这篇文章主要介绍Python中range、np.arange和np.linspace的区别是什么,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
range是python内置的一个类,该类型表示一个不可改变(immutable)的数字序列,常常用于在for循环中迭代一组特殊的数,它的原型可以近似表示如下:
class range(stop)
class range(start, stop, step=1)(注意,Python是不允许定义两个类初始化函数的,其实其CPython实现更像是传入不定长参数*args,然后根据len(args)来进行不同的拆分,但我们这里遵循Python文档风格写法)
如果只传入stop参数,那么我们就默认在[0, stop)区间以步长1进行迭代。如果传入2或3个参数,则我们会将在[start, stop)区间以step步长(可选,默认为1)迭代 。注意,三个参数必须全部为整数值。
它的常见使用样例如下:
print(list(range(10)))
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list(range(0, 30, 5)))
# [0, 5, 10, 15, 20, 25]当stop<=start时,而直接采用默认的step=1时,元素会为空:
print(list(range(0)))
# []
print(list(range(1, 0)))
# []此时的迭代我们需要将迭代步长设置为负:
print(list(range(0, -10, -1)))
# [0, -1, -2, -3, -4, -5, -6, -7, -8, -9]如果非法地传入非整数的参数,如:
print(list(range(10, 0.3)))则会报以下的TypeError:
'float' object cannot be interpreted as an integer
最后提一下,我们常常会写下如下代码:
for i in range(10):
print(i)此时Python解释器实质上会将range对象隐式转化为迭代器,等价于如下代码:
list_iterator = iter(range(10))
try:
while True:
x = next(list_iterator)
print(x)
except StopIteration:
passnumpy.arange是NumPy包的一个函数,它的功能与Python内置的range类似,它的原型可以近似表示为:
numpy.arange(stop, dtype=None, like=None)
numpy.arange(start, stop, step=1, dtype=None, like=None)(还是如前面所说,Python是不允许定义两个类初始化函数的,其实其CPython实现更像是传入不定长参数*args,然后根据len(args)来进行不同的拆分,但我们这里遵循Python文档风格写法)
其中start、step、step的使用与range类似,此处不再赘述,唯一的区别就是这3个参数都可以是小数。dtype为返回array的类型,如果没有给定则会从输入输入参数中推断。like为一个array-like的类型,它允许创建非NumPy arrays的arrays类型。
总结一下,该类与Python内置的range区别有两点:一是支持小数参数,二是返回ndarray类型而非像range那样常常做为(隐式转换为)list类型使用。
以下是其常见用例:
print(np.arange(3))
# [0 1 2]
print(np.arange(3.0))
# [0. 1. 2.]
print(np.arange(3,7))
# [3 4 5 6]
print(np.arange(3,7,2))
# [3 5]
print(np.arange(0, 5, 0.5))
#[0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5]注意,在numpy.arange的使用过程中可能存在浮点稳定性的问题,从而导致下面这样的意想不到的结果:
print(np.arange(0, 5, 0.5, dtype=int))
# [0 0 0 0 0 0 0 0 0 0]
print(np.arange(-3, 3, 0.5, dtype=int))
# [-3 -2 -1 0 1 2 3 4 5 6 7 8]这是因为在np.arange的内部实现中,实际上的step值是按照公式dtype(start+step)-dtype(start)来计算的,而非直接采用step。当进行强制类型转换(上面例子中转为int,即朝0方向取整)或start远远比step大时,会出现精度的损失。在这种情况下,建议使用下面提到的np.linspace:
numpy.linspace也是Numpy内置的一个函数,它和numpy.arange类似,但是它不再是简单的[start, stop)左闭右开,也没有使用步长step,而是使用样本个数num。其函数原型如下:
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)其中当endpoint采用默认的True时,start和stop表示序列的开始和初始值(闭区间[start, stop]),num为区间[start, stop]按照均匀(evenly)划分采样的样本数(包括边界start和stop在内)。不过需要注意的是,endpoint为True时stop才能做为最后一个样本,为False时区间内便不包括stop,此时会在区间[start,end]内按照总个数为num + 1个样本采样并去掉尾部样本(即stop点)组成。retstep位置为True则会返回(samples, step)元组,其中samples为生成的样本,step为样本之间的间隔步长。
注意,它的start、stop参数都可以为小数,但是当dtype设置为int时则就不能为小数。
numpy.linspace的常见使用样例如下:
print(np.linspace(2.0, 3.0, num=5))
# array([2. , 2.25, 2.5 , 2.75, 3. ])如果设置endpoint为True,则按照num+1个样本数量来采样,并去掉最后一个样本。
print(np.linspace(2.0, 3.0, num=5, endpoint=False))
# [2. 2.2 2.4 2.6 2.8]如果retstep设置为True,则除了返回生成的样本,还会返回样本之间的间隔步长。
print(np.linspace(2.0, 3.0, num=5, retstep=True))
# (array([2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)下面我们用图形形象化地描述endpoint取True和取False的区别:
import matplotlib.pyplot as plt
N = 8
y = np.zeros(N)
x1 = np.linspace(0, 10, N, endpoint=True)
x2 = np.linspace(0, 10, N, endpoint=False)
plt.plot(x1, y, 'o', color='orange')
plt.plot(x2, y + 0.5, 'o', color='blue')
plt.ylim([1, -0.5])
plt.show()图像显示如下:
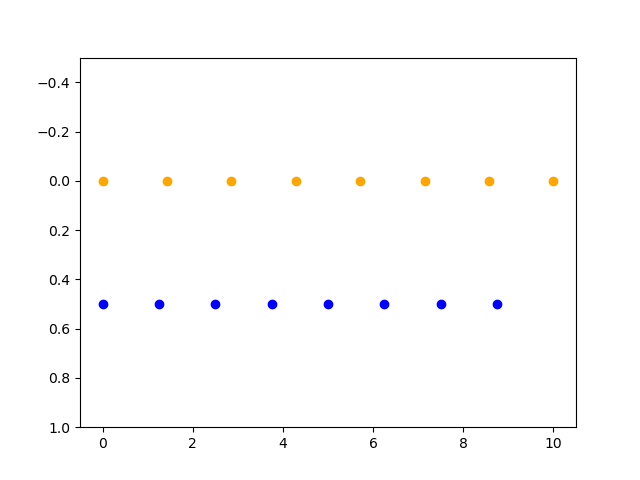
可以看出橘色的点为np.linspace(0, 10, N, endpoint=True),按照总共8个点在[0, 10]采样,并包括stop边界10。蓝色的点为np.linspace(0, 10, N, endpoint=False),先按照总共9个点在[0, 10]采样最后再去掉最后一个点(即stop点10),最终得到间隙更密的8个点。
以上是“Python中range、np.arange和np.linspace的区别是什么”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



