本篇内容介绍了“Numpy布尔索引如何实现”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
布尔数据:只有两种值,即真(True)或假(False),如果我们将某些变量说明为布尔型,那么这些变量即为布尔变量只能存储布尔值(True,False)
定义大数据2003班‘学生’及‘考试成绩’,并且打印其结果
import numpy as np names = np.array(['Bob','lilin','jonse','Andy']) score = np.array([['65','85','95'],['66','76','86'],['97','87','77'],['91','81','71']]) print(names,'\n',score)
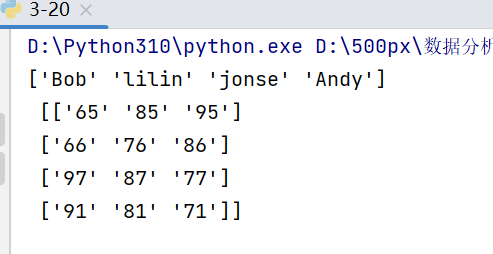
每个人名和其数组之间是相互对应关系,我们通过学生名称来索引学生成绩
names = np.array(['Bob','lilin','jonse','Andy']) score = np.array([['65','85','95'],['66','76','86'],['97','87','77'],['91','81','71']]) lilin_score = score[names == 'lilin'] print(lilin_score)
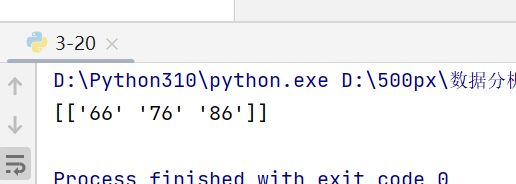
注意,此做法隐藏着一个前提:定义的布尔值数组的长度必须和 数组轴索引长度(行数)一致,否则报错
例如:大数据3班 KungFu_Dragon 同学没有成绩,也就是说,大数据3班有6个人,只有5个人有成绩,成员和成绩之间不匹配。
names = np.array(['Bob','lilin','jonse','Andy','KungFu_Dragon']) score = np.array([['65','85','95'],['66','76','86'],['97','87','77'],['91','81','71']]) lilin_score = score[names == 'KungFu_Dragon'] print(lilin_score)
IndexError: boolean index did not match indexed array along dimension 0; dimension is 4 but corresponding boolean dimension is 5
除去上述操作之外,我们还可以通过布尔索引 和 切片 或 整数值 的 序列混合使用 和 匹配
布尔索引和切片操作混合使用
Andy_scores = score[names == 'Andy'] Andy_score = score[names == 'Andy',1:3]
布尔索引和整数序列操作混合使用
Andy_scores = score[names == 'Andy'] Andy_score = score[names == 'Andy',2]
