之前有不少同学看过我的个人博客(http://python-online.cn),也根据我写的教程完成了自己个人站点的搭建。
点此:使用 Python 30分钟 教你快速搭建一个博客
为防有的同学不清楚 Sphinx ,这里还是做下简单的介绍。
它是一个能够把一组 reStructuredText 或者 Markdown 格式的文件转换成各种输出格式,而且自动地生成交叉引用,生成目录等的一个文档编排工具。
不得不说,它的排版功能强大、非常清晰,顔值非常高。
但是使用这个方法搭建的博客,一直有一个痛点,就是无法自定义页面,自由度非常的低(和 WordPress 真的没法比)。
这就导致我一直不知道到底有没有人访问我的网站?
他们都是从哪来访问的,Google 还是 百度?
每篇文章都有多少人访问,哪篇文章最受欢迎?
我一直在我的博客上×××底因×××少呢?
因此我一直希望能找到一个能够收集网站访问数据、并且能将博客上的访×××
终于在昨天,我找到了,并花了两天的时间成功上线。
方法就是引入两个 JavaSript 插件实现(这个在早期的 Sphinx 版本中是不支持的)。
第一个插件:导流工具
作用:这个主要用来将自己博客上流量引×××是思路是:
游客无法阅读博客的全部内容,因为会有一半的内容会被隐藏。就像这样。

如想要阅读全文,可以点击全文进行解锁:用微信扫描二维×××ore` ,将获取到的验证码填入如下文本框提交即可永久解锁本博客的所有干货文章。
思路有了,那么如何实现呢?
以上功能其实已经有人已经做出来并可以提供免费使用。
你可以在 https://openwrite.cn/ 注册一个帐号,然后在里面你可以看到一个导流工具,×××信息后,就初始化成功,获得一串js代码。
接下来,你要做的就是将这串js接入你的博客页面中。
由于我去年搭建这个博客时使用的 Sphinx 的版本是 1.7 ,这个版本是不支持自定义css/js 文件的。
因此,你要使用引入这段js代码,需要将你的 Sphinx 升级到 1.8+,我使用的是最新版本的 2.1 ,这个版本只支持 Python 3.5+。
因此在使用之前,我得先将环境的切换至 Python 3.5+。
virtualenv -p /usr/bin/python3.6 myblog然后安装 Sphinx 及相关包
pip install Sphinx sphinx-rtd-theme -i https://pypi.douban.com/simple问题一
虽然现在我们的 Sphinx 已经支持自定义js了(方法是将一个js文件以引用的方式放在 header 标签里)
但是 OpenWrite 要实现 阅读全文 的效果,这个readmore.js必须放在 HTML 的尾部,意思是要等页面加载完成后才能起作用。
