Nagios官网:https://www.nagios.org/
nagios重状态和结果,支持告警,没有数据历史,不用数据库,不成图像,不支持web配置,也可以自己开发脚本定制个性化的监控,支持多插件。
监控日志:log_file=/var/log/nagios/nagios.log
Web访问原因:/etc/httpd/conf.d/nagios.conf
yum nagios默认路径/etc/nagios,同时httpd、php被作为依赖安装
yum install -y nagios-plugins #监控其它主机的插件
yum install -y nagios nagios-plugins-all #在/usr/lib/nagios/plugins下载一些关于监控命令的包,这样才会有状态
本机监控信息文件:/etc/nagios/objects/localhost.cfg
nagios-plugins-nrpe #用于和被监控别的主机通信,如监控负载,磁盘情况
nrpe #用来生成/etc/nagios/nrpe.cfg,监控本机和其它机器,也用于远程通信
nagios -v /etc/nagios/nagios.cfg #检测nagios.cfg是否正确
下载sendmail,并启动
告警试发邮件: mail -s "test" 463245818@qq.com
配置服务端:192.168.134.141
cd /usr/local/src/
wgethttp://www.lishiming.net/data/p_w_upload/forum/epel-release-6-8_32.noarch.rpm
rpm -ivh epel-release-6-8_32.noarch.rpm
yum install -y nagios nagios-plugins nagios-plugins-allnrpe nagios-plugins-nrpe #安装很多依赖包httpd、php
htpasswd -c /etc/nagios/passwd nagiosadmin #在web登陆是需要的账号、密码
nagios -v /etc/nagios/nagios.cfg #检查nagios配置文件
/etc/init.d/httpd start
/etc/init.d/nagios start #默认监控本机
通过web查看nagios
http://192.168.134.141/nagios/
客户端(监控其它机器):192.168.134.132
首先在被监控机器操作:192.168.134.132
cd /usr/local/src/
wgethttp://www.lishiming.net/data/p_w_upload/forum/epel-release-6-8_32.noarch.rpm
rpm -ivh epel-release-6-8_32.noarch.rpm
yum install -y nagios nagios-plugins nagios-plugins-allnrpe nagios-plugins-nrpe
vim /etc/nagios/nrpe.cfg
#找到并修改
allowed_hosts=127.0.0.1,192.168.134.135,192,168.134.141 #允许被谁监控
dont_blame_nrpe=1 #1为允许,0为不允许
#然后在服务端添加被监控的主机信息
vim /etc/nagios/conf.d/192.168.132.cfg
#添加内容
define host{
use linux-server #应用linux-server的属性,templates.cfg有定义
host_name web1 #主机名
alias 134.132 #主机别名
address 192.168.134.132 #被监控的主机地址,可为IP,也可是域名
}
define service{
use generic-service
host_name 192.168.134.132
service_description check_ping
check_command check_ping!100.0,20%!200.0,50%
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.134.132
service_description check_ssh
check_command check_ssh
max_check_attempts 5 ;当nagios检测到问题时,一共尝试检测5次都有问题才会告警,如果该数值为1,那么检测到问题立即告警
normal_check_interval 1 ;重新检测的时间间隔,单位是分钟,默认是3分钟
notification_interval 60;在服务出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你认为,所有的事件只需要一次通知就够>了,可以把这里的选项设为0。
}
define service{
use generic-service
host_name 192.168.134.132
service_description check_http
check_command check_http
max_check_attempts 5
normal_check_interval 1
}
nagios -v /etc/nagios/nagios.cfg
/etc/init.d/nagios restart
以上几个服务不依赖于客户端nrpe服务,在自己电脑上可以使用ping或者telnet探测远程任何一台机器是否存活,是否开启某个端口或服务。而当我们想要检测客户端的某个具体服务的情况时,就需要借助于nrpe了,比如想知道客户端机器的负载或者磁盘使用情况
check_nrpe和nrpe daemon的工作原理
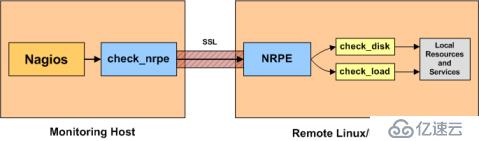
继续添加服务:客户端负载和磁盘使用情况,
首先在服务端:192.168.134.141
编辑服务端的命令文件和客户端文件
vim /etc/nagios/objects/commands.cfg
#增加
define command{
command_name check_nrpe
command_line $USER1$/check_nrpe-H $HOSTADDRESS$ -c $ARG1$
