这篇文章主要讲解了“如何用scrapy框架爬取豆瓣读书Top250的书类信息”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何用scrapy框架爬取豆瓣读书Top250的书类信息”吧!
安装方法:Windows:在终端输入命令:pip install scrapy;mac:在终端输入命令:pip3 install scrapy,按下enter键,再输入cd Python,就能跳转到Python文件夹。接着输入cd Pythoncode,就能跳转到Python文件夹里的Pythoncode子文件夹。最后输入一行能帮我们创建Scrapy项目的命令:scrapy startproject douban,douban就是Scrapy项目的名字。按下enter键,一个Scrapy项目就创建成功了。
爬取豆瓣读书Top250的书名,出版信息和评分
目标url为:https://book.douban.com/top250?start=0
整个scrapy项目的结构,如下图
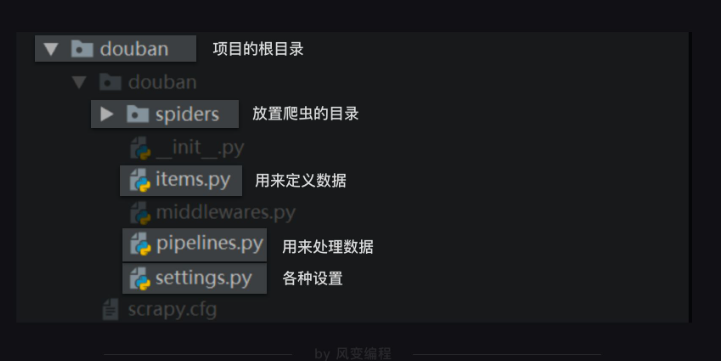
spiders是放置爬虫的目录。我们在spiders这个文件夹里创建爬虫文件,我们把这个文件命名为top250,大部分代码都需要在这个top250.py文件里编写。在top250.py文件里导入我们需要的模块:import scrapy , bs4
导入scrapy是我们要用创建类的方式写这个爬虫,我们所创建的类将直接继承scrapy中的scrapy.Spider类。这样,有许多好用属性和方法,就能够直接使用。
class DoubanSpider(scrapy.Spider): #定义一个爬虫类DoubanSpider,DoubanSpider类继承自scrapy.Spider类。
name = 'douban' #定义爬虫的名字,这个名字是爬虫的唯一标识。
allowed_domains = ['book.douban.com']#定义允许爬虫爬取的网址域名(不需要加https://)。如果网址的域名不在这个列表里,就会被过滤掉。allowed_domains就限制了,我们这种关联爬取的URL,一定在book.douban.com这个域名之下,不会跳转到某个奇怪的广告页面。
start_urls = ['https://book.douban.com/top250?start=0']#定义起始网址,就是爬虫从哪个网址开始抓取
def parse(self, response):#parse是Scrapy里默认处理response的一个方法,中文是解析。
print(response.text)
#这里我们并不需要写类似requests.get()的语句,scrapy框架会为我们代劳做这件事,写好你的请求,接下来你就可以直接写对响应如何做处理每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。定义这个类的py文件,正是items.py。
如果要爬取豆瓣读书的书名、出版信息和评分,示例:
import scrapy
#导入scrapy
class DoubanItem(scrapy.Item):
#定义一个类DoubanItem,它继承自scrapy.Item
title = scrapy.Field()
#定义书名的数据属性
publish = scrapy.Field()
#定义出版信息的数据属性
score = scrapy.Field()
#定义评分的数据属性scrapy.Field()这行代码实现的是,让数据能以类似字典的形式记录,它输出的结果非常像字典,但它却并不是dict,它的数据类型是我们定义的DoubanItem,属于自定义的Python字典.我们利用类似上述代码的样式,去重新写top250.py
import scrapy
import bs4
from ..items import DoubanItem
# 需要引用DoubanItem,它在items里面。因为是items在top250.py的上一级目录,所以要用..items,这是一个固定用法。
class DoubanSpider(scrapy.Spider):
#定义一个爬虫类DoubanSpider。
name = 'douban'
#定义爬虫的名字为douban。
allowed_domains = ['book.douban.com']
#定义爬虫爬取网址的域名。
start_urls = []
#定义起始网址。
for x in range(3):
url = 'https://book.douban.com/top250?start=' + str(x * 25)
start_urls.append(url)
#把豆瓣Top250图书的前3页网址添加进start_urls。
def parse(self, response):
#parse是默认处理response的方法。
bs = bs4.BeautifulSoup(response.text,'html.parser')
