pythonж•°жҚ®еӨ„зҗҶе®һдҫӢеҲҶжһҗ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢpythonж•°жҚ®еӨ„зҗҶе®һдҫӢеҲҶжһҗзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
дёҖпјҢеүҚиЁҖ
жҲ‘们зҺ°еңЁжӢҝеҲ°дәҶдёҖдёӘеҚҒеҲҶеәһеӨ§зҡ„ж•°жҚ®йӣҶгҖӮжҳҜjsonж–Ү件пјҢйҮҢйқўеӯҳеӮЁдәҶе°Ҷиҝ‘еҚҒдёҮдёӘж•°жҚ®пјҢзҺ°еңЁиҰҒеҜ№е…¶дёӯзҡ„ж•°жҚ®иҝӣиЎҢжё…жҙ—еӨ„зҗҶгҖӮ
дәҢпјҢpythonжЁЎеқ—
import json
import jieba
жҲ‘们йңҖиҰҒз”ЁjsonжЁЎеқ—жқҘеӨ„зҗҶjsonж–Ү件пјҢе’ҢдҪҝз”Ёjiebaеә“жқҘеҲҶжһҗиҜҚжҖ§пјҢиҝҷж ·еҸҜд»Ҙе®һзҺ°жҲ‘们зҡ„йңҖжұӮгҖӮ
2.1пјҢеўһеҠ еҒңз”ЁиҜҚиЎЁ
еҒңз”ЁиҜҚиЎЁ.txtпјҢжҠҠеҒңз”ЁиҜҚиЎЁеӯҳе…ҘstopwordsпјҢеҺҹеӣ жҳҜпјҡжҲ‘们зҡ„зӣ®ж ҮеҲҶжһҗjsonйҮҢжңүдёҖдәӣж ҮзӮ№з¬ҰеҸ·гҖӮ
stopwords = [line.strip() for line in open("еҒңз”ЁиҜҚиЎЁ.txt",encoding="utf-8").readlines()]еҹәжң¬еҰӮеӣҫжүҖзӨәпјҡ

a+str(b)+cиҝҷжҳҜж–Ү件еҗҚз§°пјҢa+b+c=./json/poet.song.0.json bйҖ’еўһпјҢе®һзҺ°еҠЁжҖҒеҸ–еҖј
with open(a+str(b)+c,'r',encoding='utf8')as fp:
еӣ дёәжңүе°Ҷиҝ‘500дёӘjsonж–Ү件гҖӮжҜҸдёӘж–Ү件йҮҢжңүеҘҪеҮ еҚғз»„ж•°жҚ®пјҢжҲ‘зҺ°еңЁе°ҪеҠӣзҡ„дјҳеҢ–д»Јз ҒпјҢзҺ°еңЁжҸҗеҸ–дёҖж¬ЎпјҢжҠҠйңҖиҰҒзҡ„ж•°жҚ®еӯҳе…Ҙж–Ү件йҮҢйқўе·®дёҚеӨҡйңҖиҰҒдә”еҲҶй’ҹгҖӮ
2.2пјҢйЎәеәҸиҜ»еҸ–
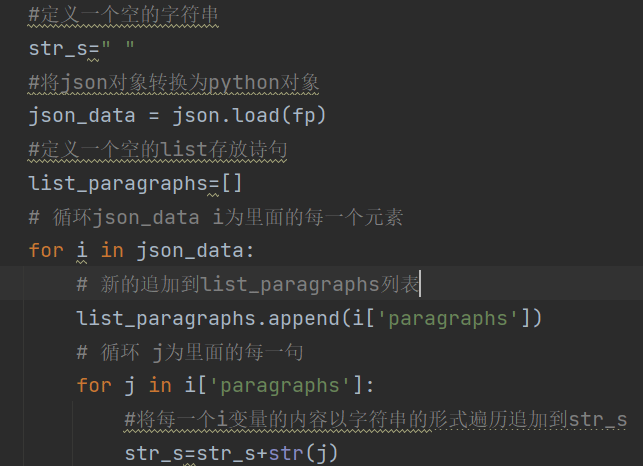
е®ҡд№үдёҖдёӘз©әзҡ„еӯ—з¬ҰдёІпјҢе°ҶjsonеҜ№иұЎиҪ¬жҚўдёәpythonеҜ№иұЎгҖӮе®ҡд№үдёҖдёӘз©әзҡ„listеӯҳж”ҫиҜ—еҸҘгҖӮ
еҫӘзҺҜjson_data iдёәйҮҢйқўзҡ„жҜҸдёҖдёӘе…ғзҙ гҖӮ
ж–°зҡ„иҝҪеҠ еҲ°list_paragraphsеҲ—иЎЁ
еҫӘзҺҜ jдёәйҮҢйқўзҡ„жҜҸдёҖеҸҘгҖӮ
д»Јз ҒеҰӮеӣҫжүҖзӨәпјҡ
дҪҝз”Ёjiebaеә“пјҢеҲҶжһҗstrеҶ…е®№зҡ„иҜҚжҖ§гҖҗжіЁж„ҸжҳҜеҗҚз§°пјҢеҠЁиҜҚгҖӮгҖӮгҖӮгҖӮгҖ‘жҺ’иЎҢиҫ“еҮәйғҪжҳҜдҝ©дёӘеӯ—жҳҜе·§еҗҲпјҢжІЎжңүеӯ—ж•°йҷҗеҲ¶
words = jieba.lcut(str_s)
зҺ°еңЁwordsдёәеҲҶжһҗе®ҢжҜ•зҡ„иҜҚжҖ§еҲ—иЎЁпјҢйҒҚеҺҶгҖӮ
жҺ’йҷӨзү№ж®Ҡз¬ҰеҸ·
for word in words:
if word not in stopwords:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
еҮәзҺ°йў‘зҺҮеҠ дёҖгҖӮ
2.3пјҢlambdaеҮҪж•°
дҪҝз”ЁlambdaеҮҪж•°пјҢsortеҝ«йҖҹжҺ’еәҸпјҢйҒҚеҺҶиҫ“еҮәйў‘зҺҮеүҚ50зҡ„иҜҚжҖ§гҖӮ
items.sort(key=lambda x:x[1], reverse=True)
д№ӢеҗҺиөӢеҖјword, countгҖӮ
word, count = items[i]
print ("{:<10}{:>7}".format(word, count))дёүпјҢиҝҗиЎҢ
3.1пјҢеӯҳе…Ҙж–Ү件
f=open('towa.txt',"a",encoding='gb18030')
f.writelines("йўҳзӣ®:"+textxxx)
f.writelines(word_ping)
д»ҘдёҠе°ұжҳҜвҖңpythonж•°жҚ®еӨ„зҗҶе®һдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





