这篇文章主要讲解了“mysql的join查询和多次查询方法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“mysql的join查询和多次查询方法是什么”吧!
MySQL多表关联查询效率高点还是多次单表查询效率高?
在数据量不够大的时候,用join没有问题,但是一般都会拉到service层上去做
第一:单机数据库计算资源很贵,数据库同时要服务写和读,都需要消耗CPU,为了能让数据库的吞吐变得更高,而业务又不在乎那几百微妙到毫秒级的延时差距,业务会把更多计算放到service层做,毕竟计算资源很好水平扩展,数据库很难啊,所以大多数业务会把纯计算操作放到service层做,而将数据库当成一种带事务能力的kv系统来使用,这是一种重业务,轻DB的架构思路
第二:很多复杂的业务可能会由于发展的历史原因,一般不会只用一种数据库,一般会在多个数据库上加一层中间件,多个数据库之间就没办法join了,自然业务会抽象出一个service层,降低对数据库的耦合。
第三:对于一些大型公司由于数据规模庞大,不得不对数据库进行分库分表,对于分库分表的应用,使用join也受到了很多限制,除非业务能够很好的根据sharding key明确要join的两个表在同一个物理库中。而中间件一般对跨库join都支持不好。
举一个很常见的业务例子,在分库分表中,要同步更新两个表,这两个表位于不同的物理库中,为了保证数据一致性,一种做法是通过分布式事务中间件将两个更新操作放到一个事务中,但这样的操作一般要加全局锁,性能很捉急,而有些业务能够容忍短暂的数据不一致,怎么做?让它们分别更新呗,但是会存在数据写失败的问题,那就起个定时任务,扫描下A表有没有失败的行,然后看看B表是不是也没写成功,然后对这两条关联记录做订正,这个时候同样没法用join去实现,只能将数据拉到service层应用自己来合并了。。。
事实上,用分解关联查询的方式重构查询具有如下优势:
让缓存的效率更高。
许多应用程序可以方便地缓存单表查询对应的结果对象。另外对于MySQL的查询缓存来说,如果关联中的某个表发生了变化,那么就无法使用查询缓存了,而拆分后,如果某个表很少改变,那么基于该表的查询就可以重复利用查询缓存结果了。
将查询分解后,执行单个查询可以减少锁的竞争。
在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
查询本身效率也可能会有所提升
可以减少冗余记录的查询。
更进一步,这样做相当于在应用中实现了哈希关联,而不是使用MySQL的嵌套环关联,某些场景哈希关联的效率更高很多。
MySQL 的执行顺序
1)from子句组装来自不同数据源的数据;
2)使用on进行join连接的数据筛选
3)where子句基于指定的条件对记录行进行筛选;
4)group by子句将数据划分为多个分组;
5)cube, rollup
6)使用聚集函数进行计算;
7)使用having子句筛选分组;
8)计算所有的表达式;
9)计算select的字段;
10)使用distinct 进行数据去重
11)使用order by对结果集进行排序。
12)选择TOPN的数据
如果是采用的 关联 from tableA, tableB ,这2个表会先组织进行笛卡尔积,然后在进行下面的 where、group by 等操作。
如果使用left join, inner join 或者 outer full join的时候,使用on 进行条件筛选后,在进行join。
看下面的2个sql 和结果。2者的区别仅仅是在on后面的一个语句在on和where位置的不同。 由此可以看出是先通过on 进行条件筛选,然后在join,最后在进行where条件筛选。
假如:是先进行join,在进行on的话,会产生一个笛卡尔积,然后在筛选。这样的left join 和 直连接 没有任何的区别。 所以肯定是先on 条件筛选后,在进行join。
假如:是在进行where 后,在on,在进行join, 下面2个sql的返回结果应该是一样的。由此可以见,where是针对 join 后的集合进行的筛选。
综上: 先 执行on 条件筛选, 在进行join, 最后进行where 筛选
SELECT DISTINCT a.domain , b.domain
FROM mal_nxdomains_raw a
LEFT JOIN mal_nxdomains_detail b ON a.domain = b.domain AND b.date = ‘20160403'
WHERE a.date = ‘20160403'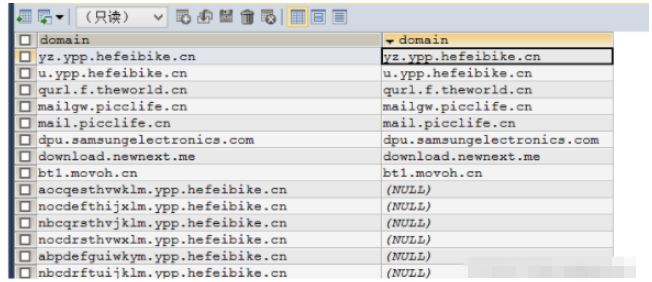
SELECT DISTINCT a.domain , b.domain
FROM mal_nxdomains_raw a
LEFT JOIN mal_nxdomains_detail b ON a.domain = b.domain #and b.date = ‘20160403'
WHERE a.date = ‘20160403'
AND b.date = ‘20160403'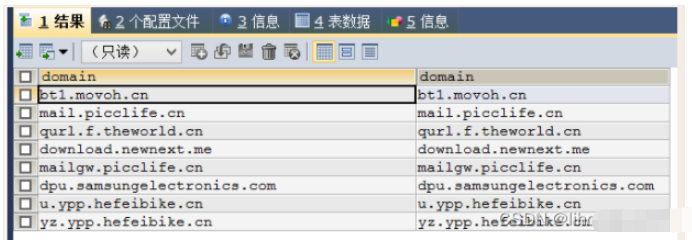
1、使用位置
on 条件位置在join后面
where 条件在join 与on完成的后面
2、使用对象
on 的使用对象是被关联表
where的使用对象可以是主表,也可以是关联表
3、选择与使用
主表条件筛选:只能在where后面使用。
被关联表,如果是想缩小join范围,可以放置到on后面。如果是关联后再查询,可以放置到where 后面。
如果left join 中,where条件有对被关联表的 关联字段的 非空查询,与使用inner join的效果后,在进行where 筛选的效果是一样的。不能起到left join的作用。
tableA join tableB, 从A表中拿出一条数据,到B表中进行扫描匹配。所以A的行数决定查询次数,B表的行数决定扫描范围。例如A表100条,B表200表,需要100次从A表中取出一条数据到B表中进行200次的比对。
相对来说从A表取数据消耗的资源比较多。所以尽量tableA选择比较小的表。同时缩小B表的查询范围。
但是实际应用中,因为二者返回的数据结果不同,使用的索引也不同,导致条件放置在on 和 where 效率是不一定谁更好。要根据需求来确定。
感谢各位的阅读,以上就是“mysql的join查询和多次查询方法是什么”的内容了,经过本文的学习后,相信大家对mysql的join查询和多次查询方法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://blog.csdn.net/loliDapao/article/details/122454560



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



