这篇文章主要讲解了“MySQL索引结构实例分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“MySQL索引结构实例分析”吧!
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。
优点:
1、类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本。
2、通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
缺点:
1、虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
2、实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的
索引举例:(用树结构做索引)
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址。
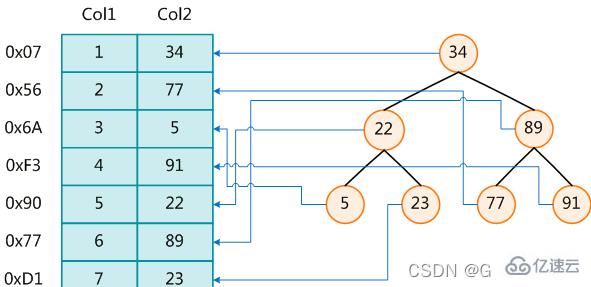
为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录。
如何通过索引加快数据库表的查询速度呢?为了方便讲解,我们限定于数据库表只包含下面这样两个查询需求:
1、select* from user where id=1234;
2、select *from user where id>1234 and id<2345;(按区间)
哈希表按值查询的性能很好,时间复杂度是O(1),但它不能支持按照区间快速查找数据,因此无法满足要求。同理,尽管平衡二叉查找树查询性能很高,时间复杂度为O(logn),而且对树进行中序遍历,可以输出有序的数据序列,但也无法满足按照区间快速查找数据的需求。
为了支持按照区间快速查找数据,我们对二叉查找树进行改造,将二叉查找树的叶子节点用链表串起来,如果要查找某个区间的数据,只需要用区间的起始值,在树中进行查找,当定位到有序链表中的某个节点之后,再从这个节点开始顺着有序链表往后遍历,直到有序链表中的节点数据值大于区间终止值为止。
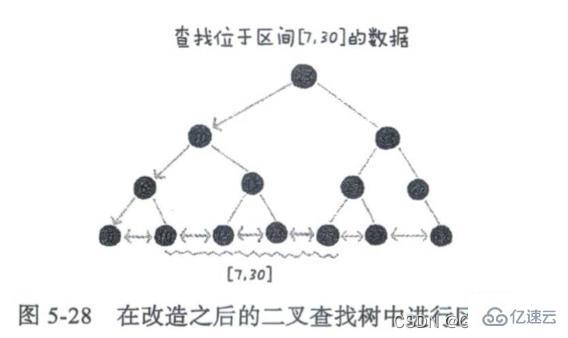
又因为树上的很多操作的时间复杂程度与树的高度成正比,降低的树的高度,就能减少磁盘IO操作。因此我们把索引构建成m叉树(m>2),详细介绍可看后文。
在介绍B+树之前,先来了解一下B树。
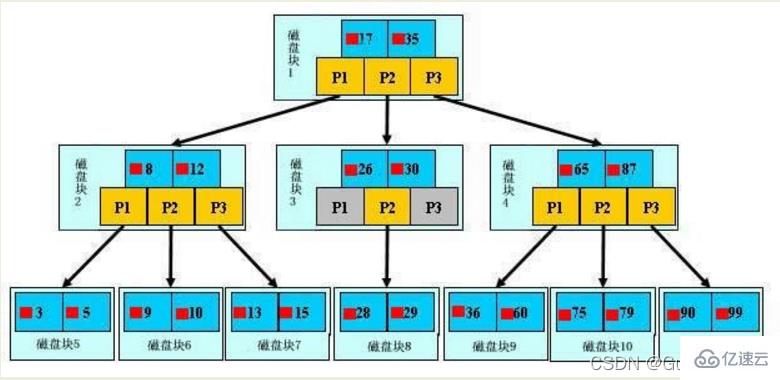
1、初始化介绍
一颗b树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3。P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
注意:
真实的数据只存在于叶子节点,即3、5、9、10、13、15、28、29、36、60、75、79、90、99。(而且是多条数据组成的数据区间:3~ 5,… … ,90~ 99)
非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
2、查找过程
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。
B+树和B树类似,B+树是B树的改进版。 即:m叉查找树与有序链表构建成的树就是B+树,也就是要存储的树索引
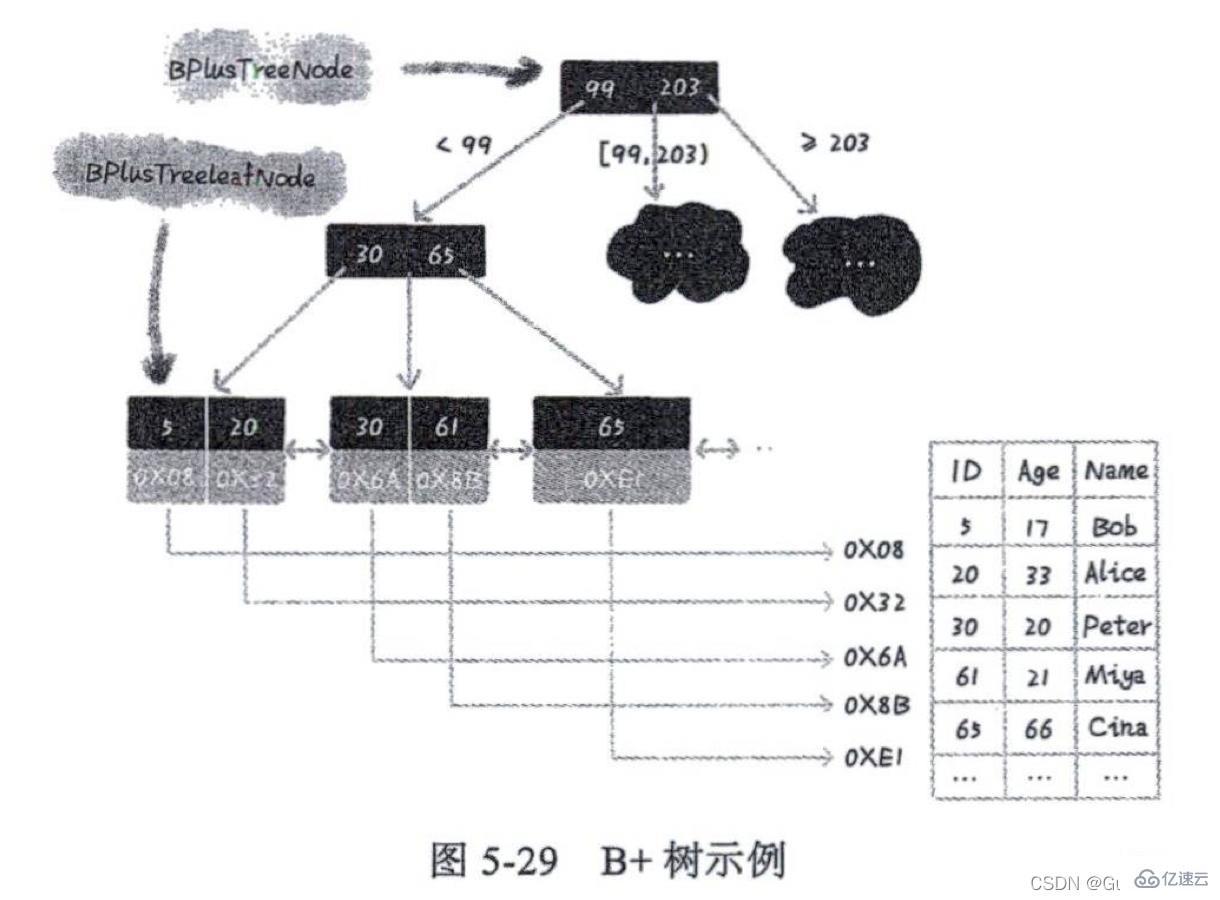
如图:B+树和B树的主要区别有以下两点:
1、B+树的叶子节点用链表来串联。 查找某个区间的数据,只需要用区间的起始值,在树中进行查找,当定位到有序链表中的某个节点之后,再从这个节点开始顺着有序链表往后遍历,直到有序链表中的节点数据值大于区间终止值为止。
2、B+树中的任何节点都不存储真实数据,只是用来索引。 B树直接通过叶子节点获取到数据;而B+树每个叶子节点存储数据行的键值和地址信息,当查询到某个叶子节点时,通过叶子节点的地址找到真实的数据信息。
