这篇文章主要介绍了selenium如何获取动态数据的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇selenium如何获取动态数据文章都会有所收获,下面我们一起来看看吧。
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可获取。对于一些 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。接下来,就让我们来感受一下它的强大之处吧。
首先,我们使用selenium进行测试,所以我们得安装selenium库。
pip install selenium
webdriver 是浏览器对应的驱动,我们使用的的浏览器有三种谷歌Chrome、微软Microsoft Edge、还有一个火狐Firefox,但是我们经常使用谷歌Chrome浏览器进行测试。现在我们就以Chrome浏览器为例下载它对应的chromedriver 。
官网:http://chromedriver.storage.googleapis.com/index.html
注意:
我们下载chromedriver 驱动时,我们要查明浏览器的版本,要对应相应的版本号进行下载,否则会报错。禁止Google浏览器更新服务,可以上网查教程。
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而 Selenium 提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
获取节点的方法:
find_element_by_id find_element_by_name find_element_by_xpath find_element_by_link_text 专门用来定位超链接文本(标签) 全匹配 find_element_by_partial_link_text 模糊匹配 find_element_by_tag_name find_element_by_class_name find_element_by_css_selector
给个示例
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
browser.find_element_by_id('su').click()
# 提取页面
print(browser.page_source.encode('utf-8'))
# 提取cookie
print(browser.get_cookies())
# 提取当前请求地址
print(browser.current_url)
browser.close()运行代码后发现,会自动弹出一个 Chrome 浏览器。浏览器首先会跳转到百度,然后在搜索框中输入 Python,接着跳转到搜索结果页
注:当我们的chromedriver驱动没有放置到Chrome浏览器路径时,我们可以使用以下来申明浏览器对象。
browser = webdriver.Chrome(executable_path="chromedriver安装路径")方法总结:
brower.get(url):跳转当前url链接。
browser.find_element_by_id('id属性值'):定位到id属性值。
send_keys('输入关键字'):定位到输入框后输入。
find_element_by_id('id属性值').click():定位到id属性值后点击。
browser.page_source.encode('utf-8'):获取当前页面的源码。
browser.get_cookies():提取cookies。
browser.current_url:获取当前页面的url。
brower.close():关闭浏览器。
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script() 方法即可实现,代码如下:
# document.body.scrollHeight 获取页面高度
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://36kr.com/')
# 下拉边框 一次性下拉
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 慢慢的下拉
