5.1 根文件系统
众所周知,在一块新的硬盘中安装系统前必须要先分区并且格式化,然后才能装系统。
对于windows来说,分区完成以后,每个分区都是一个独立的文件系统。也就意味着C盘和D盘是毫无关系的。访问时也是各自独立的。
对于linux来说,所有的文件在linux主机上,若想使其能够被访问到,站在逻辑结构视角上看,它必须从一个称为根文件系统的位置开始,但是并不是说所有文件必须从根开始就不需要分区了,并非如此。为了能够实现多个文件系统独立管理必须要进行分区。但是任何一个分区在分区完以后,不可以被独立访问,而是只能够与现有的根一起被访问。
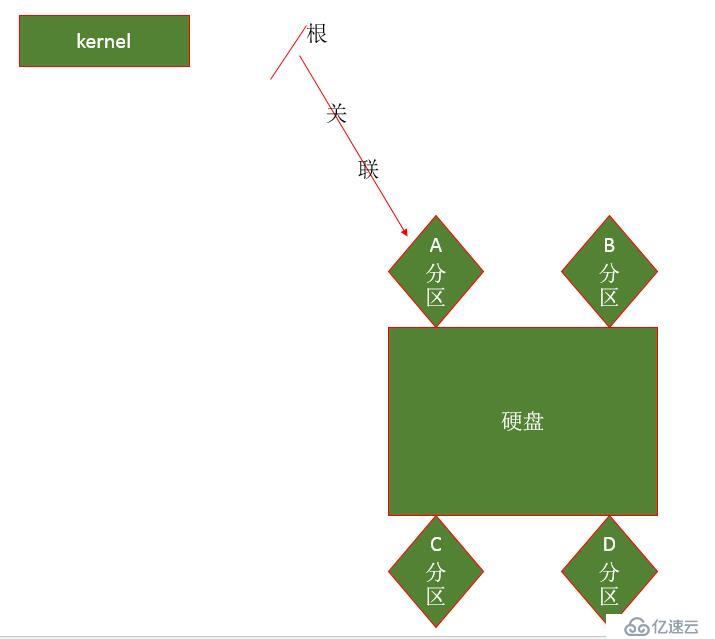
当内核被启动加载完成以后,其不提供任何多余的可供用户访问的文件,同时其也不是可供用户直接使用的有用的进程。所以内核必须要能够启动很多外部命令,包括shell程序、各种GUI或者CLI接口等等。而这些命令通常一般都是放在某一分区之上。但是系统中有那么多分区,内核应该识别哪一个呢?为了避免这种选择上的困难,一般来说,无论分成多少个分区,一定有一个作为系统盘的分区存在,而这个系统盘分区通常是内核启动完以后第一个要加载的分区。
如上图所示,假设A分区是系统盘分区,内核认为A分区是其必须第一个要加载的分区,于是当内核启动完以后,为了能够帮助启动各种外围的其他程序,内核会自行在自己的工作空间中设置一个路径,把它称作根。然后把A(系统盘)分区上的所有内容直接关联到根上。这也就意味着,如果要通过根路径来访问的任何文件其实都是在A分区上的文件。
对于Linux来说,内核所能识别的第一个且必须第一个加载的文件系统就称作根文件系统(rootfs)。
一旦A分区被内核认为是第一个要加载的分区,那么B分区、C分区、D分区如何被访问到?在windows中,A分区、B分区、C分区、D分区都是独立的,想访问哪个分区就直接去访问。而在linux中,除A(系统盘)分区以外的任何分区要想被访问到,必须与现有的根文件系统建立关联关系。
5.2 常见的文件系统
常见的文件系统有以下这些:
Linux文件系统:ext2、ext3、ext4、xfs、btrfs、reiserfs、jfs、swap
swap:交换分区
iso9660:光盘文件系统
ext4:centos6主流的文件系统
btrfs:centos7自带的文件系统
xfs:centos7上推荐使用的文件系统
Windows文件系统:fat32、ntfs
Unix文件系统:FFS、UFS、JFS2
网络文件系统:NFS、CIFS
集群文件系统:GFS2、OCFS2
分布式文件系统:ceph、moosefs、mogilefs、Glusterfs、Lustre
根据其是否支持“Journal”功能又分为以下2种文件系统:
日志型文件系统:ext3、ext4、xfs、...
