这篇文章主要讲解了“Python怎么实现Word转PDF”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python怎么实现Word转PDF”吧!
pdfkit 包的安装:
pip install pdfkit
依赖工具:
下载符合与自己当前系统的安装包安装完成之后就可以达到兼容的效果了。
html 转 pdf 方法:
pdfkit.from_file(html文件, 保存路径) 利用 pdfkit.from_file() 函数传入 "html" 文件与 pdf 的保存路径
代码示例如下:
# coding:utf-8
import pdfkit # 需安装 pdfkit 第三方包 "pip install pdfkit" 以及第三方依赖 "wkhtmltopdf"
pdfkit.from_file('html测试文件.html', 'html测试文件.pdf')运行结果如下:
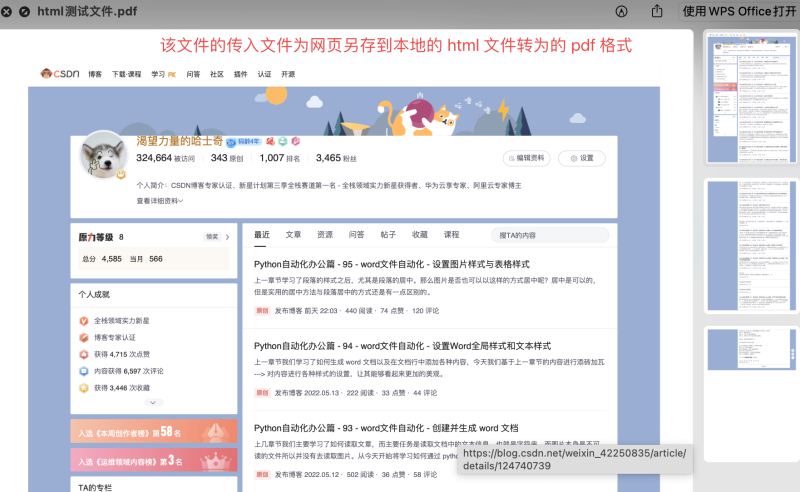
网址 转 pdf 方法:
pdfkit.from_url(网址, 保存路径) 利用 pdfkit.from_url() 函数传入 "网址" 文件与 pdf 的保存路径
“html” 文件与网址的区别在于实际上html文件有可能是我们本地开发生成的,也有可能是通过 “网页另存为” 的方式存储在本地的。所以 网址 与 html文件 还是有一点点区别的,但是它们的本质其实是一样的。
代码示例如下:
# coding:utf-8
import pdfkit # 需安装 pdfkit 第三方包 "pip install pdfkit" 以及第三方依赖 "wkhtmltopdf"
pdfkit.from_url('https://www.163.com', 'test1.pdf')运行结果如下:
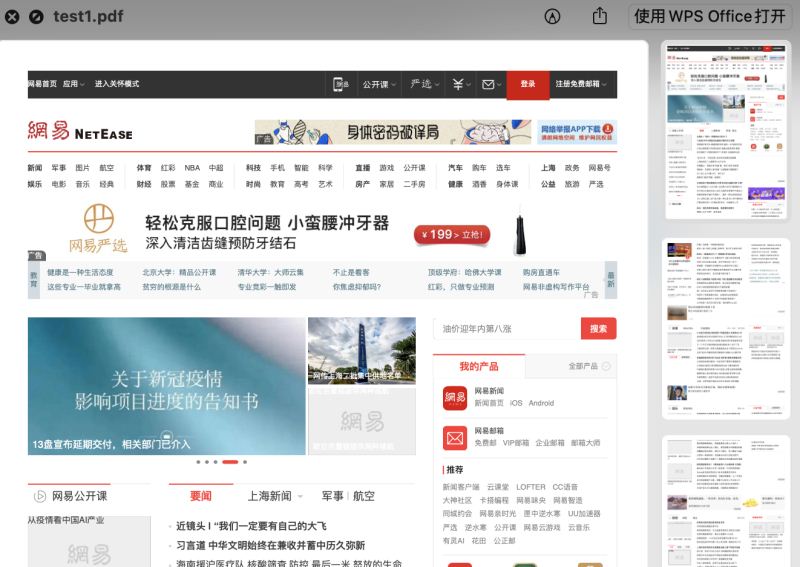
网址 转 pdf 方法:
pdfkit.from_string(基于html的字符串, 保存路径) 利用 pdfkit.from_string() 函数传入 "网址" 文件与 pdf 的保存路径
基于html的字符串 其实就是前端的一种超文本文件格式,以这种前端规范生成的字符串其实就是 html 的字符串了