for i in range(1,9):
time.sleep(random.randint(100, 300) / 1000)
browser.execute_script('window.scrollTo(0,{})'.format(i * 700))这里就利用 execute_script() 方法将进度条下拉到最底部。为了模拟人为活动,我们调节了下拉的缓冲时间。
我们使用浏览器的控制台输入以下代码也能运行。
window.scrollTo(0, document.body.scrollHeight)图例:
我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame() 方法来切换 Frame。示例如下:
browser.get('https://www.douban.com/')
login_iframe = browser.find_element_by_xpath('//div[@class="login"]/iframe')
browser.switch_to.frame(login_iframe)
browser.find_element_by_class_name('account-tab-account').click()
browser.find_element_by_id('username').send_keys('123123123')首先我们要定位到iframe,然后用switch_to.frame() 方法来切换 Frame,这时我们就可以定位到子 Frame进行有关操作了。
平常使用浏览器时都有前进和后退功能,Selenium 也可以完成这个操作,它使用 back() 方法后退,使用 forward() 方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()这里我们连续访问 3 个页面,然后调用 back() 方法回到第二个页面,接下来再调用 forward() 方法又可以前进到第三个页面。
在访问网页的时候,会开启一个个选项卡。在 Selenium 中,我们也可以对选项卡进行操作。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://python.org')这里我们先跳转到百度再打开一个空白选项卡打印选项卡编号,再跳转到第二个选项卡也就是这个空白选项卡打开淘宝,休息一秒,再跳转到第一个选项卡打开python官网。
selenium有很多配置,下面我举几个常见的。
options = webdriver.ChromeOptions()
# 无头模式
option.add_argument("-headless")
#设置代理
options.add_argument('proxy-server=' +'192.168.0.28:808')
#将浏览器最大化显示
browser.maximize_window()
# 设置宽高
browser.set_window_size(480, 800)
# 通过js新打开一个窗口
driver.execute_script('window.open("https://www.baidu.com");')
browser = webdriver.Chrome(chrome_options=options)绕过检测对于一些网站的自动化反爬很管用。
# 设置屏蔽
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
browsers = webdriver.Chrome(chrome_options=options)
browsers.get('https://bot.sannysoft.com/')这里我们使用下面这个网站进行自动化检测
网站:https://bot.sannysoft.com/
我们没设置绕过检测
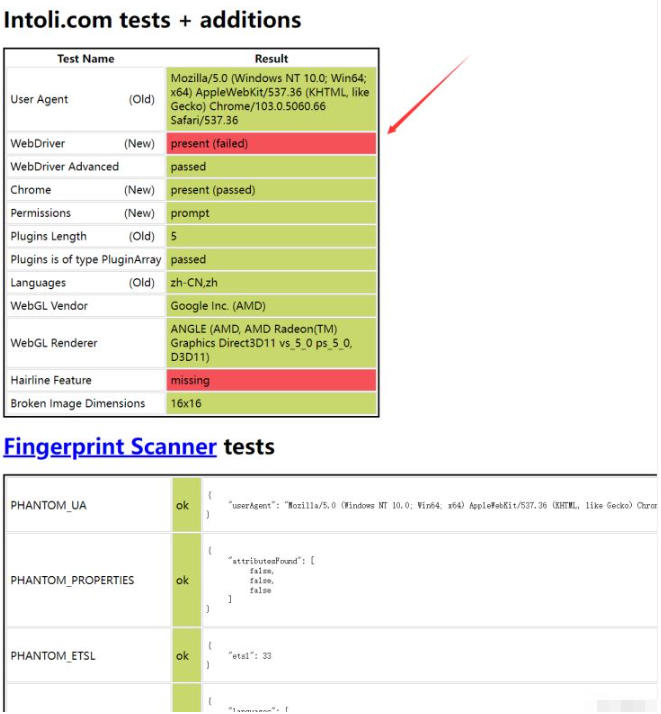
我们设置了绕过检测后
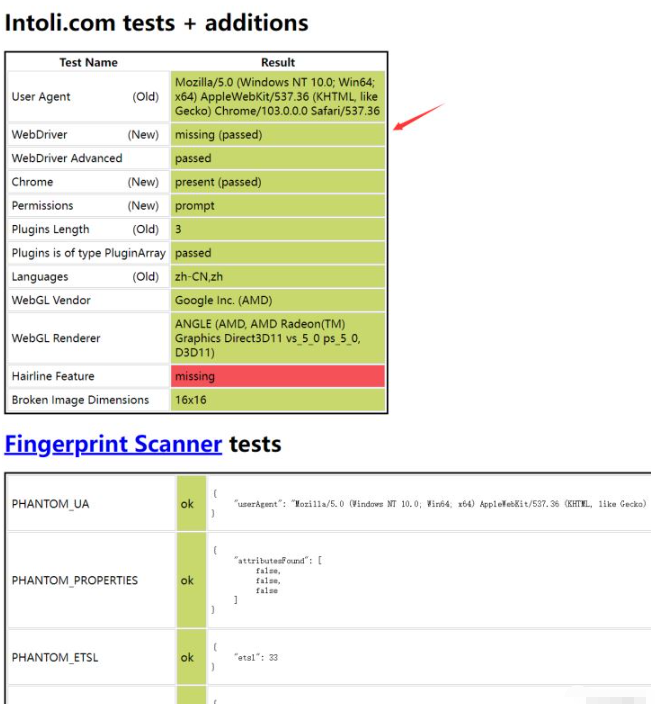
关于“selenium如何获取动态数据”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“selenium如何获取动态数据”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