日志型文件系统存储时先在日志区写元数据,如果发生断电,可以通过日志进行恢复
非日志型文件系统:ext2、vfat
非日志型文件系统存储时直接在元数据区写元数据,一旦断电,没写完的数据将损坏且无法恢复
文件系统的组成部分:
内核中的模块:ext4、xfs、vfat等;
用户空间的管理工具:mkfs.ext4、mkfs.xfs、mkfs.vfat等
从上面的信息就可以看出来,Linux支持众多的文件系统,而每一个文件系统的调用接口又是不一样的,这对程序员来说就头疼了,如此多的文件系统,若想针对某文件系统进行编程,就必须了解众多文件系统的调用接口,这样一来就使得编程的难度大大增加。而事实上,程序员面对的并不是ext2等这类文件系统 ,而是虚拟文件系统(VFS)。VFS把所有文件系统不同的各种调用机制统一在同一个调用接口上了。所以程序员不管系统被格式化成什么格式的,只要支持VFS,就可以直接调用VFS接口,由VFS去转换成对特定类型的文件系统接口的调用。Linux众多的文件系统中,只要遵循POSIX文件系统规范的一般都能够被VFS所兼容。
/proc/filesystems:当前内核支持的文件系统类型有哪些
文件前面没有nodev的表示是正在使用的文件系统
文件系统的配置文件/etc/fstab:
OS在初始时,会自动挂载此文件中定义的每个文件系统。这个文件的内容格式为:
要挂载的设备 挂载点 文件系统类型 挂载选项 转储频率 文件系统检测次序(只有根可以为1)
要挂载的设备可以有以下几类:
设备文件:/dev/sda5
卷标:LABEL=""
UUID:UUID=""
伪文件系统名称:proc、sysfs、devtmpfs、configfs
挂载点的要求:
a) 此目录没有被其它进程使用
b) 目录必须事先存在
c) 目录中原有的文件将会暂时隐藏,卸载后可见
转储频率:每多少天做一次完全备份,0表示不备份,1表示每天备份,2表示每2天备份1次
注意:swap分区的挂载点和文件系统类型都是swap。如果要让文件系统自动挂载的同时启用某功能,比如要启用acl功能,只需要在挂载选项defaults后面加上,acl即可,如defaults,acl
5.3 ext文件系统的布局结构
5.3.1 数据区布局结构
