本篇内容介绍了“mysql如何实现合并结果集并去除重复值”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
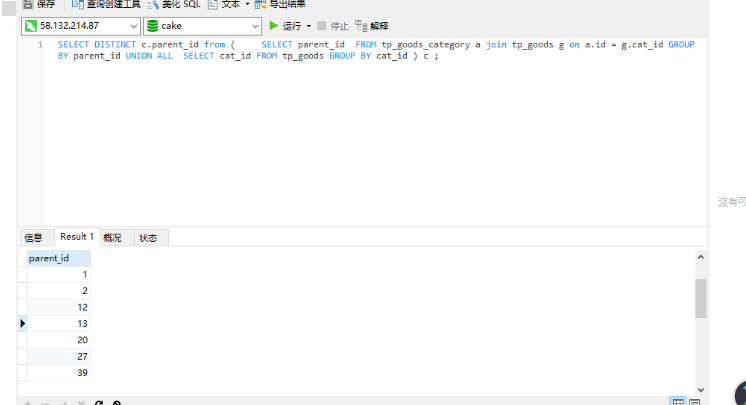
SELECT DISTINCT c.parent_id from ( SELECT parent_id FROM tp_goods_category a join tp_goods g on a.id = g.cat_id GROUP BY parent_id UNION ALL SELECT cat_id FROM tp_goods GROUP BY cat_id ) c;先去除每个结果集中的重复值 以 group by 方式除去
SELECT parent_id FROM tp_goods_category a join tp_goods g on a.id = g.cat_id GROUP BY parent_id
SELECT cat_id FROM tp_goods GROUP BY cat_id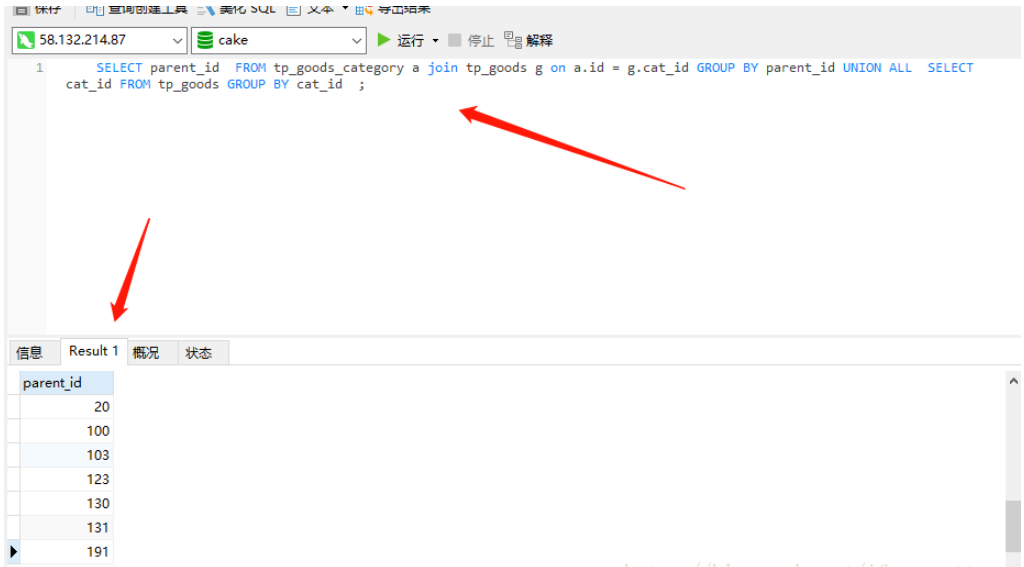
然后合并两个结果集 生成一个新的结果集 (或者可以成为新表) 在 使用DISTINCT 去除合并结果集中的重复值 注意 必须给 新结果集取一个别名 比如例子中的 c

新的查询结果
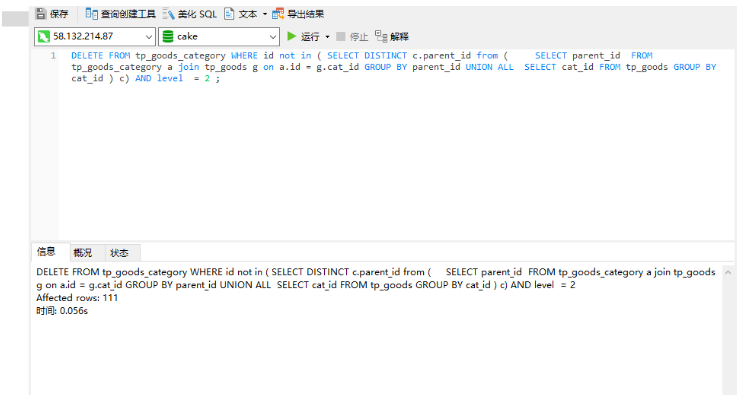
此语句为了删除分类表中 在goods表中不存在的 分类id 且 级别为第二级别
我需要在一个sql的执行结果中,显示两个或两个以上的where条件的结果(select 列的结构相同)。
考虑使用union,或union all 。
UNION 删除重复的记录再返回结果,即对整个结果集合使用了DISTINCT。结果中无重复数据。
UNION ALL 将各个结果合并后就返回,不删除重复记录。如果结果中有重复数据,则包含重复数据。
例如,
mysql> SELECT * FROM world.city where ID=2020 UNION SELECT * FROM world.city where ID=2020;
+------+-------+-------------+--------------+------------+
| ID | Name | CountryCode | District | Population |
+------+-------+-------------+--------------+------------+
| 2020 | Tieli | CHN | Heilongjiang | 265683 |
+------+-------+-------------+--------------+------------+
1 row in set (0.00 sec)
mysql> SELECT * FROM world.city where ID=2020 UNION ALL SELECT * FROM world.city where ID=2020;
+------+-------+-------------+--------------+------------+
| ID | Name | CountryCode | District | Population |
+------+-------+-------------+--------------+------------+
| 2020 | Tieli | CHN | Heilongjiang | 265683 |
| 2020 | Tieli | CHN | Heilongjiang | 265683 |
+------+-------+-------------+--------------+------------+
2 rows in set (0.00 sec)比如要对合并后的结果集进行ORDER BY,LIMIT等操作需要对合并对象单个的SELECT语句加上括号。
并且把整体结果的条件ORDER BY,LIMIT等放到最后一个SELECT的括号后面。
例如,
(SELECT * FROM world.city
WHERE CountryCode = 'JPN' AND Name LIKE 'nishi%')
UNION ALL
(SELECT * FROM world.city
WHERE CountryCode = 'CHN' AND Population >= 5000000)
LIMIT 5;从效率上说,UNION ALL 要比UNION快很多。
所以,如果可以确认合并的结果集中不包含重复的数据的话,或者需要的结果中即使包含重复也无所谓,那么就使用UNION ALL。
UNION
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算。
UNION在运行时先取出各个表/各个select的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
UNION ALL
UNION ALL只是简单的将结果合并后就返回。不涉及排序运算。
“mysql如何实现合并结果集并去除重复值”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



