这篇文章主要介绍“Redis特殊数据类型之stream怎么应用”,在日常操作中,相信很多人在Redis特殊数据类型之stream怎么应用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Redis特殊数据类型之stream怎么应用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Redis Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;
List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。
基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
Stream 消息队列操作命令:
XADD : 插入消息,保证有序,可以自动生成全局唯一 ID
XDEL : 根据消息 ID 删除消息;
DEL : 删除整个 Stream;
# XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|id field value [field value ...]
127.0.0.1:6379> XADD s1 * name sid10t
"1665047636078-0"
127.0.0.1:6379> XADD s1 * name sidiot
"1665047646214-0"
# XDEL key id [id ...]
127.0.0.1:6379> XDEL s1 1665047646214-0
(integer) 1
# DEL key [key ...]
127.0.0.1:6379> DEL s1
(integer) 1

XLEN : 查询消息长度;
XREAD : 用于读取消息,可以按 ID 读取数据;
XRANGE : 读取区间消息;
XTRIM : 裁剪队列消息个数;
# XLEN key
127.0.0.1:6379> XLEN s1
(integer) 2
# XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
127.0.0.1:6379> XREAD streams s1 0-0
1) 1) "s1"
2) 1) 1) "1665047636078-0"
2) 1) "name"
2) "sid10t"
2) 1) "1665047646214-0"
2) 1) "name"
2) "sidiot"
127.0.0.1:6379> XREAD count 1 streams s1 0-0
1) 1) "s1"
2) 1) 1) "1665047636078-0"
2) 1) "name"
2) "sid10t"
# XADD 了一条消息之后的扩展
127.0.0.1:6379> XREAD streams s1 1665047636078-0
1) 1) "s1"
2) 1) 1) "1665047646214-0"
2) 1) "name"
2) "sidiot"
2) 1) "1665053702766-0"
2) 1) "age"
2) "18"
# XRANGE key start end [COUNT count]
127.0.0.1:6379> XRANGE s1 - +
1) 1) "1665047636078-0"
2) 1) "name"
2) "sid10t"
2) 1) "1665047646214-0"
2) 1) "name"
2) "sidiot"
3) 1) "1665053702766-0"
2) 1) "age"
2) "18"
127.0.0.1:6379> XRANGE s1 1665047636078-0 1665047646214-0
1) 1) "1665047636078-0"
2) 1) "name"
2) "sid10t"
2) 1) "1665047646214-0"
2) 1) "name"
2) "sidiot"
# XTRIM key MAXLEN|MINID [=|~] threshold [LIMIT count]
127.0.0.1:6379> XLEN s1
(integer) 3
127.0.0.1:6379> XTRIM s1 maxlen 2
(integer) 1
127.0.0.1:6379> XLEN s1
(integer) 2
XGROUP CREATE : 创建消费者组;
XREADGROUP : 按消费组形式读取消息;
XPENDING 和 XACK :
XPENDING 命令可以用来查询每个消费组内所有消费者「已读取、但尚未确认」的消息;
XACK 命令用于向消息队列确认消息处理已完成;
# XGROUP CREATE key groupname id|$ [MKSTREAM] [ENTRIESREAD entries_read]
# 需要注意的是,XGROUP CREATE 的 streams 必须是一个存在的 streams,否则会报错;
127.0.0.1:6379> XGROUP CREATE myStream cGroup-top 0-0
(error) ERR The XGROUP subcommand requires the key to exist. Note that for CREATE you may want to use the MKSTREAM option to create an empty stream automatically.
