这篇文章主要介绍了Pandas数据透视的函数如何使用的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Pandas数据透视的函数如何使用文章都会有所收获,下面我们一起来看看吧。
melt函数的主要作用是将DataFrame从宽格式转换成长格式。
“pandas.melt(frame,id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
”
参数含义
id_vars:tuple, list, or ndarray,可选,作为标识符变量的列
value_vars:tuple, list, or ndarray, 可选,透视列,如果未指定,则使用未设置为id_vars的所有列。
var_name:scalar,默认为None,使用variable作为列名
value_name:标量, default ‘value’,value列的名称
col_level:int or str, 可选,如果列是多层索引,melt将应用于指定级别
ignore_index:bool, 默认为True,相当于从0开始重新排序。如果为False,则保留原来的索引,索引标签将出现重复。
看个例子先:
import pandas as pd
df = pd.DataFrame(
{'地区': ['A', 'B', 'C'],
'2020': [80, 60, 40],
'2021': [800, 600, 400],
'2022': [8000, 6000, 4000]})
pd.melt(df, id_vars=['地区'], value_vars=['2020', '2021', '2022'])
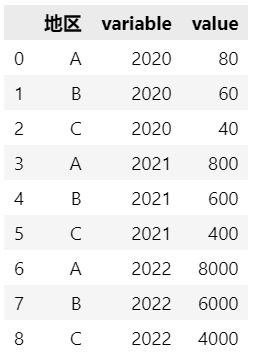
设置var_name与value_name。
df = pd.melt(df, id_vars=['地区'], value_vars=['2020', '2021', '2022'], var_name='年份', value_name='销售额')
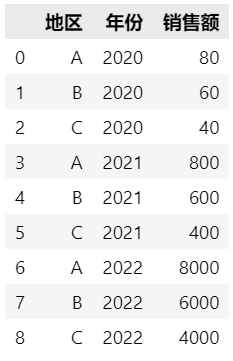
pivot函数主要用于通过索引及列值对DataFrame重构。
“pandas.pivot(data, index=None, columns=None, values=None)
”
参数含义
data:DataFrame对象
index:可选,用于新DataFrame的索引
columns:用于创建新DataFrame的列
values:可选,用于填充新DataFrame的值
用上面的结果举个例子:
df.pivot(index='年份', columns='地区', values='销售额')
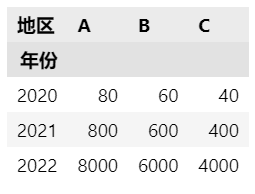
也可以写成以下格式。
df.pivot(index='年份', columns='地区')['销售额']
添加一个销量列,同时统计两个values,这样会使columns变成多层索引。
df['销量'] = df['销售额']/10 df.pivot(index='年份', columns='地区', values=['销售额', '销量'])
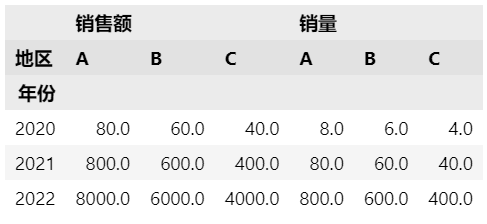
添加一个月份列,指定两个index。
df['月份'] = [f'{m}月' for m in range(1, 4)]*3
df.pivot(index=['年份', '月份'],
columns='地区',
values='销售额')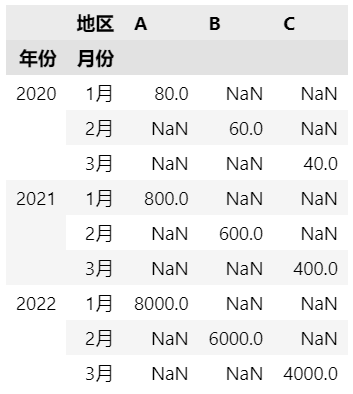
使用pivot时需要注意,当index,columns出现重复时,会导致ValueError。
df = pd.DataFrame(
{'地区': ['A', 'A', 'B', 'C'],
'年份': ['2020', '2020', '2021', '2022'],
'销售额': [800, 600, 400, 200]})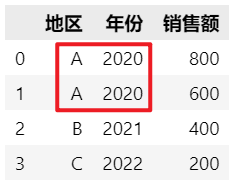
df.pivot(index='地区', columns='年份', values='销售额') # ValueError
这个函数之前已经单独讲过了,详见Pandas玩转数据透视表,相比于pivot,pivot_table的灵活性更强。
crosstab函数计算两个(或多个)数组的简单交叉表。默认情况下计算元素的频率表。
“pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False)
”
看下例子:
这里默认计算频率。
import numpy as np array_A = np.array(["one", "two", "two", "three", "three", "three"], dtype=object) array_B = np.array(["Python", "Python", "Python", "C", "C", "C"], dtype=object) array_C = np.array(["Y", "Y", "Y", "N", "N", "N"]) pd.crosstab(array_A, [array_B, array_C], rownames=['array_A'], colnames=['array_B', 'array_C'])

新建一个values列,计算总和。
array_D = np.array([1, 4, 9, 16, 25, 36]) pd.crosstab(index=array_A, columns=[array_B, array_C], rownames=['array_A'], colnames=['array_B', 'array_C'], values=array_D, aggfunc='sum')

关于“Pandas数据透视的函数如何使用”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Pandas数据透视的函数如何使用”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





