这篇文章主要介绍“微信小程序前端怎么调用python后端的模型”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“微信小程序前端怎么调用python后端的模型”文章能帮助大家解决问题。
小程序端拍照调用python训练好的图片分类模型。实现图片分类识别的功能。
重点在chooseImage函数中,根据图片路径获取到图片传递给flask的url;
Page({
data: {
SHOW_TOP: true,
canRecordStart: false,
},
data: {
tempFilePaths:'',
sourceType: ['camera', 'album']
},
isSpeaking: false,
accessToken: "",
onLoad: function (options) {
console.log("onLoad!");
this.setHeader();
var that=this
wx.showShareMenu({
withShareTicket: true //要求小程序返回分享目标信息
});
var isShowed = wx.getStorageSync("tip");
if (isShowed != 1) {
setTimeout(() => {
this.setData({
SHOW_TOP: false
})
wx.setStorageSync("tip", 1)
}, 3 * 1000)
} else {
this.setData({
SHOW_TOP: false
})
};
},
},
//头像点击处理事件,使用wx.showActionSheet()调用菜单栏
buttonclick: function () {
const that = this
wx.showActionSheet({
itemList: ['拍照', '相册'],
itemColor: '',
//成功时回调
success: function (res) {
if (!res.cancel) {
/*
res.tapIndex返回用户点击的按钮序号,从上到下的顺序,从0开始
比如用户点击本例中的拍照就返回0,相册就返回1
我们res.tapIndex的值传给chooseImage()
*/
that.chooseImage(res.tapIndex)
}
},
setHeader(){
const tempFilePaths = wx.getStorageSync('tempFilePaths');
if (tempFilePaths) {
this.setData({
tempFilePaths: tempFilePaths
})
} else {
this.setData({
tempFilePaths: '/images/camera.png'
})
}
},
chooseImage(tapIndex) {
const checkeddata = true
const that = this
wx.chooseImage({
//count表示一次可以选择多少照片
count: 1,
//sizeType所选的图片的尺寸,original原图,compressed压缩图
sizeType: ['original', 'compressed'],
//如果sourceType为camera则调用摄像头,为album时调用相册
sourceType: [that.data.sourceType[tapIndex]],
success(res) {
// tempFilePath可以作为img标签的src属性显示图片
console.log(res);
const tempFilePaths = res.tempFilePaths
//将选择到的图片缓存到本地storage中
wx.setStorageSync('tempFilePaths', tempFilePaths)
/*
由于在我们选择图片后图片只是保存到storage中,所以我们需要调用一次 setHeader()方法来使页面上的头像更新
*/
that.setHeader();
// wx.showToast({
// title: '设置成功',
// icon: 'none',
// // duration: 2000
// })
wx.showLoading({
title: '识别中...',
})
var team_image = wx.getFileSystemManager().readFileSync(res.tempFilePaths[0], "base64")
wx.request({
url: 'http://127.0.0.1:5000/upload', //API地址,upload是我给路由起的名字,参照下面的python代码
method: "POST",
header: {
'content-type': "application/x-www-form-urlencoded",
},
data: {image: team_image},//将数据传给后端
success: function (res) {
console.log(res.data); //控制台输出返回数据
wx.hideLoading()
wx.showModal({
title: '识别结果',
confirmText: "识别正确",
cancelText:"识别错误",
content: res.data,
success: function(res) {
if (res.confirm) {
console.log('识别正确')
} else if (res.cancel) {
console.log('重新识别')
}
}
})
}
})
}
})
},
});将图片裁剪,填充,调用自己训练保存最优的模型,用softmax处理结果矩阵,最后得到预测种类
# coding=utf-8
from flask import Flask, render_template, request, jsonify
from werkzeug.utils import secure_filename
from datetime import timedelta
from flask import Flask, render_template, request
import torchvision.transforms as transforms
from PIL import Image
from torchvision import models
import os
import torch
import json
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
import base64
app = Flask(__name__)
def softmax(x):
exp_x = np.exp(x)
softmax_x = exp_x / np.sum(exp_x, 0)
return softmax_x
with open('dir_label.txt', 'r', encoding='utf-8') as f:
labels = f.readlines()
print("oldlabels:",labels)
labels = list(map(lambda x: x.strip().split('\t'), labels))
print("newlabels:",labels)
def padding_black(img):
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
# 输出
@app.route('/')
def hello_world():
return 'Hello World!'
# 设置允许的文件格式
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'JPG', 'PNG', 'bmp'])
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
# 设置静态文件缓存过期时间
app.send_file_max_age_default = timedelta(seconds=1)
# 添加路由
@app.route('/upload', methods=['POST', 'GET'])
def upload():
if request.method == 'POST':
# 通过file标签获取文件
team_image = base64.b64decode(request.form.get("image")) # 队base64进行解码还原。
with open("static/111111.jpg", "wb") as f:
f.write(team_image)
image = Image.open("static/111111.jpg")
# image = Image.open('laji.jpg')
image = image.convert('RGB')
image = padding_black(image)
transform1 = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
])
image = transform1(image)
image = image.unsqueeze(0)
# image = torch.unsqueeze(image, dim=0).float()
print(image.shape)
model = models.resnet50(pretrained=False)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, 214)
# model = model.cuda()
# 加载训练好的模型
checkpoint = torch.load('model_best_checkpoint_resnet50.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
model.eval()
src = image.numpy()
src = src.reshape(3, 224, 224)
src = np.transpose(src, (1, 2, 0))
# image = image.cuda()
# label = label.cuda()
pred = model(image)
pred = pred.data.cpu().numpy()[0]
score = softmax(pred)
pred_id = np.argmax(score)
plt.imshow(src)
print('预测结果:', labels[pred_id][0])
# return labels[pred_id][0];
return json.dumps(labels[pred_id][0], ensure_ascii=False)//将预测结果传回给前端
# plt.show()
# return render_template('upload_ok.html')
# 重新返回上传界面
# return render_template('upload.html')
if __name__ == '__main__':
app.run(debug=False)大致的效果:
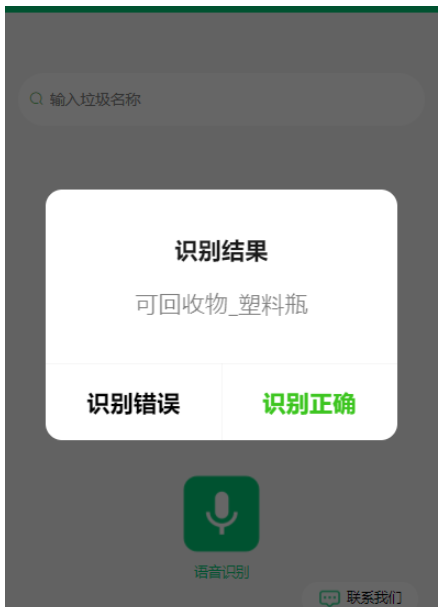

关于“微信小程序前端怎么调用python后端的模型”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