}
vim /etc/nagios/conf.d/192.168.132.cfg
#增加
define service{
use generic-service
host_name 192.168.134.141
service_description check_load
check_command check_nrpe!check_load
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.134.132
service_description check_disk_sda1
check_command check_nrpe!check_sda1
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.134.132
service_description check_disk_sda3
check_command check_nrpe!check_sda3
max_check_attempts 5
normal_check_interval 1
}
说明:check_nrpe!check_load:这里的check_nrpe就是在命令文件commands.cfg定义的,check_load是远程主机上的一个检测脚本,在/usr/lib/nagios/plugins这个文件下
客户端操作:192.168.134.132
vim /etc/nagios/nrpe.cfg
#搜索check_load,这行就是在服务端上要执行的脚本,可以手动执行试试
把check_hda1更改一下:check_hda1改为check_sda1,/dev/hda1改为/dev/sda1
#因为本机没有had盘,只有sda1
在添加一行
command[check_sda3]=/usr/lib/nagios/plugins/check_disk-w 20% -c 10% -p /dev/sda3
在客户端启动nrpe:/etc/init.d/nrpe start #用于和服务端通信
在服务端重启nagios:/etc/init.d/nagios restart
5、服务端配置告警
vim /etc/nagios/objects/contacts.cfg
#添加内容
define contact{
contact_name David ;联系人名称
use generic-contact ;引用templates.cfg定义
alias 12 ;联系人名称
email 463245818@qq.com ;联系人邮箱
}
define contact{
contact_name Nance
use generic-contact
alias 13
email 463245818@qq.com
}
define contactgroup{
contactgroup_name common ;组名称
alias 112
members David,Nance ;组成员
}
#然后打开
vim /etc/nagios/conf.d/192.168.134.132.cfg
#在比较重要的服务增加
define service{
use generic-service
host_name 192.168.134.132
service_description check_load
check_command check_nrpe!check_load
max_check_attempts 5
normal_check_interval 1
contact_groups common
notifications_enabled 1
notification_period 24x7
notification_options w,u,c,r
}
#其中
notifications_enabled 1 ;是否开启提醒功能。1为开启,0为禁用。一般,这个选项会在主配置文件(nagios.cfg)中定义,效果相同。
notification_period 24x7 ;发送提醒的时间段。非常重要的主机(服务)我定义为7×24,一般的主机(服务)就定义为上班时间。如果不在定义的时间段内,无论什么问题发生,都不>会发送提醒。
notification_options:w,u,c,r ;这个是service的状态。w为waning, u为unknown, c为critical, r为recover(恢复了),类似的还有一个 host对应的状态:d,u,r d = 状态为DOWN, u = 状态为UNREACHABLE, r = 状态恢复为OK,需要加入到host的定义配置里。
下载网址:https://sourceforge.net/
环境在源码安装好的lamp
排错查看日志
cat /usr/local/apache2/logs/error_log
cat /usr/local/nagios/var/nagios.log
打开apache的配置文件httpd.conf,找到4个,让它允许访问、支持php解析、默认php、ServerName
先创建nagios用户
useradd -s /sbin/nologin nagios
mkdir /usr/local/nagios
chown nagios:nagios /usr/local/nagios/
对于nrpe的版本下载v2.15,check_nrpe可以和nrpe daemon通信
V3.0.1自己感觉很多不足,check_nrpe和nrpe daemon不能通信,编译的参数也不同,3.0.1可以用make查看参数
有错误看日志
cd /usr/local/src
yum install -y unzip #编译nagios需要的包
#这里使用nagios4..x在安装pnp4nagios存在不兼容问题所以建议下载nagios3.x
wget http://nchc.dl.sourceforge.net/project/nagios/nagios-3.x/nagios-3.5.1/nagios-3.5.1.tar.gz
wget http://nchc.dl.sourceforge.net/project/nagios/nagios-4.x/nagios-4.2.1/nagios-4.2.1.tar.gz
wget https://nagios-plugins.org/download/nagios-plugins-2.1.2.tar.gz#_ga=1.74695893.656335937.1476780657
