这篇文章主要介绍了MySQL分区表中分区键必须是主键一部分的原因是什么的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇MySQL分区表中分区键必须是主键一部分的原因是什么文章都会有所收获,下面我们一起来看看吧。
前言:
分区是一种表的设计模式,通俗地讲表分区是将一大表,根据条件分割成若干个小表。但是对于应用程序来讲,分区的表和没有分区的表是一样的。换句话来讲,分区对于应用是透明的,只是数据库对于数据的重新整理
随着业务的不断发展,数据库中的数据会越来越多,相应地,单表的数据量也会越到越大,大到一个临界值,单表的查询性能就会下降。
这个临界值,并不能一概而论,它与硬件能力、具体业务有关。
虽然在很多 MySQL 运维规范里,都建议单表不超过 500w、1000w。
但实际上,我在生产环境,也见过大小超过 2T,记录数过亿的表,同时,业务不受影响。
单表过大时,业务通常会考虑两种拆分方案:水平切分和垂直切分。
水平切分,拆分的维度是行,一般会根据某种规则或算法将表中的记录拆分到多张表中。
拆分后的表既可在一个实例,也可在多个不同实例中。如果是后者,又会涉及到分布式事务。
垂直切分,拆分的维度是列,一般是将列拆分到多个业务模块中。这种拆分更多的是上层业务的拆分。
从改造的复杂程度来说,前者小于后者。
所以,在单表数据量过大时,业界用得较多的还是水平拆分。
常见的水平拆分方案有:分库分表、分区表。
虽然分库分表是一个比较彻底的水平拆分方案,但一方面,它的改造需要一定的时间;另一方面,它对开发的能力也有一定的要求。相对来说,分区表就比较简单,也无需业务改造。
很多人可能会认为 MySQL 的优势在于 OLTP 应用,对于 OLAP 应用就不太适合,所以,也不太推荐分区表这种偏 OLAP 的特性。
但实际上,对于某些业务类型,还是比较适合使用分区表的,尤其是那些有明显冷热数据之分,且数据的冷热与时间相关的业务。
下面我们看看分区表的优点:
提升查询性能:
对于分区表的查询操作,如果查询条件中包含分区键,则这个查询操作就只会被下推到符合条件的分区内进行,无关分区将自动过滤掉。
在数据量比较大的情况下,能提升查询速度。
对业务透明:
将表从一个非分区表转换为分区表,业务端无需做任何改造。
管理方便:
在对单个分区进行删除、迁移和维护时,不会影响到其它分区。
尤其是针对单个分区的删除(DROP)操作,避免了针对这个分区所有记录的 DELETE 操作。
遗憾的是,MySQL 分区表不支持并行查询。理论上,当一个查询涉及到多个分区时,分区与分区之间应进行并行查询,这样才能充分利用多核 CPU 资源。
但 MySQL 并不支持,包括早期的官方文档,也提到了这个问题,也将这个功能的实现放到了优先级列表中。
These features are not currently implemented in MySQL Partitioning, but are high on our list of priorities.
- Queries involving aggregate functions such as SUM() and COUNT() can easily be parallelized. A simple example of such a query might be SELECT salesperson_id, COUNT(orders) as order_total FROM sales GROUP BY salesperson_id;. By “parallelized,” we mean that the query can be run simultaneously on each partition, and the final result obtained merely by summing the results obtained for all partitions.
