本篇内容介绍了“hive组件能提供什么服务”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
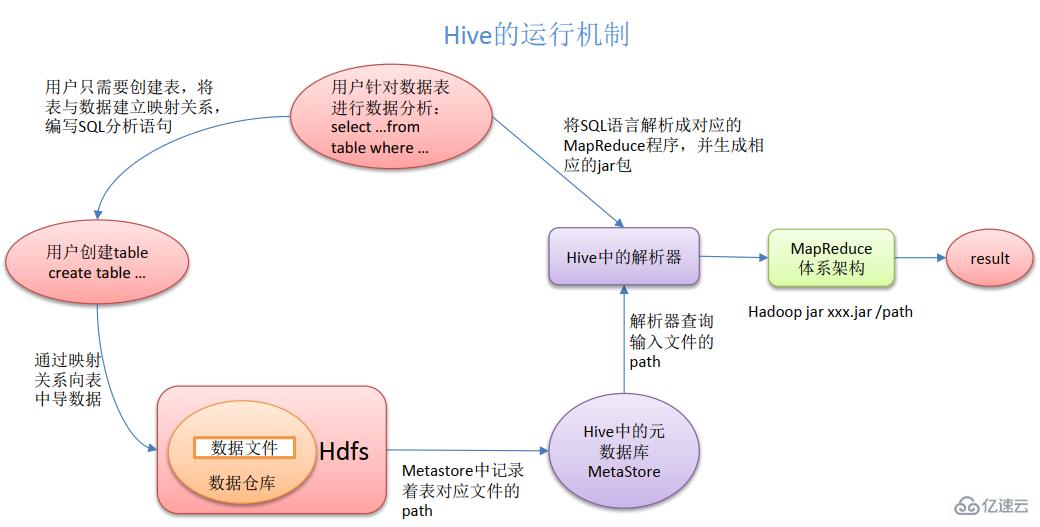
hive组件可提供的服务:1、把SQL语句转化成mapreduce代码;2、可以对数据进行存储,存储使用 HDFS;3、可以对数据进行计算,计算使用MapReduce。hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载;hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
在搭建数据仓库时,Hive组件在其中发挥了非常关键的作用,我们知道Hive是一个基于Hadoop的重要数据仓库工具,但具体如何应用则需要我们进一步进行探索。
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析
1.把SQL语句转化成mapreduce代码
2.可以对数据进行存储 存储使用 HDFS
3.可以对数据进行计算 计算使用 MapReduce
a.Hive的优点
(1)简单容易上手:提供了类SQL查询语言HQL
(2)可扩展:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统)
一般情况下不需要重启服务Hive可以自由的扩展集群的规模。
(3)提供统一的元数据管理
(4)延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
(5)容错:良好的容错性,节点出现问题SQL仍可完成执行
b.Hive的缺点
(1)hive的HQL表达能力有限
1)迭代式算法无法表达,比如pagerank
2)数据挖掘方面,比如kmeans
(2)hive的效率比较低
1)hive自动生成的mapreduce作业,通常情况下不够智能化
2)hive调优比较困难,粒度较粗
3)hive可控性差
(3)Hive不支持事物。主要用作OLAP(联机分析处理)

1) Hive 处理的数据存储在 HDFS
2) Hive 分析数据底层的默认实现是 MapReduce
3) 执行程序运行在 Yarn 上
总结:相当于是hadoop的一个客户端的作用。
(1)Hive与传统数据库的比较
Hive用于海量数据的离线数据分析。Hive具有sql数据库的外表,但应用场景完全不同,Hive只适合用来做批量数据统计分析。
(2)Hive的优势
Hive利用HDFS存储数据,利用MapReduce查询分析数据。因为直接使用Hadoop MapReduce处理数据,会面临人员学习成本太高的问题,而且MapReduce实现复杂查询逻辑开发难度太大。而使用Hive,操作接口采用类SQL语法,提供快速开发的能力的同时还避免了去写MapReduce,从而减少开发人员的学习成本,功能扩展更加方便。
Hive解决了大数据的查询功能,让不会写MR的人也能使用MR,它的本质就是将HQL转换为MR. 它的底层走的是MR,写MR效率低,而且痛苦,Hive的出现就为JAVAEE的兄弟带来了捷径和福音.
