这篇文章主要介绍了Pandas索引排序 df.sort_index()的实现方法,具有一定借鉴价值,需要的朋友可以参考下。下面就和我一起来看看吧。
df.sort_index()实现按索引排序,默认以从小到大的升序方式排列,如希望按降序排列,传入ascending = False
import pandas as pd
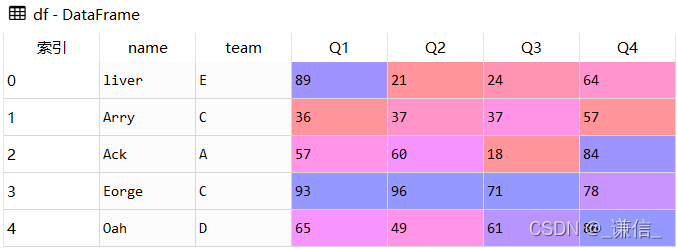
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
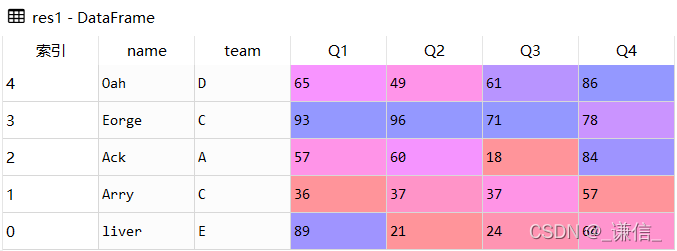
# 索引降序
res1 = df.sort_index(ascending=False)
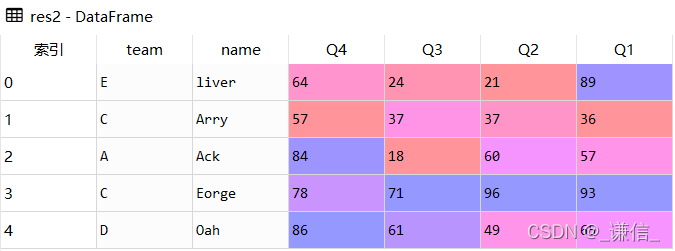
# 按列索引名排序:
# 在索引方向上排序
res2 = df.sort_index(axis=1, ascending=False)结果展示
df
res1
res2
扩展
# 更多方法如下:
s.sort_index() # 升序排列
df.sort_index() # df也是按索引进行排序
df.team.sort_index()
s.sort_index(ascending=False) # 降序排列
s.sort_index(inplace=True) # 排序后生效,改变原数据
# 索引重新0-(n-1)排,可以得到它的排序号
s.sort_index(ignore_index=True)
s.sort_index(na_position='first') # 空值在前,另'last'表示空值在后
s.sort_index(level=1) # 如果多层,排一级
s.sort_index(level=1, sort_remaining=False) # 这层不排
# 行索引排序,表头排序
df.sort_index(axis=1) # 会把列按列名顺序排序df.reindex()指定自己定义顺序的索引,实现行和列的顺序重新定义
import pandas as pd
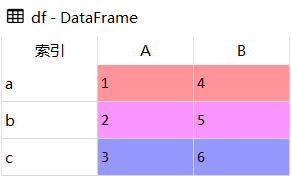
df = pd.DataFrame({
'A':[1,2,3],
'B':[4,5,6]
},index=['a','b','c'])
# 按要求重新指定索引顺序
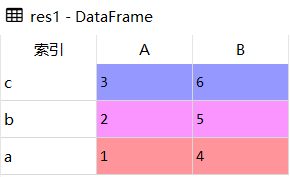
res1 = df.reindex(['c','b','a'])
# 指定列顺序
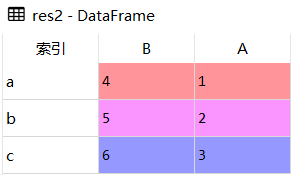
res2 = df.reindex(['B','A'], axis=1)结果展示
df
res1
res2
以上就是Pandas索引排序 df.sort_index()的实现方法的详细内容了,看完之后是否有所收获呢?如果想了解更多相关内容,欢迎来亿速云行业资讯!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