- Achieving greater query throughput in virtue of spreading data seeks over multiple disks.在 MySQL 5.7 中,对于分区表,有个很重大的更新,即 InnoDB 存储引擎原生支持了分区,无需再通过 ha_partition 接口来实现。
所以,在 MySQL 5.7 中,如果要创建基于 MyISAM 存储引擎的分区表,会提示 warning 。
The partition engine, used by table 'sbtest.t_range', is deprecated and will be removed in a future release. Please use native partitioning instead.而在 MySQL 8.0 中,则更为彻底,server 层移除了 ha_partition 接口代码。
如果要使用分区表,只能使用支持原生分区的存储引擎。在 MySQL 8.0 中,就只有 InnoDB。
这就意味着,在 MySQL 8.0 中,如果要创建 MyISAM 分区表,基本上就不可能了。
这也从另外一个角度说明了为什么生产上不建议使用 MyISAM 表。
mysql> CREATE TABLE t_range (
-> id INT,
-> name VARCHAR(10)
-> ) ENGINE = MyISAM
-> PARTITION BY RANGE (id) (
-> PARTITION p0 VALUES LESS THAN (5),
-> PARTITION p1 VALUES LESS THAN (10)
-> );
ERROR 1178 (42000): The storage engine for the table doesn't support native partitioning在使用分区表时,大家常常会碰到下面这个报错。
mysql> CREATE TABLE opr (
-> opr_no INT,
-> opr_date DATETIME,
-> description VARCHAR(30),
-> PRIMARY KEY (opr_no)
-> )
-> PARTITION BY RANGE COLUMNS (opr_date) (
-> PARTITION p0 VALUES LESS THAN ('20210101'),
-> PARTITION p1 VALUES LESS THAN ('20210102'),
-> PARTITION p2 VALUES LESS THAN MAXVALUE
-> );
ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function (prefixed columns are not considered).即分区键必须是主键的一部分。
上面的 opr 是一张操作流水表。其中,opr_no 是操作流水号,一般都会被设置为主键,opr_date 是操作时间。基于操作时间来进行分区,是一个常见的分区场景。
为了突破这个限制,可将opr_date 作为主键的一部分。
mysql> CREATE TABLE opr (
-> opr_no INT,
-> opr_date DATETIME,
-> description VARCHAR(30),
-> PRIMARY KEY (opr_no, opr_date)
-> )
-> PARTITION BY RANGE COLUMNS (opr_date) (
-> PARTITION p0 VALUES LESS THAN ('20210101'),
-> PARTITION p1 VALUES LESS THAN ('20210102'),
-> PARTITION p2 VALUES LESS THAN MAXVALUE
-> );
Query OK, 0 rows affected (0.04 sec)但是这么创建,又会带来一个新的问题,即对于同一个 opr_no ,可插入到不同分区中。
mysql> CREATE TABLE opr (
-> opr_no INT,
-> opr_date DATETIME,
-> description VARCHAR(30),
-> PRIMARY KEY (opr_no, opr_date)
-> )
-> PARTITION BY RANGE COLUMNS (opr_date) (
-> PARTITION p0 VALUES LESS THAN ('20210101'),
-> PARTITION p1 VALUES LESS THAN ('20210102'),
-> PARTITION p2 VALUES LESS THAN MAXVALUE
-> );
Query OK, 0 rows affected (0.04 sec)
mysql> insert into opr values(1,'2020-12-31 00:00:01','abc');
Query OK, 1 row affected (0.00 sec)
mysql> insert into opr values(1,'2021-01-01 00:00:01','abc');
Query OK, 1 row affected (0.00 sec)
mysql> select * from opr partition (p0);
+--------+---------------------+-------------+
| opr_no | opr_date | description |
+--------+---------------------+-------------+
| 1 | 2020-12-31 00:00:01 | abc |
+--------+---------------------+-------------+
1 row in set (0.00 sec)
mysql> select * from opr partition (p1);
+--------+---------------------+-------------+
| opr_no | opr_date | description |
+--------+---------------------+-------------+
| 1 | 2021-01-01 00:00:01 | abc |
+--------+---------------------+-------------+
1 row in set (0.00 sec)这实际上违背了业务对于 opr_no 的唯一性要求。
既然这样,有的童鞋会建议给opr_no 添加个唯一索引,But,现实是残酷的。
mysql> create unique index uk_opr_no on opr (opr_no);
ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning function (prefixed columns are not considered)即便是添加唯一索引,分区键也必须包含在唯一索引中。
总而言之,对于 MySQL 分区表,无法从数据库层面保证非分区列在表级别的唯一性,只能确保其在分区内的唯一性。
这也是 MySQL 分区表所为人诟病的地方之一。
但实际上,这个锅让 MySQL 背并不合适,对于 Oracle 索引组织表( InnoDB 即是索引组织表),同样也有这个限制。
Oracle 官方文档( http://docs.oracle.com/cd/E11882_01/server.112/e40540/schemaob.htm#CNCPT1514),在谈到索引组织表(Index-Organized Table,简称 IOT)的特性时,就明确提到了 “分区键必须是主键的一部分”。
Note the following characteristics of partitioned IOTs:
- Partition columns must be a subset of primary key columns.