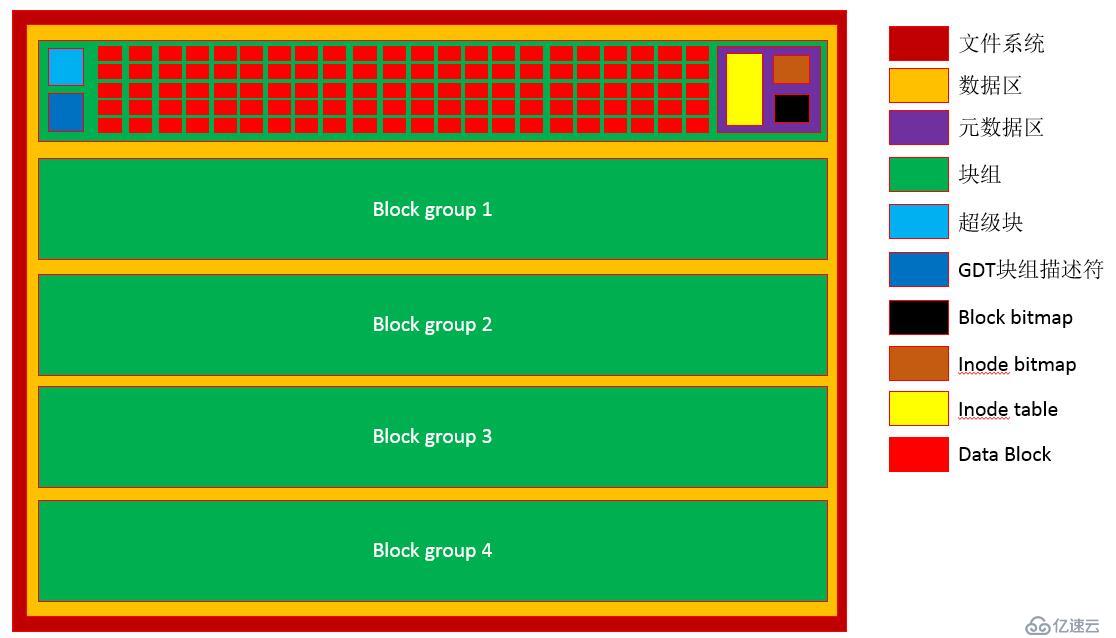
任何一个文件系统都由数据和元数据组成,这里以ext系统文件系统为例。
如上图,数据区(数据空间)会被划分为一个个的块组,而每个块组当中又包含了超级块、块组描述符(GDT)、块位图(block bitmap)、Inode位图(inode bitmap)、Inode表(inode table)和数据块(data blocks)。
每个块组有多少个块取决于块的大小,为了方便定位块组中的块于是定义了一个超级块
超级块可以有多个备份,其内容如下:
当前文件系统类型;
当前文件系统包含多少个inode;
当前文件系统共有多少个块;
当前文件系统每个块的大小;
空闲磁盘块、引用磁盘块、空闲inode、引用inode
使用tune2fs -l /dev/sda1命令可以看/dev/sda1的超级块信息。
块组描述符表(GDT)可以有多个备份,其内容如下:
当前系统一共有多少个块组
每个块组从第几个块开始到第几个块结束
使用dumpe2fs /dev/sda1命令不仅可以看到/dev/sda1文件系统的超级块信息,还可以看到块组描述符的信息。
5.3.2 元数据区
元数据区包含以下内容:
Inode表(存储inode)
Inode bitmap(索引位图)
Block bitmap(块位图)
能够存储单个文件所有属性信息并以特定格式组织的存储空间就称为Inode。
Inode就是索引节点(Index node)。Inode包含以下内容:
文件/目录的大小;
时间戳;
权限;
属主、属组;
地址指针:文件使用了哪些块存储数据,用指针指向对应的数据块的编号
直接指针(直接指向数据块)
间接指针(指向另一个位置,另外一片连续的区域,象扩展分区一样)
三级指针
访问任何一个文件都要先找到其对应的inode,通过inode知道该文件的数据存储在哪些块中,然后找到对应的块。
硬盘中的大多数块必须有其编号,并能够被inode引用,才可以正常使用。
为了实现inode的快速存储,元数据区在格式化完成以后就已经把inode整个区间分好了,每个inode块的大小是固定的,只不过这些inode是空闲的,没被使用的。
假设一个文件系统有100万个inode,那么如何区分inode是否空闲呢?
