这篇文章主要讲解了“Mysql中on,in,as,where的区别是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Mysql中on,in,as,where的区别是什么”吧!
答:Where查询条件,on内外连接时候用,as作为别名,in查询某值是否在某条件里
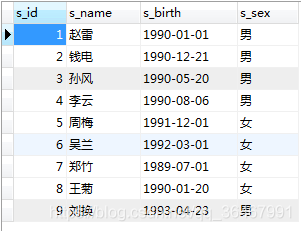
创建2个表:student,score
student:
score:

where
SELECT * FROM student WHERE s_sex='男'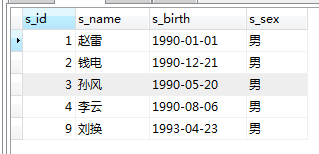
例如:on
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id;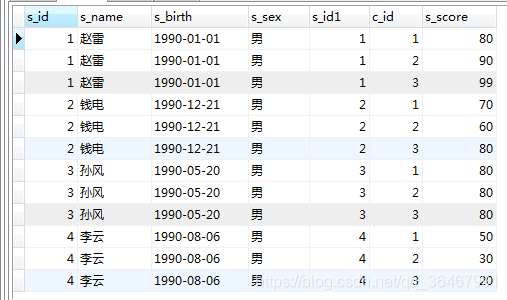
on和where组合:
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id WHERE s_name='赵雷'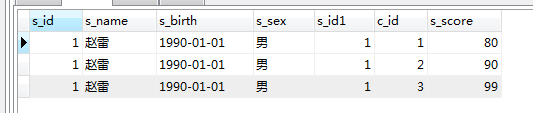
例如:in
SELECT * FROM score WHERE s_id in (SELECT s_id FROM student WHERE s_name='赵雷') 
as
select * from score as a LEFT JOIN student as b on a.s_id=b.s_id where s_name='赵雷'
on后面的条件只能对left join右边的表进行筛选,左表匹配不到右表数据会在原右表位置处显示null,left join左边的表数据不受约束,将on后的条件加到where后会对所有数据进行筛选。
with <name> as()mysql内可以使用with as生成临时表,<name>为临时表的名字,使用如下:
with arc as(
select id,arc.title,update_time,is_top,cId,pid,name_id from article arc where is_del = 0
)
select * from arcwith...as的作用范围只有一次sql执行的时间,执行过后就不再存在,根据例子我们本要处理article表,但表里的数据并非都是我们需要的,所系先筛选建立了一个临时表arc,我们会对arc进行操作。
如果只是上述例子的简单操作是没必要使用with...as的,但是当我们需要将article表与其他表进行联查甚至嵌套时,会出现要多次进行is_del = 0的判断,最终出来的sql语句可能个十分复杂,并且极易出错,但使用arc就不需要在对数据进行重复筛选了。
with...as里的sql可以更复杂些,比如article表里有name_id,但更多时候我们希望使用name,我们可以预先在with...as内查找好,再使用临时表去做其他操作。
这算是个比较经典的一个问题了,我初学,只会一种解题方法,但会尽力讲的简单通俗点。
示例:
select * from (
select cId,title,content(
select count(*)+1 from arc a1 where (a1.cId = a2.cId) and a1.updateTime > a2.updateTime
)updateTimeSort from arc a2
) a3
where updateTimeSort <= 3 order by cId,updateTime desc示例中cId是类别id,updateTime 是更新时间,解决问题是选取arc内每个类别最晚更新的的三条数据,就像新闻的首页需要为每个分类选出最新的三条新闻,按照数据库里的数据我们可以使用排序 order by cId,updateTime desc 对数据按类别和更新时间进行排序,但去取每个类别的特定几条数据,现有数据库是做不到的,因此我们可以添加一个临时字段。
updateTimeSort 它表示的是每个类别中每个子项在这个类别中的排序,在当前问题中这个临时字段应该是和字段 updateTime 相关的,根据更新时间为类别中的每个子项排出顺序。
如示例代码,我们能找到a1和a2这两个表,他们都是arc表的别称,通过子查询的形式结合在一起,以a2为主,去a1表内查找类别和a2当前数据相同的,并且更新时间晚于a2当前数据的数据数量,能看到 count(*)+1 也就是数量加一了,不加一也可以,只是当一条数据在它所处类别更新时间最晚时count(*) 的值是0,若果使用count(*)+1 我们就可以将数据从1开始排序。
最终我们只要选取 updateTimeSort <= 3 的数据即可,如果想要筛选最早发布的新闻也只需要将updateTimeSort 的筛选逻辑变更一下即可,在示例代码中即将
a1.updateTime > a2.updateTime 更改为 a1.updateTime < a2.updateTime
可以看到示例代码中还有一个表a3,它其实时一个临时表,前面我们了解了with..as可以生成临时表,也重这次代码中可以看出,临时表也可以以另一种形式存在,with...as我们只有当sql复杂时才会使用,一般来说现在这种方式能帮我们解决不少问题了,各有优劣,看情况使用。
接触sql多了会发现,sql其实能帮我们解决一定的业务问题,明显的有sql的存储过程和方法,对sql语句的批量处理其实在一定程度上帮我们解决一定的业务问题,但缺点也很明显,当新手接触这个项目时他很难搞清楚某个功能到底是如何实现的,不利于维护。
一般来说我们解决业务是在server层,有时会使用sql解决一些问题,但很少,在sever处理受制于计算机硬件,在数据库处理受制于数据库性能,相比之下,计算机硬件更易于扩展,因此还是不推荐大量使用sql解决问题的。