- Secondary indexes can be partitioned locally and globally.
- OVERFLOW data segments are always equipartitioned with the table partitions.下面,我们看看刚开始的建表 SQL ,在 Oracle 中的执行效果。
SQL> CREATE TABLE opr_oracle (
opr_no NUMBER,
opr_date DATE,
description VARCHAR2(30),
PRIMARY KEY (opr_no)
)
ORGANIZATION INDEX
PARTITION BY RANGE (opr_date) (
PARTITION p0 VALUES LESS THAN (TO_DATE('20170713', 'yyyymmdd')),
PARTITION p1 VALUES LESS THAN (TO_DATE('20170714', 'yyyymmdd')),
PARTITION p2 VALUES LESS THAN (MAXVALUE)
);
PARTITION BY RANGE (opr_date) (
*
ERROR at line 8:
ORA-25199: partitioning key of a index-organized table must be a subset of the
primary key同样报错。
注意:这里指定了 ORGANIZATION INDEX ,创建的是索引组织表。
看来,分区键必须是主键的一部分并不是 MySQL 的限制,而是索引组织表的限制。
之所以对索引组织表有这样的限制,个人认为,还是基于性能考虑。
假设分区键和主键是两个不同的列,在进行插入操作时,虽然也指定了分区键,但还是需要扫描所有分区才能判断插入的主键值是否违反了唯一性约束。这样的话,效率会比较低下,违背了分区表的初衷。
而对于堆表则没有这样的限制。
在堆表中,主键和表中的数据是分开存储的,在判断插入的主键值是否违反唯一性约束时,只需利用到主键索引。
但与 MySQL 不一样的是,Oracle 实现了全局索引,所以针对上面的,同一个 opr_no,允许插入到不同分区中的问题,可通过全局唯一索引来规避。
SQL> CREATE TABLE opr_oracle (
opr_no NUMBER,
opr_date DATE,
description VARCHAR2(30),
PRIMARY KEY (opr_no, opr_date)
)
ORGANIZATION INDEX
PARTITION BY RANGE (opr_date) (
PARTITION p0 VALUES LESS THAN (TO_DATE('20170713', 'yyyymmdd')),
PARTITION p1 VALUES LESS THAN (TO_DATE('20170714', 'yyyymmdd')),
PARTITION p2 VALUES LESS THAN (MAXVALUE)
);
Table created.
SQL> create unique index uk_opr_no on opr_oracle (opr_no);
Index created.
SQL> insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh34:mi:ss'),'abc');
1 row created.
