这篇文章主要介绍“SpringBoot怎么使用Caffeine实现缓存”,在日常操作中,相信很多人在SpringBoot怎么使用Caffeine实现缓存问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”SpringBoot怎么使用Caffeine实现缓存”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
在深入探讨如何向应用程序添加缓存之前,首先想到的问题是为什么我们需要在应用程序中使用缓存。
假设有一个包含客户数据的应用程序,用户发出两个请求来获取客户的数据(id=100)。
这就是没有缓存时的情况。
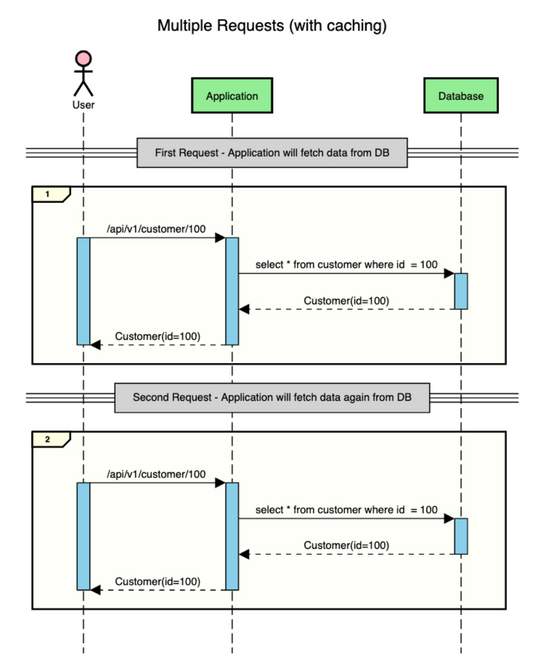
如您所见,对于每个请求,应用程序都会转到数据库获取数据。从数据库获取数据是一项成本高昂的操作,因为它涉及IO。
但是,如果中间有一个缓存存储,可以在其中临时存储短时间的数据,则可以将这些往返保存到数据库并在IO时间保存。
这就是使用缓存时上述交互的样子。
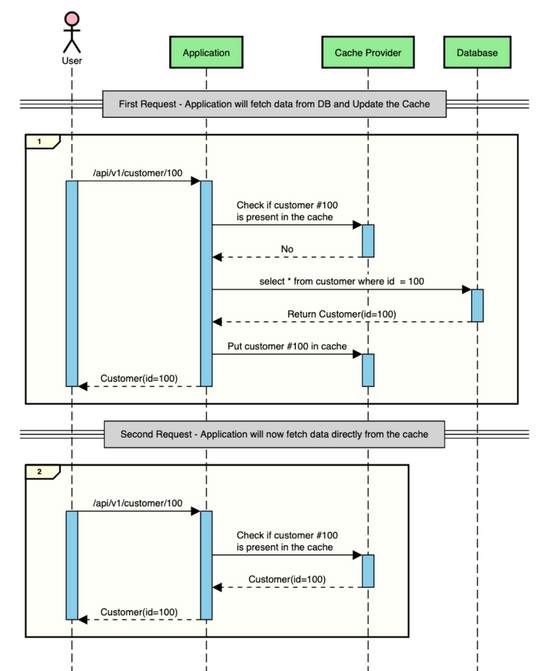
SpringBoot只提供了一个缓存抽象,您可以使用它将缓存透明、轻松地添加到Spring应用程序中。
它不提供实际的缓存存储。
但是,它可以与不同类型的缓存提供程序一起工作,如Ehcache、Hazelcast、Redis、Caffee等。
SpringBoot的缓存抽象可以添加到方法中(使用注释)
基本上,在执行方法之前,Spring框架将检查方法数据是否已经缓存
如果是,则它将从缓存中获取数据。
否则它将执行该方法并缓存数据
它还提供了从缓存中更新或删除数据的抽象。
在我们当前的博客中,我们将了解如何使用Caffeine添加缓存,Caffeine是一种基于Java8的高性能、接近最优的缓存库。
您可以在 application.yaml 文件中指定使用哪个缓存提供程序来设置 spring.cache.type 属性。
但是,如果没有提供属性,Spring将根据添加的库自动检测缓存提供程序。
现在假设您已经启动并运行了基本的Spring boot应用程序,让我们添加缓存依赖项。
打开 build.gradle 文件,并添加以下依赖项以启用Spring Boot的缓存
compile('org.springframework.boot:spring-boot-starter-cache')接下来我们将添加对Caffeine的依赖
compile group: 'com.github.ben-manes.caffeine', name: 'caffeine', version: '2.8.5'
现在我们需要在Spring Boot应用程序中启用缓存。
为此,我们需要创建一个配置类并提供注释 @EnableCaching 。
@Configuration
@EnableCaching
public class CacheConfig {
}现在这个类是一个空类,但是我们可以向它添加更多配置(如果需要)。
现在我们已经启用了缓存,让我们提供缓存名称和缓存属性的配置,如缓存大小、缓存过期时间等
最简单的方法是在 application.yaml 中添加配置
spring: cache: cache-names: customers, users, roles caffeine: spec: maximumSize=500, expireAfterAccess=60s
上述配置执行以下操作
将可用缓存名称限制为客户、用户和角色。将最大缓存大小设置为500。
当缓存中的对象数达到此限制时,将根据缓存逐出策略从缓存中删除对象。将缓存过期时间设置为1分钟。
这意味着项目将在添加到缓存1分钟后从缓存中删除。
还有另一种配置缓存的方法,而不是在 application.yaml 文件中配置缓存。
您可以在缓存配置类中添加并提供一个 CacheManager Bean,该Bean可以完成与上面在 application.yaml 中的配置完全相同的工作
@Bean
public CacheManager cacheManager() {
Caffeine<Object, Object> caffeineCacheBuilder =
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterAccess(
1, TimeUnit.MINUTES);
CaffeineCacheManager cacheManager =
new CaffeineCacheManager(
"customers", "roles", "users");
cacheManager.setCaffeine(caffeineCacheBuilder);
return cacheManager;
}在我们的代码示例中,我们将使用Java配置。
我们可以在Java中做更多的事情,比如配置 RemovalListener ,当一个项从缓存中删除时执行 RemovalListener ,或者启用缓存统计记录,等等。
在我们使用的示例Spring boot应用程序中,我们已经有了以下API GET /API/v1/customer/{id} 来检索客户记录。