这下就尴尬了。Sphinx 会将 readmore.js 放在 HTML 顶部,而要实现 阅读全文 的效果,readmore.js 需要放在底部。由于框架是固定的,我们无法对其进行定制修改。那还有什么方法可以补救呢?
我的方案是:在 readmore.js 中加入逻辑,当页面加载完成后再运行。
问题二
若想 readmore.js 起作用,前提是你的文章的正文div中需要有一个id=‘container’属性, 而这个 Sphinx 是不会生成的。
这样的话,这个动态添加 id 属性的工作也只能交由 readmore.js 来做了。
问题三
由 Sphinx 生成的的所有页面都会加引入这个 readmore.js 插件,这就导致所有的页面(包括首页,索引页)都会有 阅读全文 的限制。这明显是不合理的。
为了解决这个问题,我想的是在 readmore.js 中,根据 url 进行判断,只有文章页面才有限制,而其他的页面则不受限制。
总结一下,这个 readmore.js 会做三件事:
如果你不想自己写,可×××流”,直接用我写好的js文件。
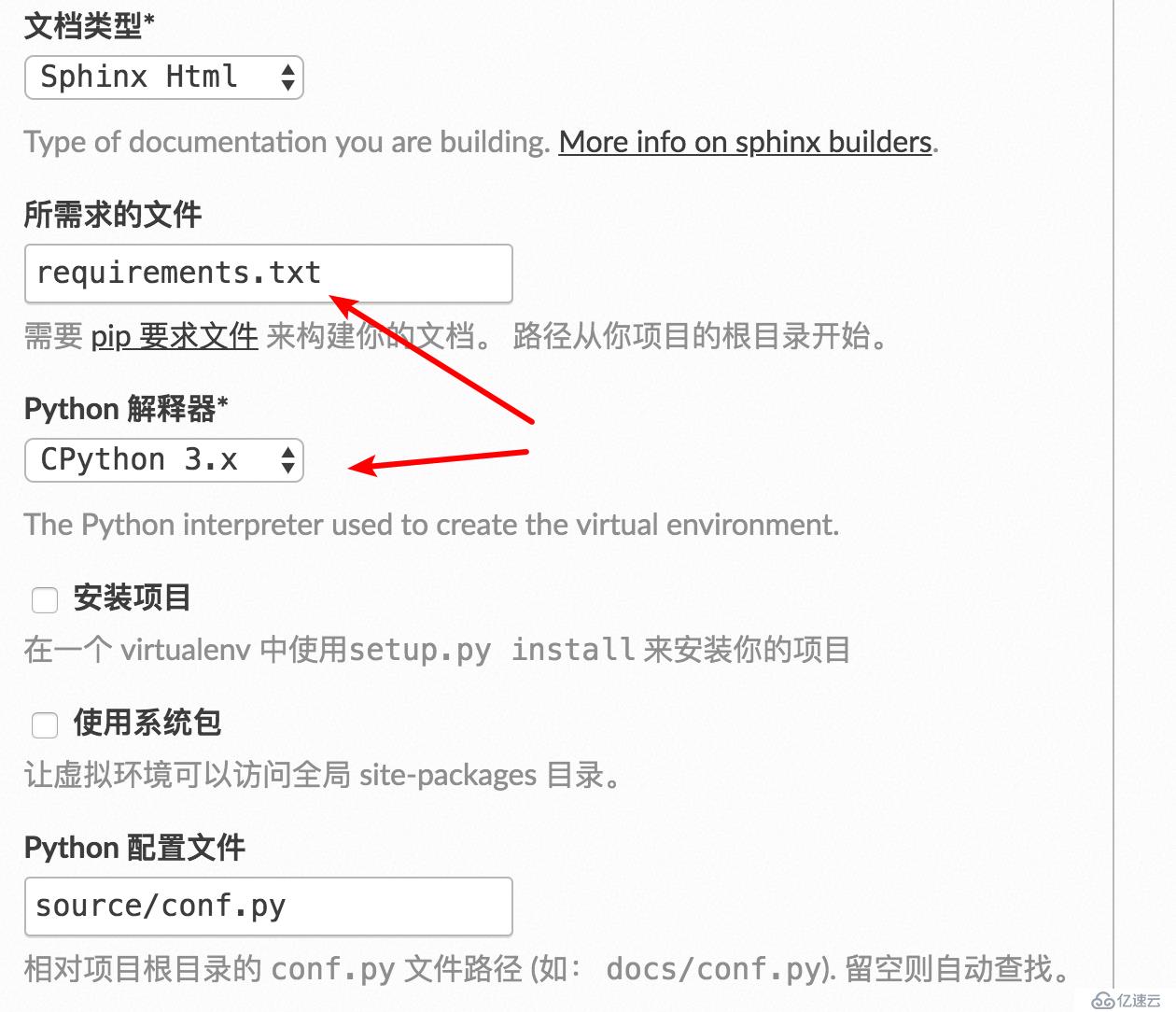
获取到的js文件需要放在固定的路径下: source/_static/js/ (如果没有此路径就手动创建),然后修改 conf.py
html_static_path = ['_static']
html_js_files = [
'js/readmore.js',
]按理说,这样就已经大功告成了。
但是别忘了,我们是用 readthedocs 生成我们的博客页面的。
为此,我们同样也要在 readthedocs 进行相关的配置。
(注:使用 pip freeze >requirements.txt 生成)
同时你如果之前是看过我写的教程,使用过我的中文检索插件,那你要注意了。
此前这个插件是基于 Python 2.x 写的,现在我们切换成 Sphinx 项目切换成 Python 3.x ,所以这里的代码也要对应修改。
改动也不大,只要把 exts/smallseg.py 这个文件里的 decode 相关的代码全部去掉即可。
一切按照上面的步骤全部设置完成后,提交Github后,再次从 readthedocs 构建就可以看到效果了。
对于这个功能,我几点要说明:
第二个插件:百度统计
作用:用于收集个人网站的访问数据。
有了上面的经验,现在我们知道如何在页面中插件自定义 js 代码。
那我就想有没有那种可以通过引入 js 插件来收集网站的访问数据呢?
这种工具应该不少,而我使用的是百度家的产品 - 百度统计 。
它可以帮我们收集网站访问数据,提供流量趋势、来源分析、转化跟踪、页面热力图、访问流等多种统计分析服务。
那怎么使用呢?