# coding:utf-8 import pdfkit # 需安装 pdfkit 第三方包 "pip install pdfkit" 以及第三方依赖 "wkhtmltopdf" html = """ <html> <head> <meta charset="utf-8" /> </head> <body> <p>你好,这是一个html字符串转为pdf的测试文件</p> </body> </html> """ pdfkit.from_string(html, 'html_string_test.pdf')
运行结果如下:
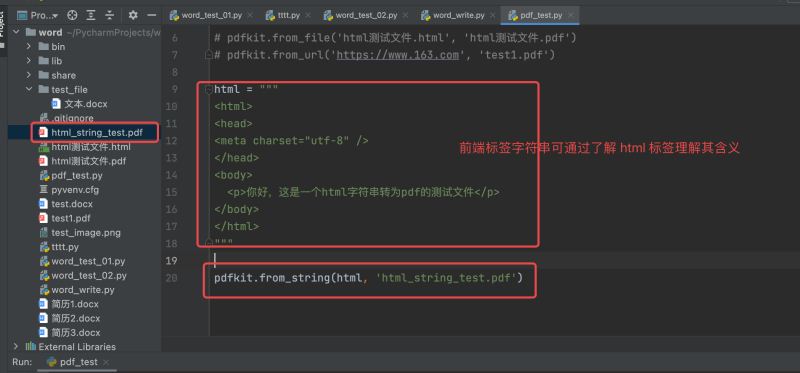
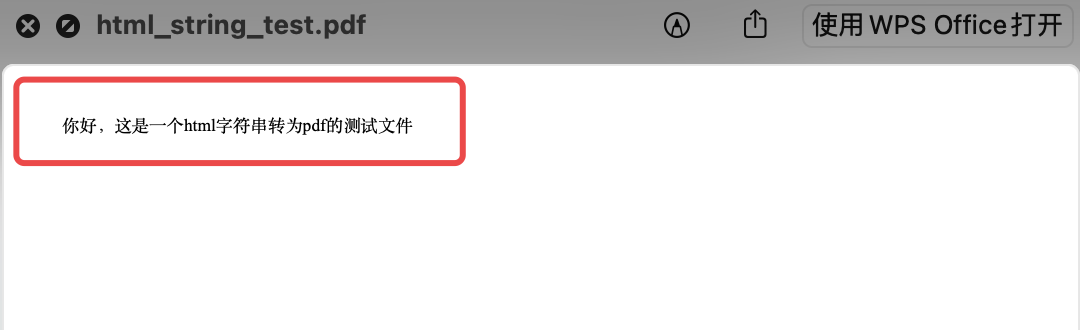
首先需要安装 pydocx 依赖包 —> pip install pydocx
导入 PyDocX 函数 —> from pydocx import PyDocX
利用 PyDocX 将 word 文件转换为 html 格式(会生成一个 html 的字符串对象)
将 生成的 html 字符串 写入到一个 html 文件中
然后利用 pdfkit 包的 pdfkit.from_file() 函数将其转为 pdf 文件
代码示例如下:
# coding:utf-8
import pdfkit # pip install pdfkit
from pydocx import PyDocX # pip install pydocx
html = PyDocX.to_html('简历1.docx')
f = open('简历1.html', 'w')
f.write(html)
f.close()
#pdfkit.from_file('html1.html', 'test3.pdf')
pdfkit.from_string(html, '简历1.pdf')运行结果如下:
感谢各位的阅读,以上就是“Python怎么实现Word转PDF”的内容了,经过本文的学习后,相信大家对Python怎么实现Word转PDF这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