# 0-0 从头开始消费,$ 从尾开始消费;
127.0.0.1:6379> XADD myStream * name sid10t
"1665057823181-0"
127.0.0.1:6379> XGROUP CREATE myStream cGroup-top 0-0
OK
127.0.0.1:6379> XGROUP CREATE myStream cGroup-tail $
OK
# XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]
127.0.0.1:6379> XREADGROUP Group cGroup-top name count 2 STREAMS myStream >
1) 1) "myStream"
2) 1) 1) "1665058086931-0"
2) 1) "name"
2) "sid10t"
2) 1) "1665058090167-0"
2) 1) "name"
2) "sidiot"
消息队列
生产者通过 XADD 命令插入一条消息:
# * 表示让 Redis 为插入的数据自动生成一个全局唯一的 ID
# 往名称为 mymq 的消息队列中插入一条消息,消息的键是 name,值是 sid10t
127.0.0.1:6379> XADD mymq * name sid10t
"1665058759764-0"
插入成功后会返回全局唯一的 ID:"1665058759764-0"。消息的全局唯一 ID 由两部分组成:
第一部分 “1665058759764” 是数据插入时,以毫秒为单位计算的当前服务器时间;
第二部分表示插入消息在当前毫秒内的消息序号,这是从 0 开始编号的。例如,“1665058759764-0” 就表示在 “1665058759764” 毫秒内的第 1 条消息。
消费者通过 XREAD 命令从消息队列中读取消息时,可以指定一个消息 ID,并从这个消息 ID 的下一条消息开始进行读取(注意是输入消息 ID 的下一条信息开始读取,不是查询输入 ID 的消息)。
127.0.0.1:6379> XREAD STREAMS mymq 1665058759764-0
(nil)
127.0.0.1:6379> XREAD STREAMS mymq 1665058759763-0
1) 1) "mymq"
2) 1) 1) "1665058759764-0"
2) 1) "name"
2) "sid10t"
如果想要实现阻塞读(当没有数据时,阻塞住),可以调用 XRAED 时设定 BLOCK 配置项,实现类似于 BRPOP 的阻塞读取操作。
比如,下面这命令,设置了 BLOCK 10000 的配置项,10000 的单位是毫秒,表明 XREAD 在读取最新消息时,如果没有消息到来,XREAD 将阻塞 10000 毫秒(即 10 秒),然后再返回。
# 命令最后的 $ 符号表示读取最新的消息
127.0.0.1:6379> XREAD BLOCK 10000 STREAMS mymq $
(nil)
(10.01s)
Stream 的基础方法,使用 xadd 存入消息和 xread 循环阻塞读取消息的方式可以实现简易版的消息队列,交互流程如下图所示:
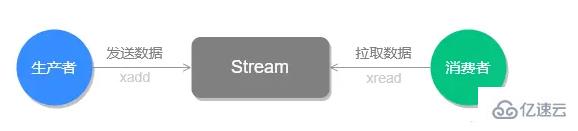
前面介绍的这些操作 List 也支持的,接下来看看 Stream 特有的功能。
Stream 可以以使用 XGROUP 创建消费组,创建消费组之后,Stream 可以使用 XREADGROUP 命令让消费组内的消费者读取消息。
创建两个消费组,这两个消费组消费的消息队列是 mymq,都指定从第一条消息开始读取:
# 创建一个名为 group1 的消费组,0-0 表示从第一条消息开始读取。
127.0.0.1:6379> XGROUP CREATE mymq group1 0-0
OK
# 创建一个名为 group2 的消费组,0-0 表示从第一条消息开始读取。
127.0.0.1:6379> XGROUP CREATE mymq group2 0-0
OK
消费组 group1 内的消费者 consumer1 从 mymq 消息队列中读取所有消息的命令如下:
# 命令最后的参数“>”,表示从第一条尚未被消费的消息开始读取。
127.0.0.1:6379> XREADGROUP GROUP group1 consumer1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1665058759764-0"
2) 1) "name"
2) "sid10t"
消息队列中的消息一旦被消费组里的一个消费者读取了,就不能再被该消费组内的其他消费者读取了,即同一个消费组里的消费者不能消费同一条消息。
比如说,我们执行完刚才的 XREADGROUP 命令后,再执行一次同样的命令,此时读到的就是空值了:
127.0.0.1:6379> XREADGROUP GROUP group1 consumer1 STREAMS mymq >
(nil)
但是,不同消费组的消费者可以消费同一条消息(但是有前提条件,创建消息组的时候,不同消费组指定了相同位置开始读取消息) 。
比如说,刚才 group1 消费组里的 consumer1 消费者消费了一条 id 为 1665058759764-0 的消息,现在用 group2 消费组里的 consumer1 消费者消费消息:
