今天小编给大家分享一下Python字符串,列表,字典和集合实例处理分析的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
统计序列中元素出现的频率的结果肯定是一个字典,Key 为序列中的元素而 Value 为元素出现的次数,因此可以先创建一个字典,作为初始的统计结果,并假设初始出现的次数都为0。
对频率结果字典的 Value 进行排序
from random import randint
# 生成包含重复元素的随机序列
nums = [randint(0, 10) for num in range(20)]
# 元素出现次数的统计最终肯定是一个字典,因此可以以元素的Key,出现的次数为Value
count = dict.fromkeys(nums, 0)
# 统计频次
for num in nums:
count[num] += 1
# 排序方案一
# 根据Value进行排序
_count = sorted(count.values())
# 获取最大的次数
max = _count.pop()
keys = []
# 根据Value获取Key
for k, v in count.items():
if v == max:
keys.append(k)
if __name__ == '__main__':
print(nums)
print(count)
print(_count)
print(max)
print(keys)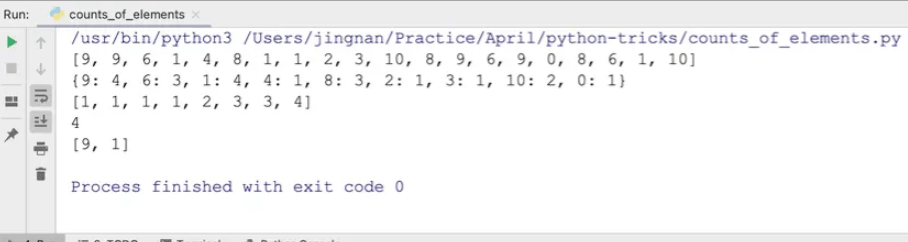
出现的最大频次为4,且频次为4的元素是9和1
使用 Counter 对象进行排序
# 排序方案二
from collections import Counter
_count = Counter(count)
# 中间代码不变
if __name__ == '__main__':
print(nums)
print(count)
print(_count)
print(_count.most_common())
# 获取出现频次最高的三个元素
print(_count.most_common(3))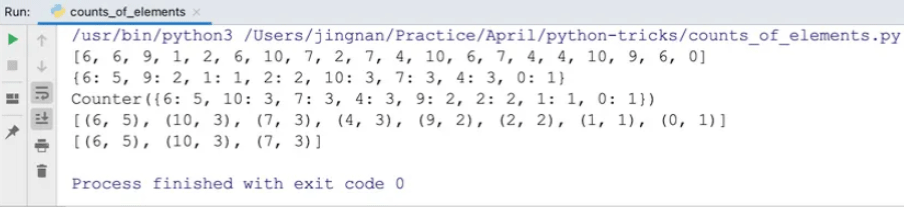
import re
from collections import Counter
zen = open('zen.txt').read()
# 分割所有单词
zen = re.split('\W+', zen)
# print(zen)
_zen = Counter(zen)
print(_zen)
_zen_3 = _zen.most_common(3)
print('前三个出现频次最高的词:', _zen_3)
以上就是“Python字符串,列表,字典和集合实例处理分析”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



