这篇文章主要讲解了“Linux行处理工具之grep正则表达式实例分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Linux行处理工具之grep正则表达式实例分析”吧!
在介绍正则表达式之前,我们先来尝试一下,假如有如下文本。
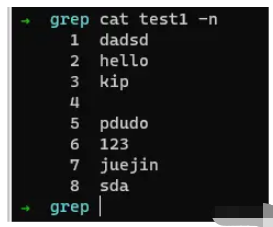
我们想获取空行,应该如何来写呢?
命令:
grep ^$ test1 -n
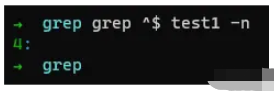
通过上述例子,我们使用正则表达式^$已经成功拿到了第四行数据,那么,这究竟如何解呢,我们细看博文。
grep表达式有三种不同的版本,分别为basic(BRE) 、extended(ERE) 以及 perl(PCRE) ,我们grep默认支持的是BRE,而ERE是egrep支持的,或者说是grep -E支持的, 而PCRE则是grep -P支持的,那么这三者究竟有啥区别呢?
| BRE | ERE | PCRE | |||
|---|---|---|---|---|---|
| 任意字符 | . | . | . | ||
| 前一个字符0次或者出现1次 | ? | ? | ? | ||
| 前一个字符出现0次或无数次 | * | * | * | ||
| 前一个字符出现一个或者更多 | + | + | + | ||
| 字符集 | [...] | [...] | [...] | ||
| 字符集取反 | [^...] | [^...] | [^...] | ||
| 匹配前面字符出现的n次 | {n} | {n} | {n} | ||
| 匹配前面字符出现的n次以上 | {n,} | {n,} | {n,} | ||
| 匹配前面字符出现的n次到m次 | {n,m} | {n,m} | {n,m} | ||
| 开头 | |||||
| 结尾 | $ | $ | $ | ||
| 多表达式连接 | | | ||||
| 单词 | \w | \w | \w 或者 [[:word:]] | ||
| 字母大写/小写 | [[:upper:]]/[[:lower:]] | [[:upper:]]/[[:lower:]] | [[:upper:]]/[[:lower:]] | ||
| 非单词 | \W | ||||
| 空白字符 | \s 或者 [[:space:]] | \s 或者 [[:space:]] | |||
| 非空白字符 | [^[:space:]] | [^[:space:]] | \S | ||
| 数字 | \d 或者 [[:digit:]] | [[:digit:]] | [[:digit:]] | ||
| 非数字 | \D | [^[:digit:]] | [^[:digit:]] |
那么如何进行切换呢? 如上面所示,我们来看下。
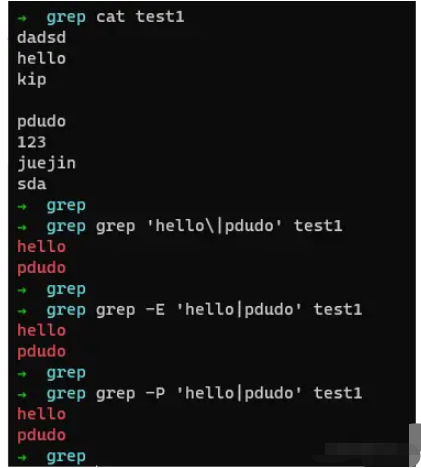
如上所述,若我们需要连接多个匹配项,在BRE(grep)中则是|,而在ERE(egrep)和PCRE(grep -P)中则是|,所以我们可以顺利获取出结果,更多匹配项如上所述
匹配电话号码
若电话号码为xxx-xxxx-xxxx类型的,如何进行匹配呢? 我们可以使用'[0-9]{3}-[0-9]{4}-[0-9]{4}'进行匹配。
例如:
命令:
echo "telphone: 180-1234-5678" | grep '[0-9]{3}-[0-9]{4}-[0-9]{4}' -o
同样的,该方法还可以用来匹配其ip地址,正则: [0-9]{0,3}.[0-9]{0,3}.[0-9]{0,3}.[0-9]{0,3}

匹配空行
若我们想匹配空行,则可以使用^$进行匹配,即: 开头就是结尾。
例如:
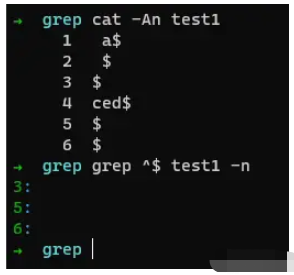
如上命令,我们顺利取出了 第3、5、6行数据
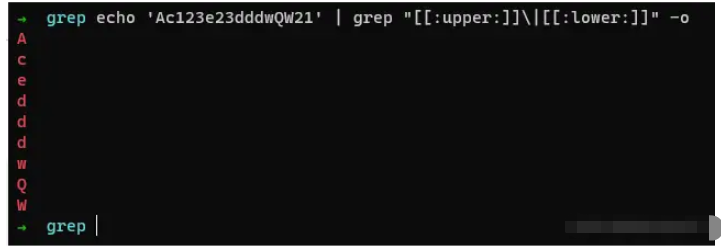
匹配所有字母
命令:
echo 'Ac123e23dddwQW21' | grep "[[:upper:]]|[[:lower:]]" -o
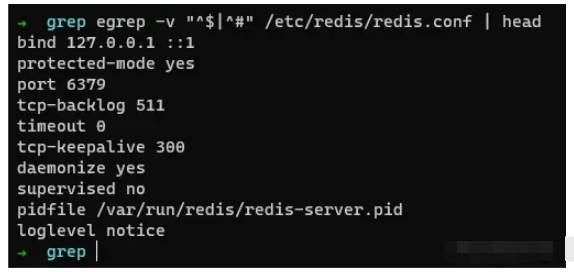
取出redis在使用的配置文件
我们知道redis服务器是以#来注释的,我们可以利用grep或者egrep来过滤掉注释和空格,例如:
fgrep最为简单,它不会启用正则表达式,而是按照字符来进行搜索,什么意思呢? 我们举个小案例就清楚了,
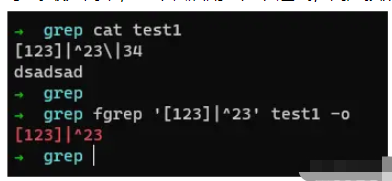
它不会进行任何正则匹配,所以可以直接使用搜索选就成,不用考虑转移啥的。
感谢各位的阅读,以上就是“Linux行处理工具之grep正则表达式实例分析”的内容了,经过本文的学习后,相信大家对Linux行处理工具之grep正则表达式实例分析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