127.0.0.1:6379> XREADGROUP GROUP group2 consumer1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1665058759764-0"
2) 1) "name"
2) "sid10t"
因为我创建两组的消费组都是从第一条消息开始读取,所以可以看到第二组的消费者依然可以消费 id 为 1665058759764-0 的这一条消息。因此,不同的消费组的消费者可以消费同一条消息。
使用消费组的目的是让组内的多个消费者共同分担读取消息,所以,我们通常会让每个消费者读取部分消息,从而实现消息读取负载在多个消费者间是均衡分布的。
例如,我们执行下列命令,让 group2 中的 consumer1、2、3 各自读取一条消息。
# 让 group2 中的 consumer1 从 mymq 消息队列中消费一条消息
127.0.0.1:6379> XREADGROUP GROUP group2 consumer1 COUNT 1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1665060632864-0"
2) 1) "name"
2) "sid10t"
# 让 group2 中的 consumer2 从 mymq 消息队列中消费一条消息
127.0.0.1:6379> XREADGROUP GROUP group2 consumer2 COUNT 1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1665060633903-0"
2) 1) "name"
2) "sid10t"
# 让 group2 中的 consumer3 从 mymq 消息队列中消费一条消息
127.0.0.1:6379> XREADGROUP GROUP group2 consumer3 COUNT 1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1665060634962-0"
2) 1) "name"
2) "sid10t"
基于 Stream 实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息?
Streams 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用 XACK 命令通知 Streams “消息已经处理完成”。
消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 XACK 命令确认消息已经被消费完成,整个流程的执行如下图所示:
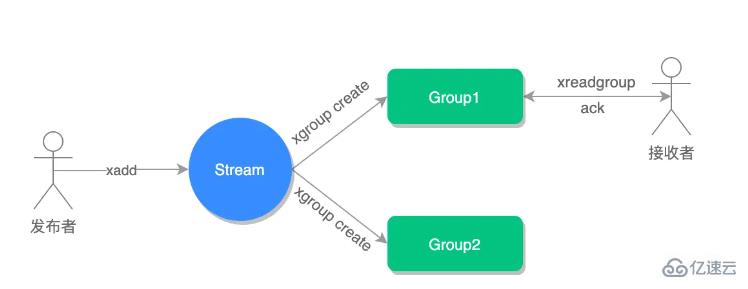
如果消费者没有成功处理消息,它就不会给 Streams 发送 XACK 命令,消息仍然会留存。此时,消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。
例如,我们来查看一下 group2 中各个消费者已读取、但尚未确认的消息个数,命令如下:
127.0.0.1:6379> XPENDING mymq group2
1) (integer) 4
2) "1665058759764-0"
3) "1665060634962-0"
4) 1) 1) "consumer1"
2) "2"
2) 1) "consumer2"
2) "1"
3) 1) "consumer3"
2) "1"
如果想查看某个消费者具体读取了哪些数据,可以执行下面的命令:
# 查看 group2 里 consumer2 已从 mymq 消息队列中读取了哪些消息
127.0.0.1:6379> XPENDING mymq group2 - + 10 consumer2
1) 1) "1665060633903-0"
2) "consumer2"
3) (integer) 1888805
4) (integer) 1
可以看到,consumer2 已读取的消息的 ID 是 1665060633903-0。
一旦消息 1665060633903-0 被 consumer2 处理了,consumer2 就可以使用 XACK 命令通知 Streams,然后这条消息就会被删除。
127.0.0.1:6379> XACK mymq group2 1665060633903-0
(integer) 1
当我们再使用 XPENDING 命令查看时,就可以看到,consumer2 已经没有已读取、但尚未确认处理的消息了。
127.0.0.1:6379> XPENDING mymq group2 - + 10 consumer2
(empty array)
好了,基于 Stream 实现的消息队列就说到这里了,小结一下:
消息保序:XADD/XREAD
阻塞读取:XREAD block
重复消息处理:Stream 在使用 XADD 命令,会自动生成全局唯一 ID;
消息可靠性:内部使用 PENDING List 自动保存消息,使用 XPENDING 命令查看消费组已经读取但是未被确认的消息,消费者使用 XACK 确认消息;
支持消费组形式消费数据
Redis 基于 Stream 消息队列与专业的消息队列有哪些差距?