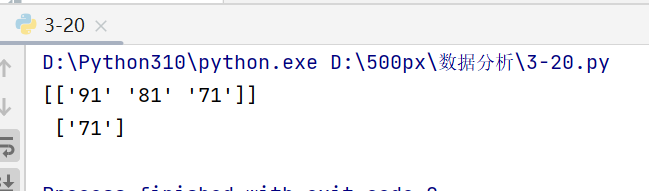
我之前已经提到过,在Python基础中索引和切片的关系,
通过元素数量来看:索引:取一个值,切片:可以取多个值
元素类型而言:索引获得的是字符串,切片获得的是列表,有的时候索引和切片获得都是同一个元素,但是他们的数据类型是不同的。
与基本的数学比较类似,数组中也有类似的比较操作,但是在的比较操作中,会产生True 和 False 的布尔值
下面我对两个数组之间进行了比较
import numpy as np
arr = np.random.randn(4,3)
arr2 = np.random.rand(4,3)
print(arr)
print('----------------')
print(arr2)
arr == arr2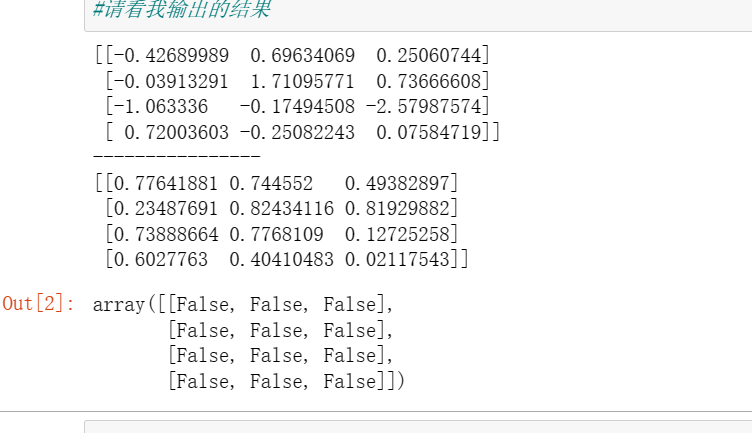
说简单了,其实就是每一个对应位置的元素之间进行比较 如果相同给出 True 如果不同,给出False
例如: arr 数组中 “-0.42689989”的下标为(0,0)arr2数组中“0.77641881”的下标为(0,0),我认为它们之间,会通过这样一个比较方法,arr 和arr2 都是二维数组,而且它们数组长度都是一致的,但是他们不是这样进行比较的,arr 第一个元素和 arr2 第一个元素进行比较,arr2第二个元素,和 arr2 第二个元素比较。它的比较方式是,假如 arr数组中第一个元素为 2,如果要将 arr 和 arr2 进行比较,它会在arr2中寻找一个元素值为2 的数字,如果存在给出Ture 否则为False
在numpy中我们来看看一下他们是什么数据类型 ,通过type(变量名)来查看数据类型

由此可见,在numpy中,切片和 整数序列索引的数据类型是一致的,都是多维数组(ndarray)
在上述的基础上,我们还可以在条件表达式前使用 ‘~’,做取反操作,比如:
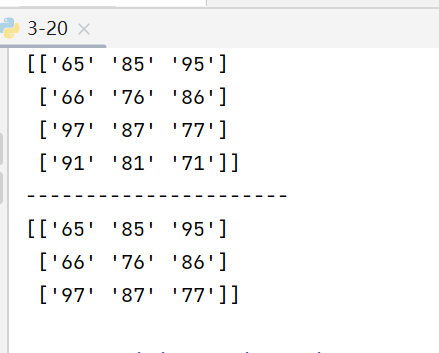
我通过python打印了除去 大数据3班学生,‘Andy’以外的所有成员成绩。
除去给了上述取反操作 “~”外还有一种 方法,‘’!=‘’
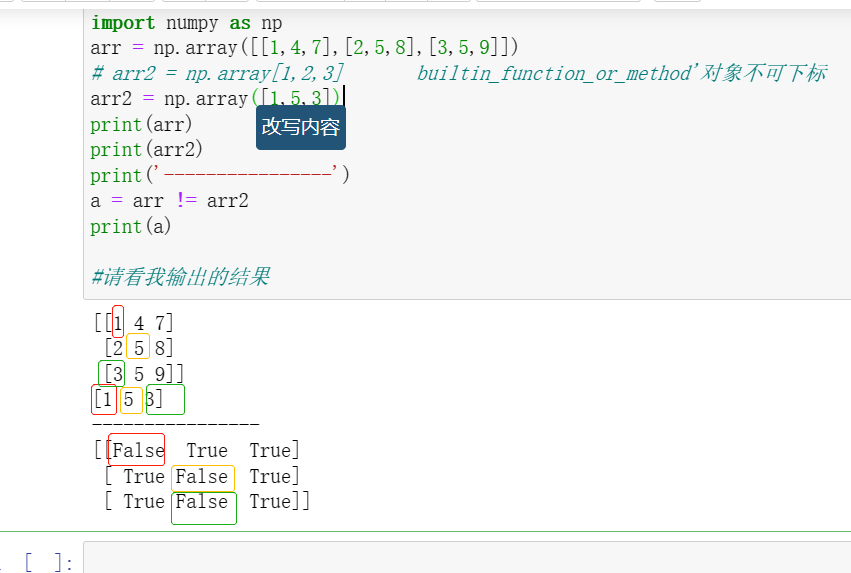
arr = np.array([[1,4,7],[2,5,8],[3,5,9]])
# arr2 = np.array[1,2,3] builtin_function_or_method'对象不可下标
arr2 = np.array([1,5,3])
print(arr)
print(arr2)
print('----------------')
a = arr != arr2
print(a)我疑惑的是为什么他们给出了布尔值请仔细观察我用相同颜色框起来的值。
本来相同应该是 Ture ,不同应该用 False ,但因我用了取反操作,所以相同的成为了False 不同的用了ture。
“Numpy布尔索引如何实现”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