首先使用你的百度帐号登陆 百度统计。
然后在网站列表新增一个你的网站,我的信息如下:
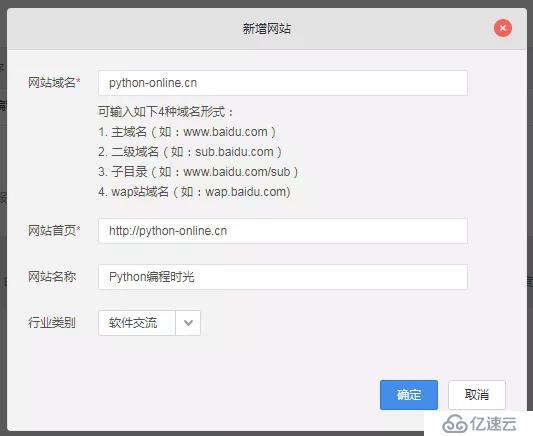
填写完成,就可以获取一段属于你的网站的专属 js 代码(下面第一步)。
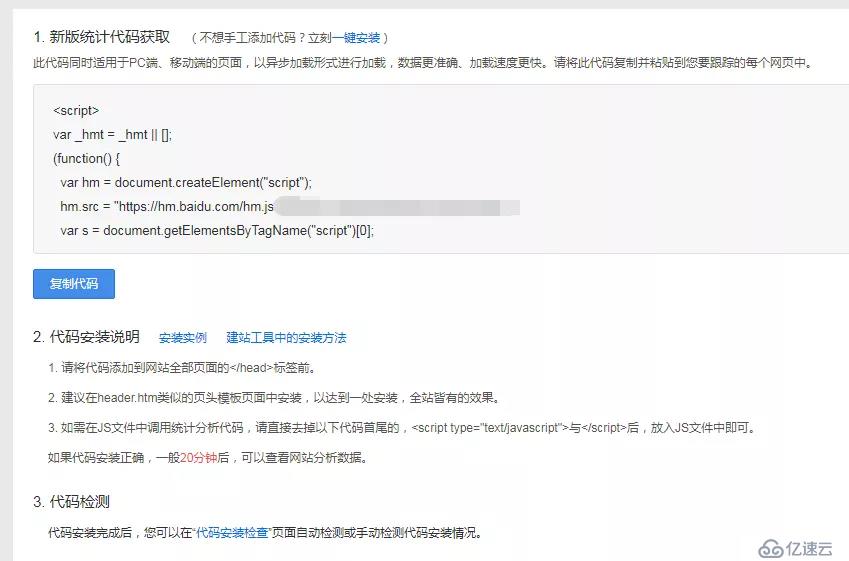
第二步内容,是教你如何安装这段 js 代码。
将这段代码内容写入一个单独的 js 文件:baidutongji.js
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?xxxxxxxx";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();并修改 conf.py 后,提交至你的 Github。
html_js_files = [
'js/readmore.js',
'js/baidutongji.js'
]一切完成后,就可以去 readthedocs 重建构建。
构建完成后,去执行第三步,代码安装检查。像我下面这样,就是安装完成了。
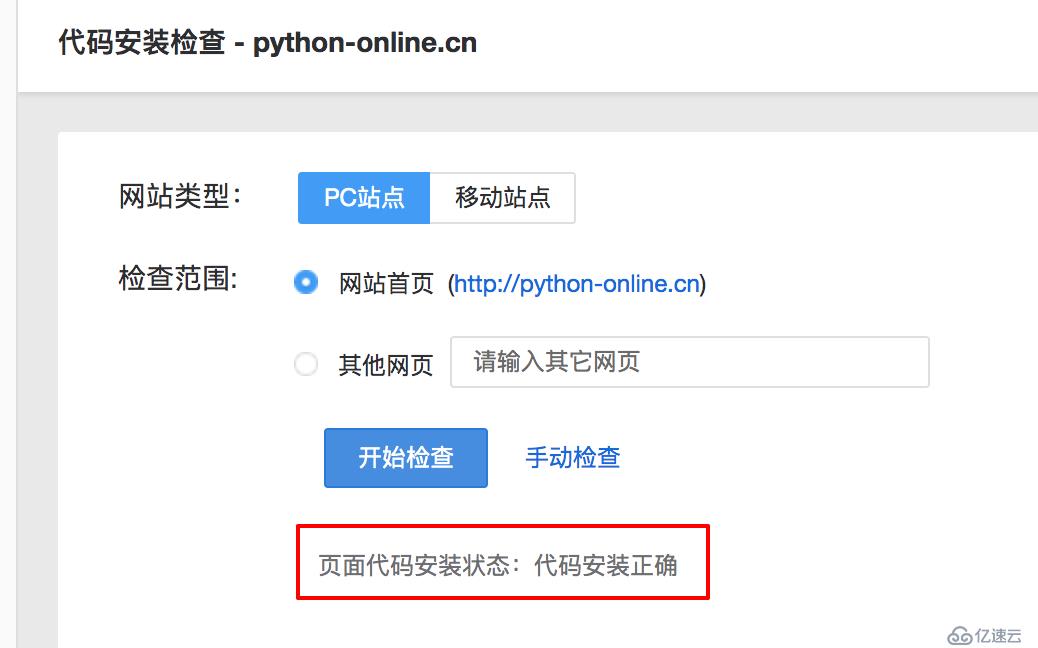
这个插件安装完成后,如果你的网站有流量,可以过个一个小时,点击一下查看报告查看你网站的详细访问数据。
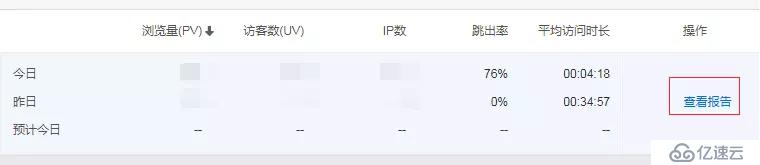
数据真的非常全面,你可以知道,访客都是从哪里访问(直接访问,Google等),每篇文章的点击量(你就知道哪篇是爆款?),每天有多少老访问客,多少新访客等等,更多维度的数据你可以自己去体验一下。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