一个专业的消息队列,必须要做到两大块:
消息不可丢。
消息可堆积。
1、Redis Stream 消息会丢失吗?
使用一个消息队列,其实就分为三大块:生产者、队列中间件、消费者,所以要保证消息就是保证三个环节都不能丢失数据。
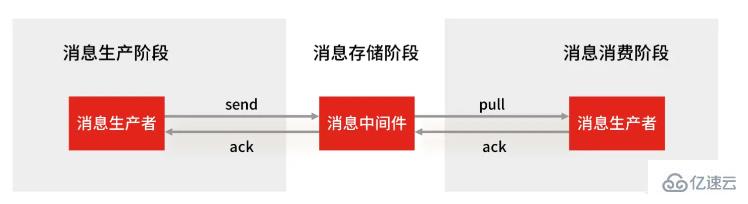
Redis Stream 消息队列能不能保证三个环节都不丢失数据?
Redis 生产者会不会丢消息?生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。 从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 ( MQ 中间件) 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,如果返回异常则进行消息重发,那么这个阶段是不会出现消息丢失的。
Redis 消费者会不会丢消息?不会,因为 Stream ( MQ 中间件)会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,但是未被确认的消息。消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。等到消费者执行完业务逻辑后,再发送消费确认 XACK 命令,也能保证消息的不丢失。
Redis 消息中间件会不会丢消息?会,Redis 在以下 2 个场景下,都会导致数据丢失:
AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能;
主从复制也是异步的,主从切换时,也存在丢失数据的可能 (opens new window)。
可以看到,Redis 在队列中间件环节无法保证消息不丢。像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
2、Redis Stream 消息可堆积吗?
Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。
所以 Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。
当指定队列最大长度时,队列长度超过上限后,旧消息会被删除,只保留固定长度的新消息。这么来看,Stream 在消息积压时,如果指定了最大长度,还是有可能丢失消息的。
但 Kafka、RabbitMQ 专业的消息队列它们的数据都是存储在磁盘上,当消息积压时,无非就是多占用一些磁盘空间。
因此,把 Redis 当作队列来使用时,会面临的 2 个问题:
Redis 本身可能会丢数据;
面对消息挤压,内存资源会紧张;
所以,能不能将 Redis 作为消息队列来使用,关键看你的业务场景:
如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧。
补充:Redis 发布/订阅机制为什么不可以作为消息队列?
发布订阅机制存在以下缺点,都是跟丢失数据有关:
发布/订阅机制没有基于任何数据类型实现,所以不具备「数据持久化」的能力,也就是发布/订阅机制的相关操作,不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,发布/订阅机制的数据也会全部丢失。
发布订阅模式是 “发后既忘” 的工作模式,如果有订阅者离线重连之后不能消费之前的历史消息。
当消费端有一定的消息积压时,也就是生产者发送的消息,消费者消费不过来时,如果超过 32M 或者是 60s 内持续保持在 8M 以上,消费端会被强行断开,这个参数是在配置文件中设置的,默认值是 client-output-buffer-limit pubsub 32mb 8mb 60。
所以,发布/订阅机制只适合即使通讯的场景,比如构建哨兵集群 (opens new window)的场景采用了发布/订阅机制。
到此,关于“Redis特殊数据类型之stream怎么应用”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