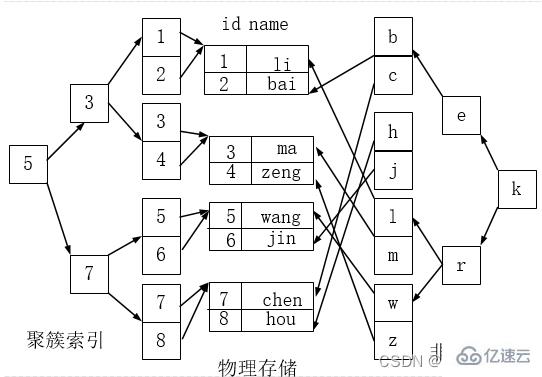
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。 术语‘聚簇’表示数据行和相邻的键值聚簇的存储在一起。
聚簇索引的好处:
按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不不用从多个数据块中提取数据,所以节省了大量的io操作。
聚簇索引的限制:
1、对于mysql数据库目前只有innodb数据引擎支持聚簇索引,而Myisam并不支持聚簇索引。
2、由于数据物理存储排序方式只能有一种,所以每个Mysql的表只能有一个聚簇索引。一般情况下就是该表的主键。
3、为了充分利用聚簇索引的聚簇的特性,所以innodb表的主键列尽量选用有序的顺序id,而不建议用无序的id,比如uuid这种。
如下图,左侧的索引就是聚簇索引,因为数据行在磁盘的排列和索引排序保持一致。
单值索引
即一个索引只包含单个列,一个表可以有多个单列索引
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name) ); 单独建单值索引: CREATE INDEX idx_customer_name ON customer(customer_name); 删除索引: DROP INDEX idx_customer_name on customer;
唯一索引
索引列的值必须唯一,但允许有空值
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no) ); 单独建唯一索引: CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no); 删除索引: DROP INDEX idx_customer_no on customer ;
主键索引
设定为主键后数据库会自动建立索引,innodb为聚簇索引
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); CREATE TABLE customer2 ( id INT(10) UNSIGNED , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); 单独建主键索引: ALTER TABLE customer add PRIMARY KEY customer(customer_no); 删除建主键索引: ALTER TABLE customer drop PRIMARY KEY ; 修改建主键索引: 必须先删除掉(drop)原索引,再新建(add)索引
复合索引
即一个索引包含多个列
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_name), KEY (customer_no,customer_name) ); 单独建索引: CREATE INDEX idx_no_name ON customer(customer_no,customer_name); 删除索引: DROP INDEX idx_no_name on customer ;
哪些情况需要创建索引
1、主键自动建立唯一索引
2、频繁作为查询条件的字段应该创建索引
3、查询中与其它表关联的字段,外键关系建立索引
4、单键/组合索引的选择问题, 组合索引性价比更高
5、查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
6、查询中统计或者分组字段
哪些情况不要创建索引
1、表记录太少
2、经常增删改的表或者字段 原因:提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
3、Where条件里用不到的字段不创建索引
4、过滤性不好的不适合建索引
感谢各位的阅读,以上就是“MySQL索引结构实例分析”的内容了,经过本文的学习后,相信大家对MySQL索引结构实例分析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