wgethttp://nchc.dl.sourceforge.net/project/nagios/nrpe-2.x/nrpe-2.15/nrpe-2.15.tar.gz
tar -zxvf nagios-3.5.1.tar.gz
cd nagios
./configure --prefix=/usr/local/nagios
make all #编译主程序
make install #对主程序,CGI以及HTML网页进行安装
make install-init #在/etc/rc.d/init.d目录产生nagios启动脚本
make install-commandmode #安装和配置外部命令对nagios主路径操作的权限。(这里所谓的外部命令主要是指apache通过CGI来对nagios的进行的操作,用户通过web以执行CGI程序脚本的方式来对nagios的检测结果进行读取和调用)
make install-config #将会在/usr/local/nagios/etc这个nagios编译安装的主配置路径下安装示例配置模板
cd /usr/local/src
tar -zxvf nagios-plugins-2.1.2.tar.gz
cd nagios-plugins-2.1.2
./configure --prefix=/usr/local/nagios #在/usr/local/nagios生成libexec目录,都是检测脚本
make install
基本安装完成,现在配置apache,让它可以用web界面访问
vim /usr/local/apache2/conf/httpd.conf
#添加一行
Include conf/extra/nagios.conf
#修改主和组
User nagios
Group nagios
然后创建nagios.conf文件
cp/usr/local/src/nagios/sample-config/httpd.conf/usr/local/apache2/conf/extra/nagios.conf
/usr/local/apache2/bin/htpasswd -c/usr/local/nagios/etc/htpasswd.users nagiosadmin #创建一个用户,用于后台访问nagios
/usr/local/apache2/bin/apachectl start
/etc/init.d/nagios start
http://192.168.134.141/nagios/ #通过ip访问nagios,点击Services
状态:
w :Warming 警告
u: Unknown 未知
c: Critical 危险
p: Pending 待定
r: Recovery 状态已回复值OK
yum install -y openssl openssl-devel #./configure需要的包
cd /usr/local/src/
tar -zxvf nrpe-2.15.tar.gz
cd nrpe-2.15
./configure
make all
make install-plugin #安装nrpe插件check-nrpe
要想在被监控的主机安装nrpe,首先要在被监控主机删安装nagios插件
useradd -s /sbin/nologin nagios
cd /usr/local/src
wget https://nagios-plugins.org/download/nagios-plugins-2.1.2.tar.gz#_ga=1.74695893.656335937.1476780657
wget http://nchc.dl.sourceforge.net/project/nagios/nrpe-2.x/nrpe-2.15/nrpe-2.15.tar.gz
tar -zxvf nagios-plugins-2.1.2.tar.gz
cd nagios-plugins-2.1.2
./configure --prefix=/usr/local/nagios--with-nagios-user=nagios --with-nagios-group=nagios #在/usr/local/nagios生成libexec目录,都是检测脚本
make install
ls /usr/local/nagios/ #查看一下,共有三个目录
yum install -y openssl openssl-devel #./configure需要的包
tar -zxvf nrpe-2.15.tar.gz
cd nrpe-2.15
./configure --enable-command-args #如果要给nrpe传递参数,在安装配置加上该参数
make all
make install-plugin #安装nrpe插件check_nrpe
make install-daemon #安装nrpe命令/usr/local/nagios/bin/nrpe
make install-daemon-config #安装nrpe配置文件nrpe.cfg
#跳过 版本为v3.0.1 操作这步makeinstall-config #安装nrpe配置文件nrpe.cfg
允许被别的主机监控,并自制命令
vim /usr/local/nagios/etc/nrpe.cfg
#修改
allowed_hosts=127.0.0.1,192.168.134.132
dont_blame_nrpe=1
command[check_sda1]=/usr/local/nagios/libexec/check_disk-w 20% -c 10% -p /dev/sda1
command[check_sda3]=/usr/local/nagios/libexec/check_disk-w 20% -c 10% -p /dev/sda3
/usr/local/nagios/bin/nrpe -c/usr/local/nagios/etc/nrpe.cfg -d #启动nrpe服务
上面选项的解释
# -c <config_file> = Name of configfile to use
#-d = Run as a standalone daemon
/usr/local/nagios/libexec/check_nrpe -H127.0.0.1 #检查本机check_nrpe和nrpe daemon通信是否正常
