(Collection coll):
//根据指定比较器产生的顺序,返回给定 collection 的最小元素
static Object min(Collection coll,Comparator comp):
//使用指定元素替换指定列表中的所有元素
static <T> void fill(List<? super T> list,T obj)
//返回指定co1lection中等于指定对象的出现次数
static int frequency(collection<?>c,object o)
//返回指定源列表中第一次出现指定目标列表的起始位置;如果没有出现这样的列表,则返回-1
static int indexofsubList(List<?>source, List<?>target)
//返回指定源列表中最后一次出现指定目标列表的起始位置;如果没有出现这样的列表,则返回-1
static int lastIndexofsubList(List<?>source,List<?>target)
//使用一个新值替换List对象的所有旧值o1dval
static <T> boolean replaceA1l(list<T> list,T oldval,T newval)Collectons提供了多个synchronizedXxx()方法,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。正如前面介绍的HashSet,TreeSet,arrayList,LinkedList,HashMap,TreeMap都是线程不安全的。Collections提供了多个静态方法可以把他们包装成线程同步的集合。
//返回指定 Collection 支持的同步(线程安全的)collection
static <T> Collection<T> synchronizedCollection(Collection<T> c)
//返回指定列表支持的同步(线程安全的)列表
static <T> List<T> synchronizedList(List<T> list)
//返回由指定映射支持的同步(线程安全的)映射
static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)
//返回指定 set 支持的同步(线程安全的)set
static <T> Set<T> synchronizedSet(Set<T> s)//返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
emptyXxx()
//返回一个只包含指定对象(只有一个或一个元素)的不可变的集合对象,此处的集合可以是:List,Set,Map。
singletonXxx():
//返回指定集合对象的不可变视图,此处的集合可以是:List,Set,Map
unmodifiableXxx()感谢你能够认真阅读完这篇文章,希望小编分享的“Java集合框架是什么”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