SQL> insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh34:mi:ss'),'abc');
insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh34:mi:ss'),'abc')
*
ERROR at line 1:
ORA-00001: unique constraint (SCOTT.SYS_IOT_TOP_87350) violated但 MySQL 却无能为力,之所以会这样,是因为 MySQL 分区表只实现了本地分区索引(Local Partitioned Index),而没有实现 Oracle 中的全局索引(Global Index)。
本地分区索引和全局索引的原理图如下所示:

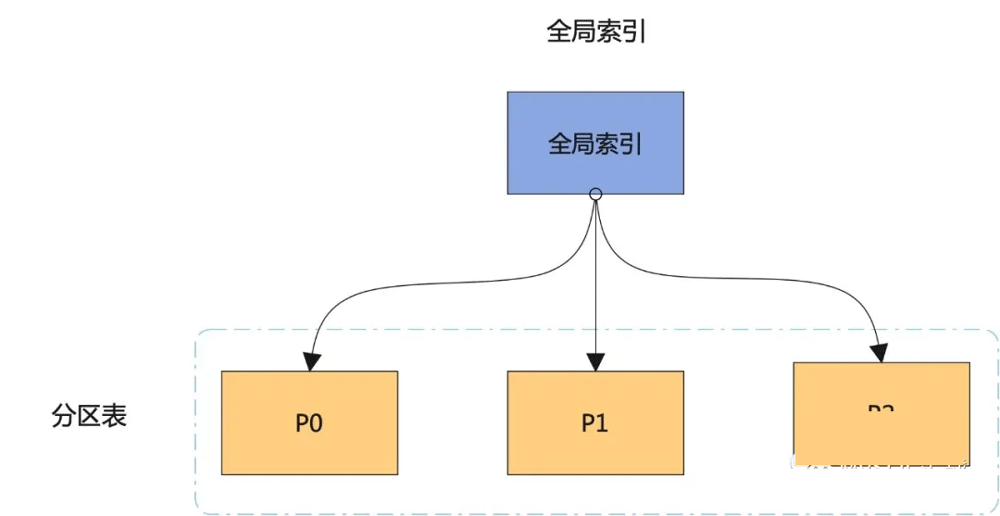
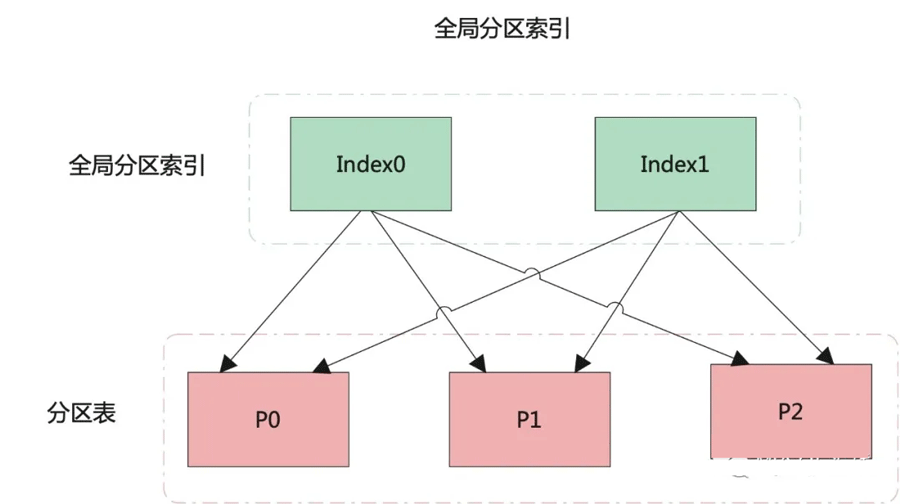
结合原理图,我们来看看两种索引之间的区别:
本地分区索引同时也是分区索引,分区索引和表分区之间是一一对应的。
而全局索引,既可以是分区的,也可以是不分区的。
如果是全局分区索引,一个分区索引可对应多个表分区,同样,一个表分区也可对应多个分区索引。
对本地分区索引的管理操作只会影响到单个分区,不会影响到其它分区。
而对全局分区索引的管理操作会造成整个索引的失效,当然,这一点可通过 UPDATE INDEXES 子句加以规避。
本地分区索引只能保证分区内的唯一性,无法保证表级别的唯一性,但全局分区可以。
在 Oracle 中,无论是索引组织表还是堆表,如果要创建本地唯一索引,同样也要求分区键必须是唯一键的一部分。
SQL> create unique index uk_opr_no_local on opr_oracle(opr_no) local;
create unique index uk_opr_no_local on opr_oracle(opr_no) local
*
ERROR at line 1:
ORA-14039: partitioning columns must form a subset of key columns of a UNIQUE
index关于“MySQL分区表中分区键必须是主键一部分的原因是什么”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“MySQL分区表中分区键必须是主键一部分的原因是什么”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