#用BeautifulSoup解析response。
datas = bs.find_all('tr',class_="item")
#用find_all提取<tr class="item">元素,这个元素里含有书籍信息。
for data in datas:
#遍历data。
item = DoubanItem()
#实例化DoubanItem这个类。
item['title'] = data.find_all('a')[1]['title']
#提取出书名,并把这个数据放回DoubanItem类的title属性里。
item['publish'] = data.find('p',class_='pl').text
#提取出出版信息,并把这个数据放回DoubanItem类的publish里。
item['score'] = data.find('span',class_='rating_nums').text
#提取出评分,并把这个数据放回DoubanItem类的score属性里。
print(item['title'])
#打印书名。
yield item
#yield item是把获得的item传递给引擎。当我们每一次,要记录数据的时候,比如前面在每一个最小循环里,都要记录“书名”,“出版信息”,“评分”。我们会实例化一个item对象,利用这个对象来记录数据。
每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。这里,要用到yield语句。
yield语句它有点类似return,不过它和return不同的点在于,它不会结束函数,且能多次返回信息。
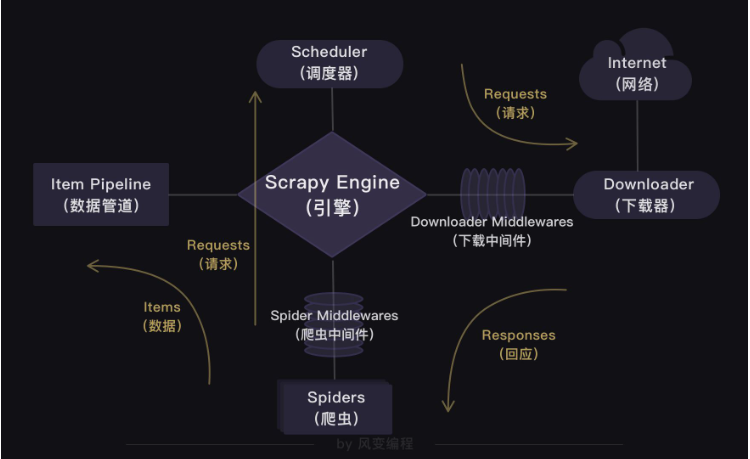
就如同上图所示:爬虫(Spiders)会把豆瓣的10个网址封装成requests对象,引擎会从爬虫(Spiders)里提取出requests对象,再交给调度器(Scheduler),让调度器把这些requests对象排序处理。然后引擎再把经过调度器处理的requests对象发给下载器(Downloader),下载器会立马按照引擎的命令爬取,并把response返回给引擎。
紧接着引擎就会把response发回给爬虫(Spiders),这时爬虫会启动默认的处理response的parse方法,解析和提取出书籍信息的数据,使用item做记录,返回给引擎。引擎将它送入Item Pipeline(数据管道)处理。
点击settings.py文件,把USER _AGENT的注释取消(删除#),然后替换掉user-agent的内容,就是修改了请求头。
因为Scrapy是遵守robots协议的,如果是robots协议禁止爬取的内容,Scrapy也会默认不去爬取,所以修改Scrapy中的默认设置。把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots协议换成无需遵从robots协议,这样Scrapy就能不受限制地运行。
想要运行Scrapy有两种方法,一种是在本地电脑的终端跳转到scrapy项目的文件夹
(跳转方法:cd+文件夹的路径名如:
cd D:\python\Pythoncode\douban\douban)
然后输入命令行:scrapy crawl douban(douban 就是我们爬虫的名字)。)
另一种运行方式需要我们在最外层的大文件夹里新建一个main.py文件(与scrapy.cfg同级)。
然后在这个main.py文件里,输入以下代码,点击运行,Scrapy的程序就会启动。
from scrapy import cmdline
#导入cmdline模块,可以实现控制终端命令行。
cmdline.execute(['scrapy','crawl','douban'])
#用execute()方法,输入运行scrapy的命令。第1行代码:在Scrapy中有一个可以控制终端命令的模块cmdline。导入了这个模块,我们就能操控终端。
第2行代码:在cmdline模块中,有一个execute方法能执行终端的命令行,不过这个方法需要传入列表的参数。我们想输入运行Scrapy的代码scrapy crawl douban,就需要写成[‘scrapy’,‘crawl’,‘douban’]这样。
在实际项目实战中,我们应该先定义数据,再写爬虫。所以,流程图应如下:
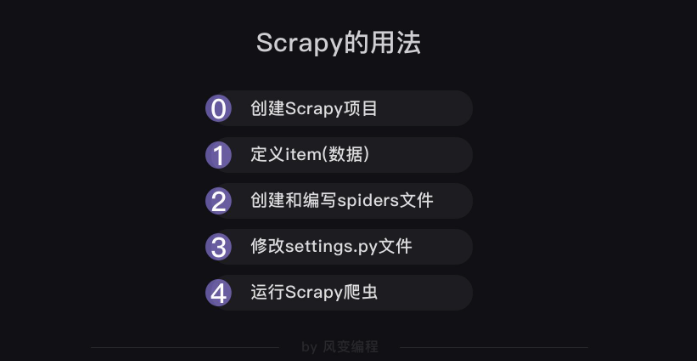
最后,存储数据需要修改pipelines.py文件
感谢各位的阅读,以上就是“如何用scrapy框架爬取豆瓣读书Top250的书类信息”的内容了,经过本文的学习后,相信大家对如何用scrapy框架爬取豆瓣读书Top250的书类信息这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://blog.csdn.net/weixin_53823523/article/details/115672417



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