我们将向CustomerService类的 getCustomerByd(longCustomerId) 方法添加缓存。
要做到这一点,我们只需要做两件事
1. 将注释 @CacheConfig(cacheNames=“customers”) 添加到 CustomerService 类
提供此选项将确保 CustomerService 的所有可缓存方法都将使用缓存名称“customers”
2. 向方法 Optional getCustomerById(Long customerId) 添加注释 @Cacheable
@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}另外,在方法 getCustomerById() 中添加一个 LOGGER 语句,以便我们知道服务方法是否得到执行,或者值是否从缓存返回。
代码如下:log.info("Fetching customer by id: {}", customerId);这就是缓存工作所需的全部内容。现在是测试缓存的时候了。
启动您的应用程序,并点击客户获取url
http://localhost:8080/api/v1/customer/
在第一次API调用之后,您将在日志中看到以下行—“ Fetching customer by id ”。
但是,如果再次点击API,您将不会在日志中看到任何内容。这意味着该方法没有得到执行,并且从缓存返回客户记录。
现在等待一分钟(因为缓存过期时间设置为1分钟)。
一分钟后再次点击GETAPI,您将看到下面的语句再次被记录——“通过id获取客户”。
这意味着客户记录在1分钟后从缓存中删除,必须再次从数据库中获取。
通常我们缓存 GET 调用,以提高性能。
但我们需要非常小心的是缓存对象的更新/删除。
@CachePut @cacheexecute
如果未将 @CachePut/@cacheexecute 放入更新/删除方法中,GET调用中缓存返回的对象将与数据库中存储的对象不同。考虑下面的示例场景。