停止nrpe服务可以杀死它的pid
ps -aux|grep nrpe #查看pid
#把/usr/local/nagios/include下的文件读入nagios.cfg
vim /usr/local/nagios/etc/nagios.cfg
#添加一行
cfg_dir=/usr/local/nagios/include
#定义check_nrpe
vim/usr/local/nagios/etc/objects/commands.cfg
#添加内容
define command{
command_name check_nrpe
command_line $USER1$/check_nrpe-H $HOSTADDRESS$ -c $ARG1$
}
#监控远程服务
vim/usr/local/nagios/include/192.168.134.141.cfg
#添加内容
define host{
use linux-server
host_name 192.168.134.141
alias 134.141
address 192.168.134.141
}
define service{
use generic-service
host_name 192.168.134.141
service_description check_ping
check_command check_ping!100.0,20%!200.0,50%
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.134.141
service_description check_ssh
check_command check_ssh
max_check_attempts 5 ;当nagios检测到问题时,一共尝试检测5次都有问题才会告警,如果该数值为1,那么检测到问题立即告警
normal_check_interval 1 ;重新检测的时间间隔,单位是分钟,默认是3分钟
notification_interval 60;在服务出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你认为,所有的事件只需要一次通知就够>了,可以把这里的选项设为0。
}
define service{
use generic-service
host_name 192.168.134.141
service_description check_http
check_command check_http
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.134.141
service_description check_load
check_command check_nrpe!check_load
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.134.141
service_description check_disk_sda1
check_command check_nrpe!check_sda1
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.134.141
service_description check_disk_sda3
check_command check_nrpe!check_sda3
max_check_attempts 5
normal_check_interval 1
}
/usr/local/nagios/libexec/check_nrpe -H 192.168.134.132 #检查本机check_nrpe和远程机器的nrpedaemon通信是否正常
/etc/init.d/nagios restart
/etc/init.d/httpd restart
http://192.168.134.132/nagios/ #可以监控远程机器的cpu,磁盘使用
实验在云主机测试成功
利用sendEmail发送邮件配置告警
利用sendEmail登陆一个邮箱,给别的邮箱发邮件,速度快,不延迟
服务端(119.29.186.209)
安装sendEmail
cd /usr/local/src/
wgethttp://caspian.dotconf.net/menu/Software/SendEmail/sendEmail-v1.56.tar.gz
tar -zxvf sendEmail-v1.56.tar.gz
cd sendEmail-v1.56
cp sendEmail /usr/local/bin/
测试发送邮件(成功测试)
sendEmail -t 463245818@qq.com -f14718177839@163.com -s smtp.163.com -u "gaojing" -xu m14718177839@163.com -xp20190214fang -m zhunbe i
选项解释:
-t 表示接收者邮箱
-f 表示发送者邮箱
-s 表示SMTP服务器的域名或者ip
-u 表示邮件的主题
-xu 表示邮箱的用户名
-xp 表示邮箱SMTP验证的密码(这个不是163的登陆密码,而是SMTP服务的密码,也就是客户端授权密码)
-m 表示邮箱的内容
-cc 表示抄送
-bcc 表示暗抄送
vim/usr/local/nagios/etc/objects/commands.cfg
#修改notify-host-by-email和notify-service-by-email
# 'notify-host-by-email' command definition
define command{
command_name notify-host-by-email
