MysqlиЎЁиҝһжҺҘзҡ„жү§иЎҢжөҒзЁӢжҳҜд»Җд№Ҳ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңMysqlиЎЁиҝһжҺҘзҡ„жү§иЎҢжөҒзЁӢжҳҜд»Җд№ҲвҖқзҡ„зӣёе…ізҹҘиҜҶпјҢе°Ҹзј–йҖҡиҝҮе®һйҷ…жЎҲдҫӢеҗ‘еӨ§е®¶еұ•зӨәж“ҚдҪңиҝҮзЁӢпјҢж“ҚдҪңж–№жі•з®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәпјҢеёҢжңӣиҝҷзҜҮвҖңMysqlиЎЁиҝһжҺҘзҡ„жү§иЎҢжөҒзЁӢжҳҜд»Җд№ҲвҖқж–Үз« иғҪеё®еҠ©еӨ§е®¶и§ЈеҶій—®йўҳгҖӮ
1. еүҚиЁҖ
еҜ№дәҺиҝһжҺҘж“ҚдҪңпјҢй©ұеҠЁиЎЁе’Ңиў«й©ұеҠЁиЎЁзҡ„е…іиҒ”жқЎд»¶жҲ‘们ж”ҫеңЁonеҗҺйқўпјҢеҰӮжһңйўқеӨ–еўһеҠ еҜ№й©ұеҠЁиЎЁе’Ңиў«й©ұеҠЁиЎЁзҡ„иҝҮж»ӨжқЎд»¶пјҢж”ҫеҲ°onжҲ–иҖ…whereеҗҺйқўйғҪдёҚдјҡжҠҘй”ҷпјҢдҪҶжҳҜеҫ—еҲ°зҡ„з»“жһңйӣҶеҚҙжҳҜдёҚдёҖж ·зҡ„пјҹпјҹпјҹ
1.1 mysqlиҝһжҺҘзҡ„еҺҹзҗҶ
дј—жүҖе‘ЁзҹҘпјҢmysqlжҳҜеҹәдәҺеөҢеҘ—еҫӘзҺҜиҝһжҺҘпјҲNested-Loop JoinпјҢжҡӮдёҚиҖғиҷ‘дјҳеҢ–з®—жі•пјүз®—жі•жқҘиҝӣиЎҢиЎЁд№Ӣй—ҙзҡ„иҝһжҺҘж“ҚдҪңзҡ„пјҢеӨ§иҮҙиҝҮзЁӢеҰӮдёӢпјҡ
дјӘд»Јз ҒеҰӮдёӢпјҡ
for each row in t1 { // йҒҚеҺҶж»Ўи¶іеҜ№t1еҚ•иЎЁжҹҘиҜўз»“жһңйӣҶдёӯзҡ„жҜҸдёҖжқЎзәӘеҪ•
for each row in t2 { // еҜ№дәҺжҹҗжқЎt1зәӘеҪ•пјҢйҒҚеҺҶж»Ўи¶іеҜ№t2еҚ•иЎЁжҹҘиҜўз»“жһңйӣҶдёӯзҡ„жҜҸдёҖжқЎзәӘеҪ•
if row satisfies join conditions, send to client
}
}1.2 show warningsе‘Ҫд»Ө
жҲ‘们еҶҷзҡ„sqlиҜӯеҸҘпјҢеңЁз»ҸиҝҮдјҳеҢ–еҷЁдјҳеҢ–еҗҺжүҚдјҡдәӨз»ҷжү§иЎҢеҷЁжү§иЎҢпјҢиҖҢshow warningsе‘Ҫд»ӨеҲҷеҸҜд»Ҙеё®еҠ©жҲ‘们иҺ·еҫ—дјҳеҢ–еҷЁдјҳеҢ–еҗҺзҡ„sqlгҖӮ
2. еҮҶеӨҮе·ҘдҪң
иЎЁз»“жһ„еҰӮдёӢпјҡ
CREATE TABLE `student` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`stu_code` varchar(20) NOT NULL DEFAULT '',
`stu_name` varchar(30) NOT NULL DEFAULT '',
`stu_sex` varchar(10) NOT NULL DEFAULT '',
`stu_age` int(10) NOT NULL DEFAULT '0',
`stu_dept` varchar(30) NOT NULL DEFAULT '',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `uq_stu_code` (`stu_code`)
) ENGINE=InnoDB AUTO_INCREMENT=43 DEFAULT CHARSET=utf8mb4
CREATE TABLE `course` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`cou_code` varchar(20) NOT NULL DEFAULT '',
`cou_name` varchar(50) NOT NULL DEFAULT '',
`cou_score` int(10) NOT NULL DEFAULT '0',
`stu_code` varchar(20) NOT NULL DEFAULT '',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_stu_code_cou_code` (`stu_code`,`cou_code`)
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8mb4
иЎЁж•°жҚ®еҰӮдёӢпјҡ
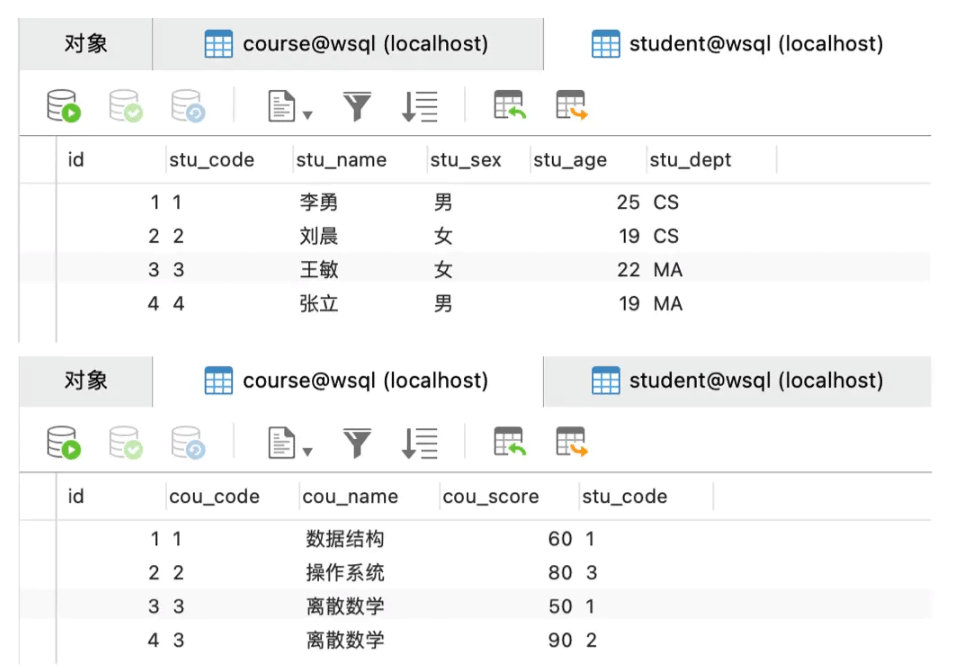
3. inner joinеҶ…иҝһжҺҘonгҖҒwhereзҡ„еҢәеҲ«
sqlеҰӮдёӢпјҡ
select * from student
inner join course on student.stu_code = course.stu_code
and student.stu_code >= 3 and course.cou_score >= 80;
жү§иЎҢexplain+sqlе‘Ҫд»Өпјҡ