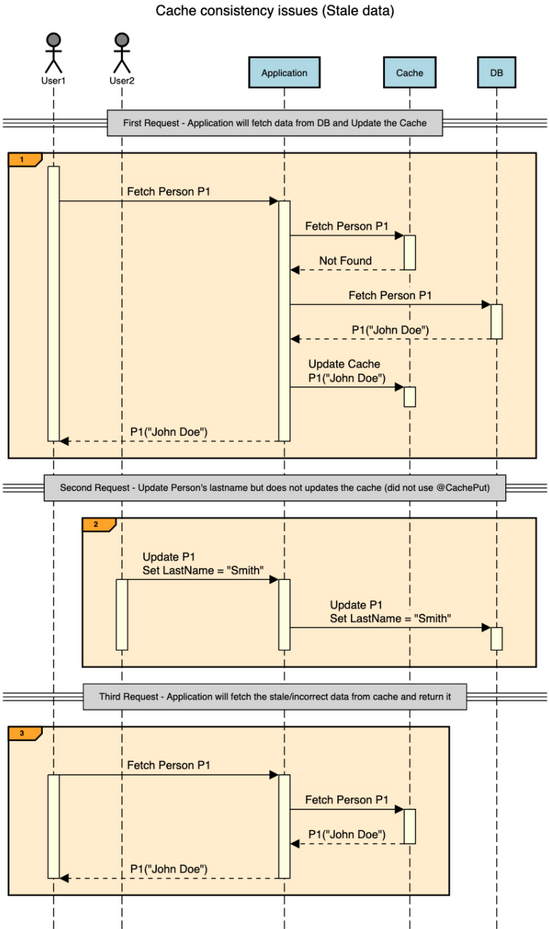
如您所见,第二个请求已将人名更新为“ John Smith ”。但由于它没有更新缓存,因此从此处开始的所有请求都将从缓存中获取过时的个人记录(“ John Doe ”),直到该项在缓存中被删除/更新。
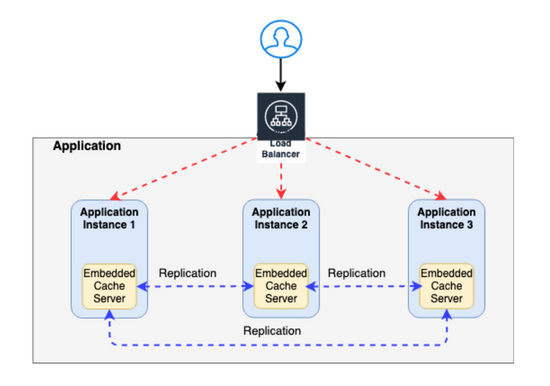
大多数现代web应用程序通常有多个应用程序节点,并且在大多数情况下都有一个负载平衡器,可以将用户请求重定向到一个可用的应用程序节点。
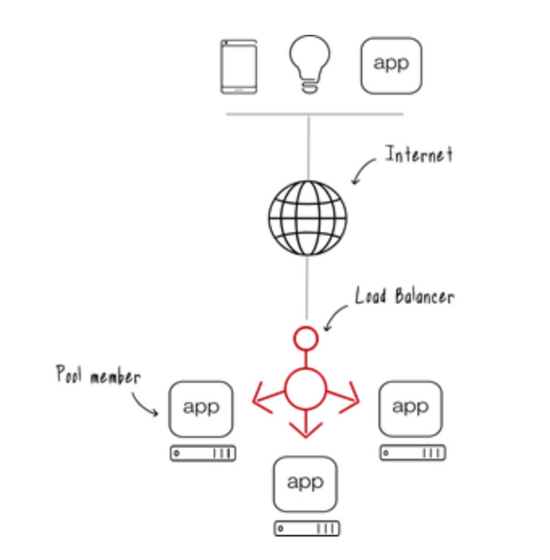
这种类型的部署为应用程序提供了可伸缩性,任何用户请求都可以由任何一个可用的应用程序节点提供服务。
在这些分布式环境(具有多个应用服务器节点)中,缓存可以通过两种方式实现
应用服务器中的嵌入式缓存(正如我们现在看到的)
远程缓存服务器
嵌入式缓存驻留在应用程序服务器中,它随应用程序服务器启动/停止。由于每台服务器都有自己的缓存副本,因此对其缓存的任何更改/更新都不会自动反映在其他应用程序服务器的缓存中。
考虑具有嵌入式缓存的多节点应用服务器的下面场景,其中用户可以根据应用服务器为其请求服务而得到不同的结果。
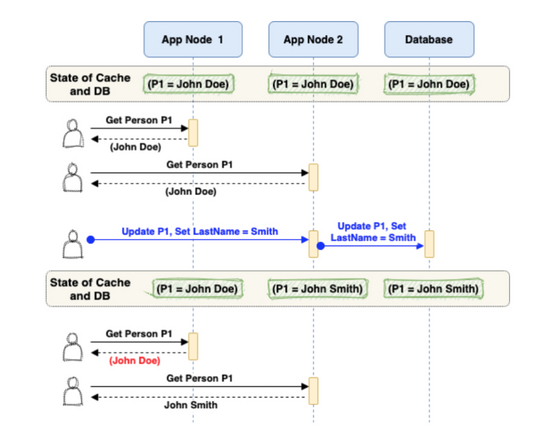
正如您在上面的示例中所看到的,更新请求更新了 Application Node2 的数据库和嵌入式缓存。
但是, Application Node1 的嵌入式缓存未更新,并且包含过时数据。因此, Application Node1 的任何请求都将继续服务于旧数据。
要解决这个问题,您需要实现 CACHE REPLICATION —其中任何一个缓存中的任何更新都会自动复制到其他缓存(下图中显示为蓝色虚线)
解决上述问题的另一种方法是使用远程缓存服务器(如下所示)。

