这篇文章主要讲解了“Python之异常值检测和处理方式是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python之异常值检测和处理方式是什么”吧!
在机器学习中,异常检测和处理是一个比较小的分支,或者说,是机器学习的一个副产物,因为在一般的预测问题中,模型通常是对整体样本数据结构的一种表达方式,这种表达方式通常抓住的是整体样本一般性的性质,而那些在这些性质上表现完全与整体样本不一致的点,我们就称其为异常点,通常异常点在预测问题中是不受开发者欢迎的,因为预测问题通产关注的是整体样本的性质,而异常点的生成机制与整体样本完全不一致,如果算法对异常点敏感,那么生成的模型并不能对整体样本有一个较好的表达,从而预测也会不准确。
从另一方面来说,异常点在某些场景下反而令分析者感到极大兴趣,如疾病预测,通常健康人的身体指标在某些维度上是相似,如果一个人的身体指标出现了异常,那么他的身体情况在某些方面肯定发生了改变,当然这种改变并不一定是由疾病引起(通常被称为噪音点),但异常的发生和检测是疾病预测一个重要起始点。相似的场景也可以应用到信用欺诈,网络攻击等等。
一般异常值的检测方法有基于统计的方法,基于聚类的方法,以及一些专门检测异常值的方法等,下面对这些方法进行相关的介绍。
如果使用pandas,我们可以直接使用describe()来观察数据的统计性描述(只是粗略的观察一些统计量),不过统计数据为连续型的,如下:
df.describe()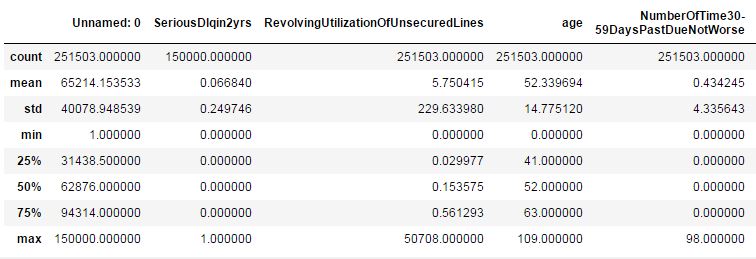
或者简单使用散点图也能很清晰的观察到异常值的存在。如下所示:
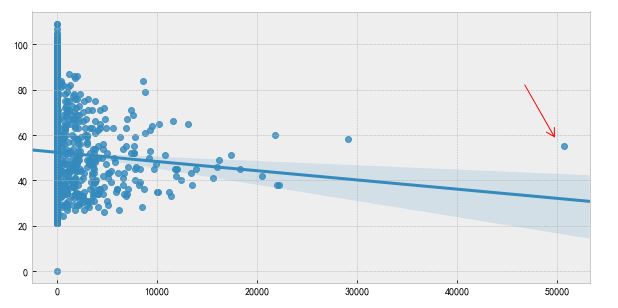
这个原则有个条件:数据需要服从正态分布。在3∂原则下,异常值如超过3倍标准差,那么可以将其视为异常值。正负3∂的概率是99.7%,那么距离平均值3∂之外的值出现的概率为P(|x-u| > 3∂) <= 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
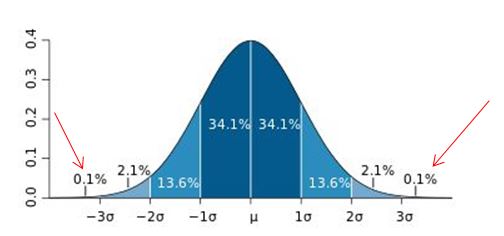
红色箭头所指就是异常值。
这种方法是利用箱型图的四分位距(IQR)对异常值进行检测,也叫Tukey‘s test。箱型图的定义如下:
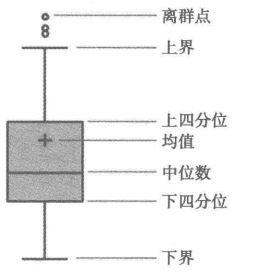
四分位距(IQR)就是上四分位与下四分位的差值。而我们通过IQR的1.5倍为标准,规定:超过上四分位+1.5倍IQR距离,或者下四分位-1.5倍IQR距离的点为异常值。下面是Python中的代码实现,主要使用了numpy的percentile方法。
Percentile = np.percentile(df['length'],[0,25,50,75,100])
IQR = Percentile[3] - Percentile[1]
UpLimit = Percentile[3]+ageIQR*1.5
DownLimit = Percentile[1]-ageIQR*1.5也可以使用seaborn的可视化方法boxplot来实现:
f,ax=plt.subplots(figsize=(10,8))
sns.boxplot(y='length',data=df,ax=ax)
plt.show()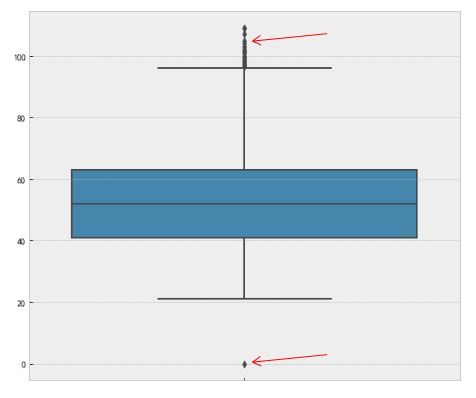
红色箭头所指就是异常值。
以上是常用到的判断异常值的简单方法。下面来介绍一些较为复杂的检测异常值算法,由于涉及内容较多,仅介绍核心思想,感兴趣的朋友可自行深入研究。
这种方法一般会构建一个概率分布模型,并计算对象符合该模型的概率,把具有低概率的对象视为异常点。如果模型是簇的集合,则异常是不显著属于任何簇的对象;如果模型是回归时,异常是相对远离预测值的对象。
离群点的概率定义:离群点是一个对象,关于数据的概率分布模型,它具有低概率。这种情况的前提是必须知道数据集服从什么分布,如果估计错误就造成了重尾分布。