жү§иЎҢshow warningsе‘Ҫд»Өпјҡ

еҲҶжһҗпјҡд»Һshow warningsеҲҶжһҗжқҘзңӢпјҢеҜ№дәҺinner joinиҝһжҺҘпјҢз»ҸиҝҮдјҳеҢ–еҷЁдјҳеҢ–еҗҺпјҢonиҝһжҺҘжқЎд»¶дјҡиҪ¬еҢ–дёәwhereпјҒд№ҹе°ұжҳҜиҜҙеҶ…иҝһжҺҘдёӯзҡ„whereе’ҢonжҳҜзӯүд»·зҡ„гҖӮ
4. left joinе·ҰиҝһжҺҘonгҖҒwhereзҡ„еҢәеҲ«
4.1 whereй©ұеҠЁиЎЁиҝҮж»ӨжқЎд»¶
sqlеҰӮдёӢпјҡ
select * from student
left join course on student.stu_code = course.stu_code
where student.stu_code >= 3;
жү§иЎҢexplain+sqlе‘Ҫд»Өпјҡ

жү§иЎҢshow warningsе‘Ҫд»Өпјҡ

з»“жһңйӣҶпјҡ

еҲҶжһҗпјҡд»ҺexplainеҲҶжһҗзңӢеҮәпјҢstudentдҪңдёәй©ұеҠЁиЎЁпјҢжҠҠstudent.stu_code >= 3дҪңдёәиҝҮж»ӨжқЎд»¶иҝӣиЎҢе…ЁиЎЁжү«жҸҸпјҢ然еҗҺжҠҠжҹҘиҜўеҲ°зҡ„жҜҸжқЎзәӘеҪ•зҡ„student.stu_codeпјҲд№ҹе°ұжҳҜonжқЎд»¶йҮҢйқўзҡ„пјүеҲҶеҲ«дҪңдёәиҝҮж»ӨжқЎд»¶и®©иў«й©ұеҠЁиЎЁcourseеҒҡеҚ•иЎЁжҹҘиҜўгҖӮ
4.2 onй©ұеҠЁиЎЁиҝҮж»ӨжқЎд»¶
sqlеҰӮдёӢпјҡ
select * from student
left join course on student.stu_code = course.stu_code
and student.stu_code >= 3;
жү§иЎҢexplain+sqlе‘Ҫд»Өпјҡ