然而,这种方法的最大缺点是增加了响应时间——这是由于从远程缓存服务器获取数据时的网络延迟(与内存缓存相比)
到目前为止,我们看到的缓存示例是向应用程序添加基本缓存所需的唯一代码。
然而,现实世界的场景可能不是那么简单,可能需要进行一些定制。在本节中,我们将看到几个这样的例子
我们知道缓存是密钥、值对的存储。
示例1:默认缓存键–具有单参数的方法
最简单的缓存键是当方法只有一个参数,并且该参数成为缓存键时。在下面的示例中, Long customerId 是缓存键

示例2:默认缓存键–具有多个参数的方法
在下面的示例中,缓存键是所有三个参数的SimpleKey– countryId 、 regionId 、 personId 。

示例3:自定义缓存密钥
在下面的示例中,我们将此人的 emailAddress 指定为缓存的密钥

示例4:使用 KeyGenerator 的自定义缓存密钥
让我们看看下面的示例–如果要缓存当前登录用户的所有角色,该怎么办。

该方法中没有提供任何参数,该方法在内部获取当前登录用户并返回其角色。
为了实现这个需求,我们需要创建一个如下所示的自定义密钥生成器

然后我们可以在我们的方法中使用这个键生成器,如下所示。

在某些用例中,我们只希望在满足某些条件的情况下缓存结果
示例1(支持 java.util.Optional –仅当存在时才缓存)
仅当结果中存在 person 对象时,才缓存 person 对象。
@Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
示例2(如果需要,by-pass缓存)
@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
仅当方法参数“ fetchFromCache ”为true时,才从缓存中获取人员。通过这种方式,方法的调用方有时可以决定绕过缓存并直接从数据库获取值。
示例3(基于对象属性的条件计算)
仅当价格低于500且产品有库存时,才缓存产品。
@Cacheable( value="products", condition="#product.price<500", unless="#result.outOfStock") public Product findProduct(Product product)
我们已经看到 @Cacheable 用于将项目放入缓存。
但是,如果该对象被更新,并且我们想要更新缓存,该怎么办?
我们已经在前面的一节中看到,不更新缓存post任何更新操作都可能导致从缓存返回错误的结果。
@CachePut(key = "#person.id") public Person update(Person person)
但是如果 @Cacheable 和 @CachePut 都将一个项目放入缓存,它们之间有什么区别?
主要区别在于实际的方法执行
@Cacheable @CachePut
缓存失效与将对象放入缓存一样重要。
当我们想要从缓存中删除一个或多个对象时,有很多场景。让我们看一些例子。
例1
假设我们有一个用于批量导入个人记录的API。
我们希望在调用此方法之前,应该清除整个 person 缓存(因为大多数 person 记录可能会在导入时更新,而缓存可能会过时)。我们可以这样做如下
@CacheEvict( value = "persons", allEntries = true, beforeInvocation = true) public void importPersons()
例2
我们有一个Delete Person API,我们希望它在删除时也能从缓存中删除 Person 记录。
@CacheEvict( value = "persons", key = "#person.emailAddress") public void deletePerson(Person person)
默认情况下 @CacheEvict 在方法调用后运行。
到此,关于“SpringBoot怎么使用Caffeine实现缓存”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





