这篇文章主要介绍“Python数据分析之Pandas Dataframe怎么合并和去重”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Python数据分析之Pandas Dataframe怎么合并和去重”文章能帮助大家解决问题。
Pandas 提供了merge()方法来进行合并操作,使用语法如下:
pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False)常用的参数说明:
left、right:指定左右两个要进行合并的 DataFrame 对象
how:指定合并类型,可以选择left、right、outer、inner,此参数可以确定以哪边(左边、右边或者左右共有)的键为基准,如果出现匹配失败的用NaN填充,默认为inner,具体如下:
left:代表左连接,以左DataFrame为基准,右侧匹配失败的用NaN填充
right:代表右连接,以右DataFrame为基准,左侧匹配失败的用NaN填充
inner:代表内连接,取交集
outer:代表外连接,取并集,匹配失败的用NaN填充
on:指定用于连接的键,也就是列名,传递改参数的话,必须保证传递的“键”在左右两边的DataFrame中都存在
left_on:指定左侧DataFrame中用于连接的键
right_on:指定右侧DataFrame中用于连接的键
left_index & right_index:表示以行索引作为合并基准,默认为False
sort:指定是否按照字典顺序通过连接键对结果DataFrame进行排序,默认为False
例如,对下面两个 DataFrame 对象执行合并操作:
import pandas as pd
data = {"name": ["Alice", "Bob", "Cindy", "David"], "age": [25, 23, 28, 24], "gender": ["woman", "man", "woman", "man"]}
df1 = pd.DataFrame(data)
df1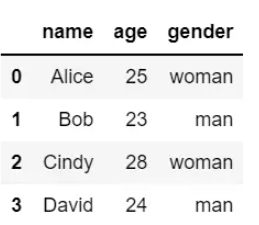
data = {"name": ["Alice", "Bob", "Cindy", "Emilie"], "city": ["beijing", "beijing", "jinan", "shanghai"]}
df2 = pd.DataFrame(data)
df2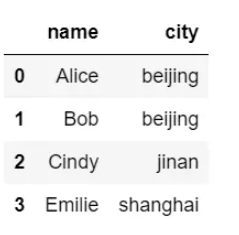
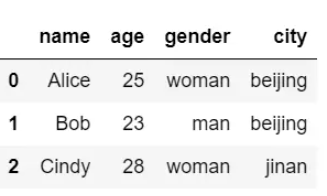
使用name作为连接键:
merge_pd = pd.merge(df1, df2, on="name")
merge_pd结果输出如下:
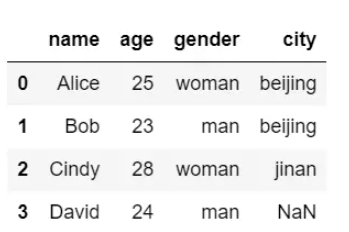
设置为左连接:
merge_pd = pd.merge(df1, df2, on="name", how="left")
merge_pd结果输出如下:
在进行数据分析时,数据的质量可能并不理想,有可能包含一些重复数据,那我们就要进行数据的“去重”操作,删除重复的数据,保留唯一的数据项,从而提高数据集整体的精确度,同时也可以节省空间、提升读写性能等,接下来就来介绍一下 Pandas Dataframe 的去重操作。
Pandas 提供了drop_duplicates()方法进行数据的去重操作,具体使用格式如下:
df.drop_duplicates(subset=None, keep="first", inplace=False, ignore_index=False)参数说明如下:
subset:指定要进行去重的列名,默认为None,可以使用列表指定一个或多个列名
keep:有三个参数可选:first、last、False,默认为first,表示只保留第一次出现的重复项,删除其余重复项;last表示只保留最后一次出现的重复项;False表示删除所有重复项
inplace:是否在原Dataframe对象上进行操作
ignore_index:默认为False,设置为True可以重新生成行索引。
例如,对下面 DataFrame 对象进行去重操作:
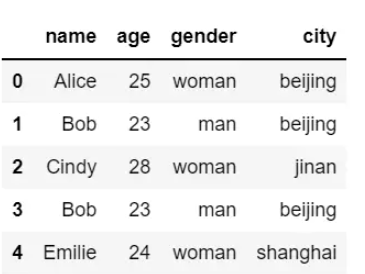
可以看到该DataFrame 对象中索引为1、3的行是重复的,下面进行去除:
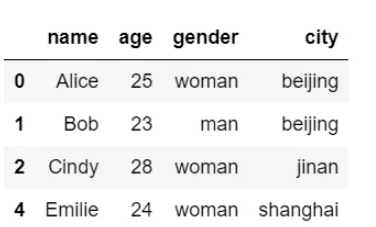
保留第一次出现的重复项:
df.drop_duplicates(inplace=True)
df结果输出如下:
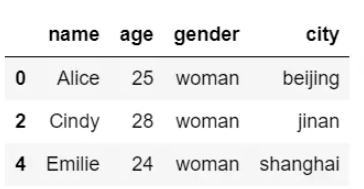
删除所有重复项:
df.drop_duplicates(keep=False, inplace=True)
df结果输出如下:
ignore_index参数使用:
df.drop_duplicates(inplace=True, ignore_index=True)
df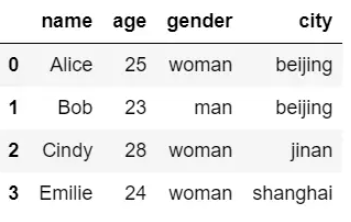
ignore_index设置为True后,通过结果可以看到,行索引进行了重排。
当然drop_duplicates()方法也可以根据指定列名去重,给subset传递参数即可,例如根据name列进行去重:
df.drop_duplicates(subset=["name"], inplace=True)关于“Python数据分析之Pandas Dataframe怎么合并和去重”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