жү§иЎҢshow warningsе‘Ҫд»Өпјҡ

з»“жһңйӣҶпјҡ

д»Һз»“жһңйӣҶжқҘзңӢпјҢstudent.stu_code >= 3并жңӘз”ҹж•ҲпјҢдёәд»Җд№Ҳпјҹ
еҲҶжһҗпјҡд»ҺexplainеҲҶжһҗзңӢеҮәпјҢstudentдҪңдёәй©ұеҠЁиЎЁпјҢеҒҡе…ЁиЎЁжү«жҸҸпјҢ然еҗҺжҠҠжҹҘиҜўеҲ°зҡ„жҜҸжқЎи®°еҪ•зҡ„student.stu_codeе’Ңstudent.stu_code >= 3пјҲд№ҹе°ұжҳҜonжқЎд»¶йҮҢйқўзҡ„пјүеҲҶеҲ«еҒҡдёәиҝҮж»ӨжқЎд»¶и®©иў«й©ұеҠЁиЎЁеҒҡеҚ•иЎЁжҹҘиҜўпјӣжӯӨж—¶student.stu_code >= 3еҜ№й©ұеҠЁиЎЁжҳҜдёҚиҝҮж»Өзҡ„пјҢд»…еңЁиҝһжҺҘиў«й©ұеҠЁиЎЁж—¶з”ҹж•ҲпјҢжҹҘиҜўдёҚеҲ°з¬ҰеҗҲзәӘеҪ•иҖҢиҝ”еӣһNULLпјҒ
4.3 onиў«й©ұеҠЁиЎЁиҝҮж»ӨжқЎд»¶
sqlеҰӮдёӢпјҡ
select * from student
left join course on student.stu_code = course.stu_code
and course.cou_score >= 80;
жү§иЎҢexplain+sqlе‘Ҫд»Өпјҡ

жү§иЎҢshow warningsе‘Ҫд»Өпјҡ

з»“жһңйӣҶпјҡ

еҲҶжһҗпјҡд»ҺexplainеҲҶжһҗзңӢеҮәпјҢstudentдҪңдёәй©ұеҠЁиЎЁпјҢеҒҡе…ЁиЎЁжү«жҸҸпјҢ然еҗҺжҠҠжҹҘиҜўеҲ°зҡ„жҜҸжқЎи®°еҪ•зҡ„student.stu_codeе’Ңcourse.cou_score >= 80пјҲд№ҹе°ұжҳҜonжқЎд»¶йҮҢйқўзҡ„пјүеҲҶеҲ«еҒҡдёәиҝҮж»ӨжқЎд»¶и®©иў«й©ұеҠЁиЎЁеҒҡеҚ•иЎЁжҹҘиҜўпјӣ
4.4 whereиў«й©ұеҠЁиЎЁиҝҮж»ӨжқЎд»¶
sqlеҰӮдёӢпјҡ

жү§иЎҢexplain+sqlе‘Ҫд»Өпјҡ

жү§иЎҢshow warningsе‘Ҫд»Өпјҡ

з»“жһңйӣҶпјҡ

д»Һshow warningsеҲҶжһҗжқҘзңӢпјҹleft joinиҝһжҺҘеҸҳжҲҗдәҶinner joinиҝһжҺҘпјҹ
еҲҶжһҗпјҡд»Һshow warningsеҲҶжһҗзңӢеҮәпјҢеҰӮжһңиў«й©ұеҠЁиЎЁжңүиҝҮж»ӨжқЎд»¶еңЁwhereпјҢйӮЈд№Ҳleft joinдјҡиў«еӨұж•ҲпјҢиў«дјҳеҢ–жҲҗinner joinиҝһжҺҘгҖӮжүҖд»Ҙиў«й©ұеҠЁиЎЁзҡ„иҝҮж»ӨжқЎд»¶еә”иҜҘж”ҫеңЁonиҖҢдёҚжҳҜwhereгҖӮ
е…ідәҺвҖңMysqlиЎЁиҝһжҺҘзҡ„жү§иЎҢжөҒзЁӢжҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶзӮ№гҖӮ