我们假设每一个inode的前面有一个标志位,1表示已经使用,0表示空闲。当要使用时就必须全局扫描,找到第一个空闲的inode,然后把要存储inode信息填充其中。
再假设数据区的每一个block块的前面也有一个标志位,1表示已经使用,0表示空闲。当要使用时也必须全局扫描,找到第一个空闲的block块,然后把数据填充其中并建立与对应inode的映射关系。
假设一个文件很大,可能需要多个block块存储其数据,就必须为其分配多个连续的空闲块来存储,并将已使用的block的标志位设为1;
假设一个文件很小,可能1个block块就可以存储其数据,就把其余多余的block标志位设为0
5.3.4 位图索引
想一个问题,如果硬盘有100G,为了找一个空闲块就要全盘扫描一遍,这样的方式太低效了,为了解决这个问题于是就有了二级索引。
由于inode的量很大,从中找一个空闲的inode会很慢,这时候可以找一个连续的存储空间,对inode做一个对位标识索引,第0位对应编号为0的inode编号,第1位对应编号为1的inode编号,以此类推。有N个二进制位,如果这个位为1表示这个对应的inode已被使用,这个位为0表示其对应的Inode空闲。当要创建inode时,就不用再全盘扫描了,只需要扫描这个二级索引(对位标识索引),如此一来,效率就大大提高了。而这个二级索引就是inode位图索引(inode bitmap)。数据区以同样的原理就有了块位图(block bitmap)
inode bitmap:对位标识每个inode空闲与否的状态信息
如果整盘进行管理,假设整盘有100万个块,100万个块扫描一遍也挺耗时间的。所以无论是inode位图还是block位图,都不是全文件系统管理的,而是块组管理的。
5.3.5 文件访问过程
a) 查索引节点(Inode)
b) 在索引节点中找到磁盘块的编号
c) 在数据区找到对应的磁盘块
5.3.6 目录
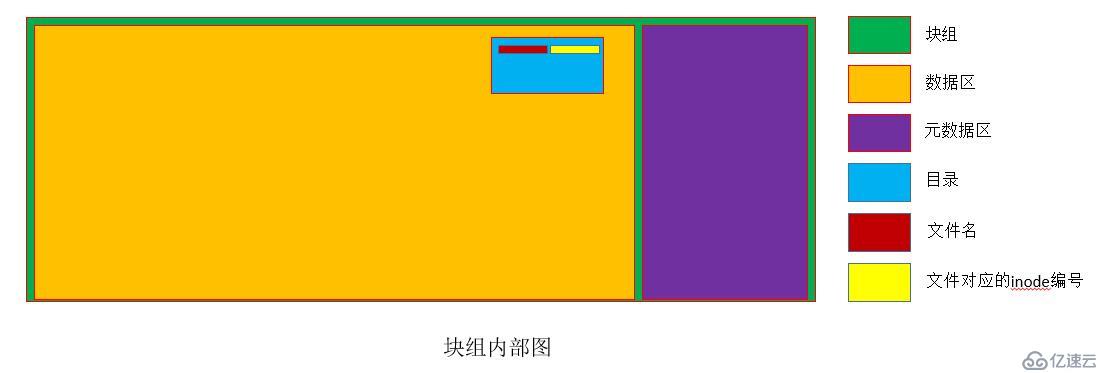
文件访问时要先查inode,但是inode表中包含很多的inode,如何确定文件对应的Inode是哪个呢?这就是目录的作用。
目录也是一个文件,存在数据区的一个块中,目录实质上就是一个路径映射。
目录中存储着以下内容:
a) 一级目录下所有的文件名列表
b) 一级目录下所有文件对应的inode编号
5.3.7 文件创建
a) 在元数据区找一个空闲的inode块存储inode信息
b) 在数据区找一个或一些空闲的block块,并将其与inode建立映射关系
c) 把数据填充至这些block块中
d) 把标志位设为1(正在使用中的状态)
5.3.8 硬链接
多个文件指向同一个inode,称之为硬链接。这些文件名称可相同也可不同,不能链接不同文件系统的文件。
硬链接特点:
a) 只能对文件创建,不能应用于目录;
b) 不能跨文件系统;
c) 创建硬链接会增加文件被链接的次数
5.3.9 软链接
软链接又叫符号链接,这个文件包含了另一个文件的路径名。可以是任意文件或目录,可以链接不同文件系统的文件。
软链接特点:
a) 可应用于目录;
b) 可以跨文件系统;
c) 不会增加被链接文件的链接次数;
d) 其大小为指定的路径所包含的字符个数
创建软链接:
ln [-s -v] SRC DEST
5.4 btrfs文件系统
5.4.1 btrfs文件系统介绍
btrfs文件系统自centos7后开始支持。
Btrfs(B-tree,Butter FS,Better FS),遵循GPL规范,由Oracle自2007年开始研发。
Btrfs文件系统的核心特性:
a) 支持写时复制机制(CoW):复制、更新及替换指针,而非传统的“就地”更新
假设要修改一个文件,写时复制机制就是先把这个文件复制一个副本出来,然后对这个副本进行修改,修改完以后将文件名的指针由指向原文件改为指向这个副本。
如此一来,原文件还在内存中,若副本修改有误还可以通过恢复指针指向的方法还原成原文件
b) 多物理卷支持
btrfs可由多个底层物理卷组成,支持RAID,以联机“添加”、“移除”、“修改”
c) 支持数据及元数据校验码机制(CheckSum)
