这篇“yolov7数据集及项目部署的方法”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“yolov7数据集及项目部署的方法”文章吧。
首先确保你有labelimg标图软件,若无,需要自行去下一个并看一下标图教程。
当你已经标注完成,获得了img以及相对应的xml之后(如图)

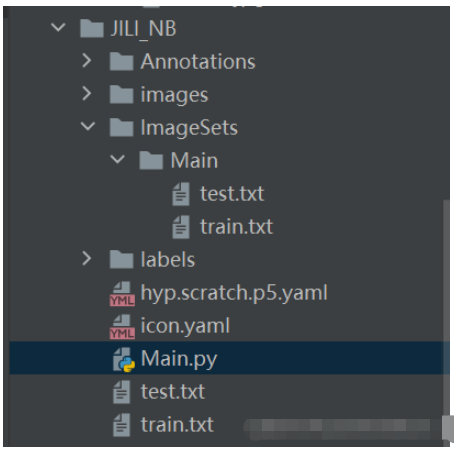
接下来就是可选择项:是否需要图像增强来获取更多样本,如需要点击这里下载 ,直接用enhance_img.py去增强。之后我的习惯是每有一个项目需要训练,则会新建一个文件夹,项目存放的文件如图:
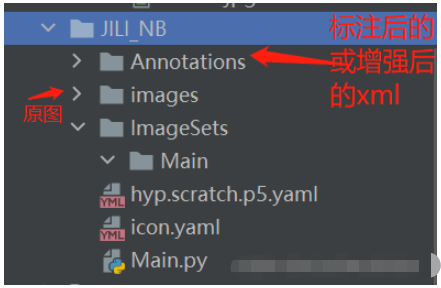
下面ImageSets\Main用于存放后续脚本文件划分训练集测试集的相对应的train.txt,test.txt。hyp.scratch.p5.yaml为yolov7的超参设置,可以直接从yolov7\data下面去拷过来放到你项目里。icon.yaml为你要所要训练的类别和相应的类,同时也会写上实际训练时训练数据和测试数据。该文件如下图。

Main.py就是划分你的数据为训练集和测试集.txt的脚本。整体新建的项目目录就是这样。下面说一下操作流程:1 首先确保是该项目目录方式 2 运行main.py脚本文件得到了ImageSets\Main下面的train.txt,test.txt。3 在yolov7的根目录下运行xml2txt脚本文件。main.py xml2txt.py文件点击这里下载 注意要将该文件的类和项目名改成自己的。如图:
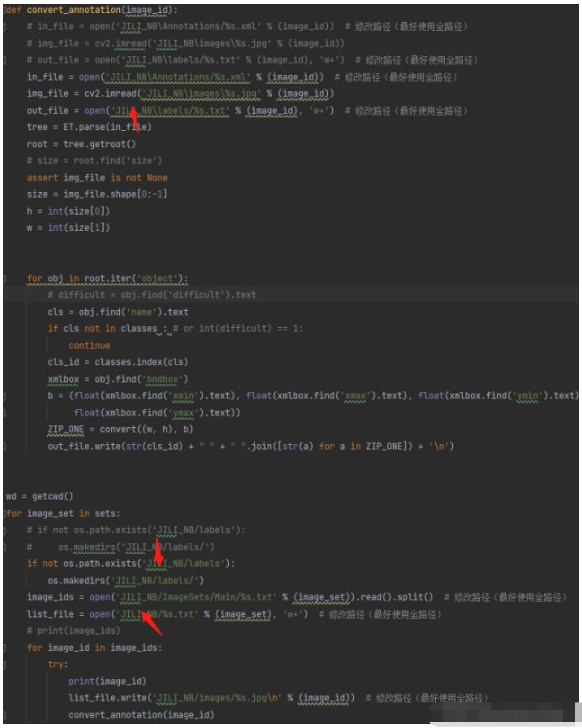

此时,我们的数据准备阶段已经完成,项目目录如图:
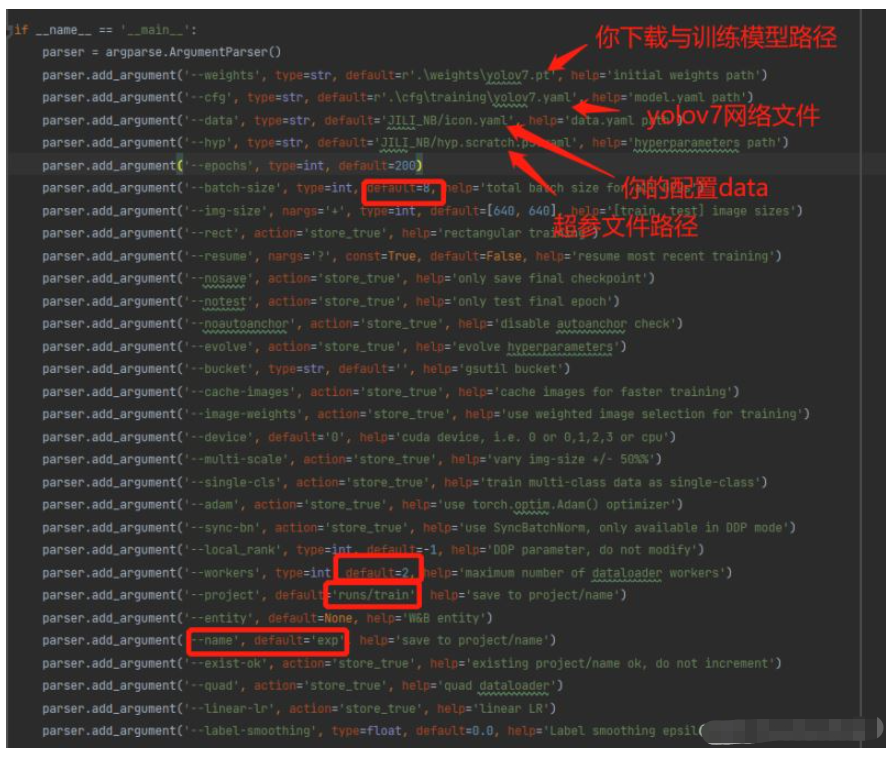
红色箭头和红框就是常见改动的地方,改动后就可以训练了。
在等待训练完成之后,就会在runs/train下面获得训练的best.pt,你可以拿着这个pt去做接口使用了。首先,在自己的项目里使用必须要确保yolov7根目录下的models和utils文件夹放到了你的项目根目录。然后下载model_import.py 点击这里下载 嵌入你的任何项目路径下调用predict函数就可以输出检出结果了。
以上就是关于“yolov7数据集及项目部署的方法”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