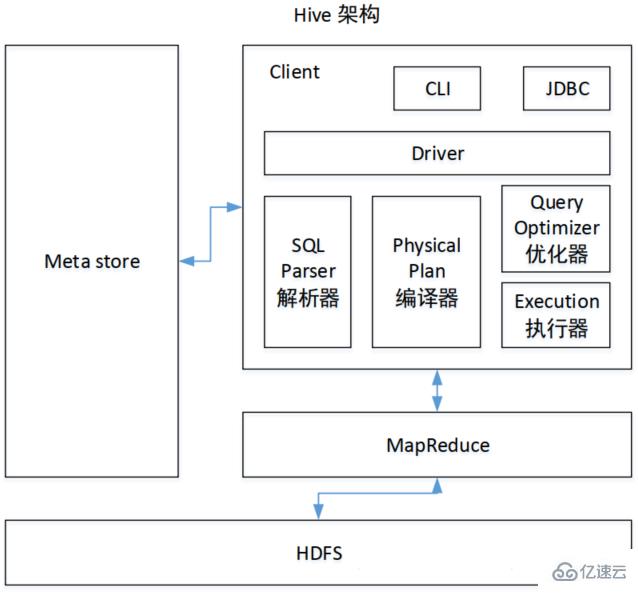
1. 用户接口: Client
CLI(hive shell)、 JDBC/ODBC(java 访问 hive)、 WEBUI(浏览器访问 hive)
2. 元数据: Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表
的类型(是否是外部表)、表的数据所在目录等;
元数据: Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表
的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore。
3. Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4. 驱动器: Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用
第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存
在、 SQL 语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来
说,就是 MR/Spark。
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则
可以将数据保存在块设备或者本地文件系统中。
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。 因此, Hive
中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是
需要经常进行修改的,因此可以使用INSERT INTO … VALUES 添加数据,使用UPDATE … SET 修改数据。
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看, Hive 和数据库除了拥有类似的查询语言,再无类似之处。本节将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
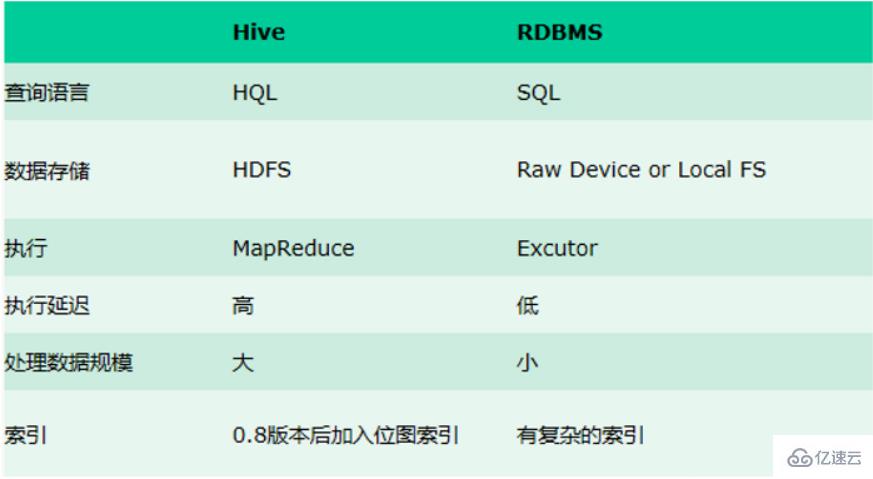
1、查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
2、数据存储位置Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3 、数据更新:由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。 因此, Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。 而数据库中的数据通常是需 要 经 常 进 行 修 改 的 , 因 此 可 以 使 用 INSERT INTO … VALUES 添 加 数 据 , 使用 UPDATE … SET 修改数据。
4 、索引:Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些 Key 建立索引。 Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问, Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
5、 执行:Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
6、执行延迟:Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候, Hive 的并行计算显然能体现出优势。
7 、可扩展性:由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是一致的(世界上最大的 Hadoop 集群在 Yahoo!, 2009 年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
8、 数据规模:由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
“hive组件能提供什么服务”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