比如特征工程中的RobustScaler方法,在做数据特征值缩放的时候,它会利用数据特征的分位数分布,将数据根据分位数划分为多段,只取中间段来做缩放,比如只取25%分位数到75%分位数的数据做缩放。这样减小了异常数据的影响。
优缺点:
(1)有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效;
(2)对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
统计方法是利用数据的分布来观察异常值,一些方法甚至需要一些分布条件,而在实际中数据的分布很难达到一些假设条件,在使用上有一定的局限性。
确定数据集的有意义的邻近性度量比确定它的统计分布更容易。这种方法比统计学方法更一般、更容易使用,因为一个对象的离群点得分由到它的k-最近邻(KNN)的距离给定。
需要注意的是:离群点得分对k的取值高度敏感。如果k太小,则少量的邻近离群点可能导致较低的离群点得分;如果K太大,则点数少于k的簇中所有的对象可能都成了离群点。为了使该方案对于k的选取更具有鲁棒性,可以使用k个最近邻的平均距离。
优缺点:
(1)简单;
(2)缺点:基于邻近度的方法需要O(m2)时间,大数据集不适用;
(3)该方法对参数的选择也是敏感的;
(4)不能处理具有不同密度区域的数据集,因为它使用全局阈值,不能考虑这种密度的变化。
5. 基于密度的离群点检测
从基于密度的观点来说,离群点是在低密度区域中的对象。基于密度的离群点检测与基于邻近度的离群点检测密切相关,因为密度通常用邻近度定义。一种常用的定义密度的方法是,定义密度为到k个最近邻的平均距离的倒数。如果该距离小,则密度高,反之亦然。另一种密度定义是使用DBSCAN聚类算法使用的密度定义,即一个对象周围的密度等于该对象指定距离d内对象的个数。
优缺点:
(1)给出了对象是离群点的定量度量,并且即使数据具有不同的区域也能够很好的处理;
(2)与基于距离的方法一样,这些方法必然具有O(m2)的时间复杂度。对于低维数据使用特定的数据结构可以达到O(mlogm);
(3)参数选择是困难的。虽然LOF算法通过观察不同的k值,然后取得最大离群点得分来处理该问题,但是,仍然需要选择这些值的上下界。
基于聚类的离群点:一个对象是基于聚类的离群点,如果该对象不强属于任何簇,那么该对象属于离群点。
离群点对初始聚类的影响:如果通过聚类检测离群点,则由于离群点影响聚类,存在一个问题:结构是否有效。这也是k-means算法的缺点,对离群点敏感。为了处理该问题,可以使用如下方法:对象聚类,删除离群点,对象再次聚类(这个不能保证产生最优结果)。
优缺点:
(1)基于线性和接近线性复杂度(k均值)的聚类技术来发现离群点可能是高度有效的;
(2)簇的定义通常是离群点的补,因此可能同时发现簇和离群点;
(3)产生的离群点集和它们的得分可能非常依赖所用的簇的个数和数据中离群点的存在性;
(4)聚类算法产生的簇的质量对该算法产生的离群点的质量影响非常大。
其实以上说到聚类方法的本意是是无监督分类,并不是为了寻找离群点的,只是恰好它的功能可以实现离群点的检测,算是一个衍生的功能。
除了以上提及的方法,还有两个专门用于检测异常点的方法比较常用:One Class SVM和Isolation Forest,详细内容不进行深入研究。
检测到了异常值,我们需要对其进行一定的处理。而一般异常值的处理方法可大致分为以下几种:
删除含有异常值的记录:直接将含有异常值的记录删除;
视为缺失值:将异常值视为缺失值,利用缺失值处理的方法进行处理;
平均值修正:可用前后两个观测值的平均值修正该异常值;
不处理:直接在具有异常值的数据集上进行数据挖掘;
是否要删除异常值可根据实际情况考虑。因为一些模型对异常值不很敏感,即使有异常值也不影响模型效果,但是一些模型比如逻辑回归LR对异常值很敏感,如果不进行处理,可能会出现过拟合等非常差的效果。
感谢各位的阅读,以上就是“Python之异常值检测和处理方式是什么”的内容了,经过本文的学习后,相信大家对Python之异常值检测和处理方式是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