例如上个问题:根据某个字段排序取每个类别最后三条数据或前三条数据问题,虽然问题基本解决但让存在一些 ‘bug’,例如排序时会产生1、2、3、3、4这种排序,这是因为同个类别内有两条数据更新时间重复了,那我们直观想法(还是要看个人经验值)应该是,既然问题出在数据库,那应该在数据库查询的时候就解决这个问题,但事实上,让数据库去解决并不好解决,数据库的强项在于各种搜索算法,不在于逻辑处理,因此我们就要转移到server层处理,会有不少人陷于这个坑,花费大量时间去找办法让数据库去处理这类问题,但其实就算数据库处理得了,它也不一定有server层处理的效率高,当然如果是为了学习更多东西,这些时间也是值得花的,但是这种解题思路还是要改变下的。将1、2、3、3、4问题交给server处理也就是利用java等高级语言处理这种问题,相信熟用这些语言的开发者解决这些问题都是小case了。
先复习下知识:用过count函数的人都清楚一旦使用count这类聚合函数,不做其他处理数据就会归为一行数据,但很多时候我们并不期望这样的结果,以此就要想些办法能用聚合函数,也能获取很多数据,我常用的是利用group by分组。
回归问题,现有(现不讨论表是否合理)文章表(id,title,content)有文章id,标题,文章内容三个字段,点赞收藏表(id,arc_id,fav,like)有表id,文章id,收藏字段(0未收藏,1收藏),点赞字段(0未点赞,1点赞),现要查询文章表内每篇文章的点赞收藏数,sql语句:
select art.title,art.content,
count(case afl.fav when 1 then 1 end) as collectNum,
count(case afl.like when 1 then 1 end) as likeNum
from article art
left join article_favor_like afl on afl.arc_id = art.id
group by afl.arc_id //这是关键如果没有group by afl.arc_id 后果就是,查出来一行数据,数据还牛头不对马嘴,但通过对文章收藏表中的文章id进行分组就可以针对每个文章id查询数据,这样left join时右表就有每个文章id对相应的收藏数与点赞数,而不是表内所有点赞数和收藏数,最终数据也是我们所需的。
例子:
select id,title,content,1 isArc from arc
union
select id,name,content,0 isArc from news使用union进行的是上下整合
被联合的数据列数要求一致
列数相同,数据类型不同会自动进行数据类型转换
联合后的列的名字由联合中第一次出现的列名为依据,即使后续被联合数据有自己的列名也不会使用,在例子中最终列名为:id,title,content,name等列名不会使用,因此使用union一般配合别名使用统一结果。
有时候会区分数据是哪个表的,可以通过附加额外的字段来区别,就像例子中的isArc字段,news表中的isArc可以不写,原因也就是第4条,最终列名由第一次出现的列名决定,后续数据列名有没有都可以。
limit一般用于分页,功能是获取指定区间内的数据,因此我们也可以用它来减少数据库的查询,例子:
select * from arc where id = 12 limit 1数据库查询由索引还好,没有索引是要遍历数据库的,有些数据经由条件筛选在逻辑上应该是唯一的,使用limit 1可以使数据库查询到该数据时不再搜索,减少数据库搜索次数,但这种方法仅是一种技巧,想大幅度优化sql还要另想办法。
//标题是唯一索引,'新标题'存在则更新操作不执行
update ignore arc set title = '新标题'
//标题是唯一索引,'标题1号'存在则插入操作不执行
insert ignore into arc values(null,'标题1号','文章内容')有这种需求,数据存在时不执行任何操作,不存在则更新或插入,一个办法是使用ingore,它会忽略数据库报错,而数据库执行原子操作时报错是会回滚的,因此只要我们给数据加上主键或唯一索引,当被更新字段或插入字段与原有数据冲突时会报错,但因为ingore会忽视这种报错,后端也就不会报错,sql也未执行,达到了目的,有人会对报错敏感,其实也没什么,报错也是在检查数据是发现不合理之处给的一个提醒或警告,对数据库无害的。
区别于上面那个需求,这个是当插入的数据存在时更新数据,不再是不做任何操作,例子:
//本例子中title不是唯一索引,id是主键
insert into arc values(1,'标题1号','文章内容')
on duplicate key update title='标题1号'
//若要更新多个字段使用','隔开,例:title='标题1号',content='文章内容'在例子中,当id为1的数据存在时,更新标题和内容,不存在则插入,如果执行更新操作,未设置新值的字段保持原来的值。
还有一个REPLACE INTO也可以达到这种效果,区别在于,REPLACE INTO更新时是先删除后插入会破坏原有索引,id为3的数据更新时会删除插入id为4的数据,未更新新值的字段设置为默认值或null。
无论是两个中的哪种方式判断数据是否存在的依据都是主键和唯一索引。
感谢各位的阅读,以上就是“Mysql中on,in,as,where的区别是什么”的内容了,经过本文的学习后,相信大家对Mysql中on,in,as,where的区别是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://blog.csdn.net/qq_36467991/article/details/91168953



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



