本篇内容介绍了“Python中的Selenium异常处理实例分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
在进行爬虫爬取淘宝商品信息时候,利用selenium来模拟浏览器进行爬取时遇到了这个问题:
selenium.common.exception.WebDriverException:Message:'chromedriver' executable needs to be in Path
详细如下图所示:

这一错误是因为没有配置好chromedriver,怎么配置呢?(我用的是chrome)
1.打开chrome 输入 “chrome://version/”来查看chrome版本 如图我的是63

2.访问此网站 http://chromedriver.storage.googleapis.com/index.html 然后选择合适版本的driver
比如
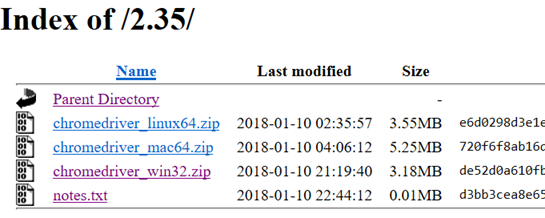
点击notes.txt就可查看其对应的版本号,如下:
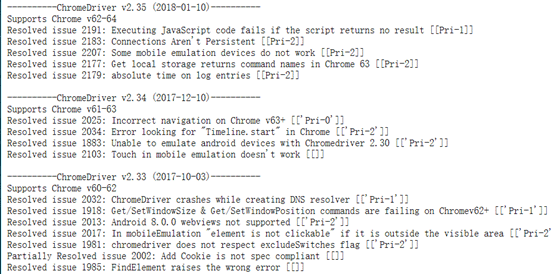
如果符合就可以下载了,下载到自己指定位置然后就可以进行配置了
3. 配置如下:

(具体路径根据自己下载保存的位置而定)
4.这时候运行基本就可以成功了!
不过很不幸,我第一次瞎下的driver版本不对,所以就GG了抛出了如下错误 ConnectionResetError:主机强迫关闭了一个现有连接

于是乎重新下了一个匹配的driver版本然后ok了
“Python中的Selenium异常处理实例分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