command_line /usr/bin/printf"%b" "***** Nagios *****\n\nNotification Type:$NOTIFICATIONTYPE$\nHost: $HOSTNAME$\nState: $HOSTSTATE$\nAddress:$HOSTADDRESS$\nInfo: $HOSTOUTPUT$\n\nDate/Time: $LONGDATETIME$\n" |/usr/local/bin/sendEmail -f 14718177839@163.com -t $CONTACTEMAIL$ -ssmtp.163.com -l /var/log/sendEmail -xu m14718177839 -xp 20190214fang -u"** $NOTIFICATIONTYPE$ Host Alert: $HOSTNAME$ is $HOSTSTATE$ **" -m"`/usr/bin/printf "%b" "\n***** Nagios*****\n\nNotification Type: $NOTIFICATIONTYPE$ \nHost: $HOSTNAME$\nState:$HOSTSTATE$\nAddress: $HOSTADDRESS$\nInfo: $HOSTOUTPUT$\nDate/Time:$LONGDATETIME$\n"`"
}
# 'notify-service-by-email' commanddefinition
define command{
command_name notify-service-by-email
command_line /usr/bin/printf"%b" "***** Nagios *****\n\nNotification Type:$NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress:$HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditionalInfo:\n\n$SERVICEOUTPUT$\n" | /usr/local/bin/sendEmail -f14718177839@163.com -t $CONTACTEMAIL$ -s smtp.163.com -l /var/log/sendEmail -xum14718177839 -xp 20190214fang -u "** $NOTIFICATIONTYPE$ Service Alert:$SERVICEDESC$ is $SERVICESTATE$ **" -m "`/usr/bin/printf"%b" "\n***** Nagios *****\n\nNotification Type:$NOTIFICATIONTYPE$ \nService: $SERVICEDESC$\nHost: $HOSTNAME$\nState:$SERVICESTATE$\nAddress:$HOSTADDRESS$\nInfo:$SERVICEOUTPUT$\nDate/Time:$LONGDATETIME$\n"`"
}
vim/usr/local/nagios/etc/objects/contacts.cfg
define contact{
contact_name da
use generic-contact
alias da
# service_notification_period 24x7
# host_notification_period 24x7
# service_notification_options w,u,c
# host_notification_options d,u
# service_notification_commands notify-service-by-email
# host_notification_commands notify-host-by-email
email 463245818@qq.com
}
define contact{
contact_name fang
use generic-contact
alias fang
email 237600604@qq.com
}
define contactgroup{
contactgroup_name ops
alias ops
members da,fang
}
vim /usr/local/nagios/include/xiaojun.cfg
define service{
use generic-service
host_name 115.28.76.154
service_description check_ssh
check_command check_ssh
max_check_attempts 5 ;当nagios检测到问题时,一共尝试检测5次都有问题才会告警,如果该数值为1,那么检测到问题立即告警
normal_check_interval 1 ;重新检测的时间间隔,单位是分钟,默认是3分钟
notification_interval 60;在服务出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你认为,所有的事件只需要一次通知就够>了,可以把这里的选项设为0。
}
define service{
use generic-service
host_name 115.28.76.154
service_description check_http
check_command check_http
max_check_attempts 1
normal_check_interval 1
notification_interval 1
contact_groups ops
notifications_enabled 1
notification_period 24x7
notification_options w,u,c,r
}
#其中
notifications_enabled 1 ;是否开启提醒功能。1为开启,0为禁用。一般,这个选项会在主配置文件(nagios.cfg)中定义,效果相同。
notification_period 24x7 ;发送提醒的时间段。非常重要的主机(服务)我定义为7×24,一般的主机(服务)就定义为上班时间。如果不在定义的时间段内,无论什么问题发生,都不>会发送提醒。
notification_options:w,u,c,r ;这个是service的状态。w为waning, u为unknown, c为critical, r为recover(恢复了),类似的还有一个 host对应的状态:d,u,r d = 状态为DOWN, u = 状态为UNREACHABLE, r = 状态恢复为OK,需要加入到host的定义配置里。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