存储文件时,会将元数据的校验码和数据的校验码通过文件某些属性扩展给保存下来。因此文件读取时可以很方便、快速的去检测文件是否受损,一旦受损还会自动尝试进行修复
d) 支持子卷(sub_volume,相当于ext系列文件系统的lvm/lvm2)
可以将多个底层的物理设备(硬盘)组织成btrfs文件系统,这个btrfs文件系统可以直接挂载使用,也可以在内部创建子卷(就像在VG中创建LV一样)
e) 支持快照(快照是子卷的一个非完全副本,基于CoW机制实现的另外一个存储空间刚开始为0的一个卷)
btrfs文件系统直接支持快照,而ext3/ext4要想支持快照必须使用lvm2来实现
可以针对单个文件做快照,也可以针对卷做快照
还支持对做好的快照再做一次快照,做累积性快照。类似于实现增量备份
f) 支持透明压缩机制
当要存储一个很大的文件,但又想节约空间的时候,可以把任何数据流发往btrfs文件系统时,自动能够通过占据CPU时钟周期完成数据压缩以后存放,对用户来说这个过程是透明的。在读取这些压缩后存放的文件时,能够自动解压缩。
有一个缺陷:压缩和解压缩会占据更多的时钟周期
Btrfs主要设计目标是取代Linux早期一直使用的ext3、ext4,但事实上在ext3、ext4的缺陷暴露之后,在centos6上就提供了另外一种可用的文件系统(xfs)。
5.4.2 btrfs文件系统的实现
mkfs.btrfs:创建btrfs文件系统
-L|--label <name>:指定卷标
-m|--metadata <profile>:指明元数据如何存放
Valid values are raid0,raid1,raid5,raid6,raid10,single or dup
-d|--data <type>:指明数据如何存放
Valid values are raid0,raid1,raid5,raid6,raid10 or single
-O|--features <feature1>[,<feature2>...]:在格式化时直接开启指定的功能
A list of filesystem features turned on at mkfs time.Not all features are supported by old kernels.
To see all features run
mkfs.btrfs -O list-all
常用的btrfs文件系统的命令:
btrfs:管理btrfs文件系统
btrfs filesystem show [--mounted|--all-devices|<uuid>] #显示btrfs文件系统信息 btrfs filesystem sync <path> #强制把指定btrfs文件系统缓存在内存中的数据同步到硬盘中 btrfs filesystem df <path> [<path>...] #查看已挂载的btrfs文件系统空间使用率 btrfs filesystem defragment [options] <file>|<dir> [<file>|<dir>...] #消除磁盘碎片 btrfs filesystem resize [devid:][+/-]<size>[gkm]|[devid:]max <path> #修改文件系统大小 btrfs filesystem label [<device>|<mount_point>] [<newlabel>] #显示或更新btrfs文件系统卷标
挂载btrfs文件系统:
mount -t btrfs /dev/sdb MOUNT_POINT #/dev/sdb这个位置只要是btrfs文件系统的底层物理卷之一,随便写哪个物理卷名均可
透明压缩机制:
mount -o compress={lzo|zlib} DEVICE MOUNT_POINTbtrfs-convert:实现无损地将ext系列的文件系统动态转换成btrfs文件系统或将btrfs文件系统降级为ext系列的文件系统
btrfsck:实现文件系统的检测
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





