pythonдёӯзҡ„np.random.permutationеҮҪж•°жҖҺд№ҲдҪҝз”Ё
жң¬ж–Үе°Ҹзј–дёәеӨ§е®¶иҜҰз»Ҷд»Ӣз»ҚвҖңpythonдёӯnp.random.permutationеҮҪж•°жҖҺд№ҲдҪҝз”ЁвҖқпјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢз»ҶиҠӮеӨ„зҗҶеҰҘеҪ“пјҢеёҢжңӣиҝҷзҜҮвҖңpythonдёӯnp.random.permutationеҮҪж•°жҖҺд№ҲдҪҝз”ЁвҖқж–Үз« иғҪеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘеӯҰд№ ж–°зҹҘиҜҶеҗ§гҖӮ
дёҖ:еҮҪж•°д»Ӣз»Қ
np.random.permutation() жҖ»дҪ“жқҘиҜҙд»–жҳҜдёҖдёӘйҡҸжңәжҺ’еҲ—еҮҪж•°,е°ұжҳҜе°Ҷиҫ“е…Ҙзҡ„ж•°жҚ®иҝӣиЎҢйҡҸжңәжҺ’еҲ—,е®ҳж–№ж–ҮжЎЈжҢҮеҮә,жӯӨеҮҪж•°еҸӘиғҪй’ҲеҜ№дёҖз»ҙж•°жҚ®йҡҸжңәжҺ’еҲ—,еҜ№дәҺеӨҡз»ҙж•°жҚ®еҸӘиғҪеҜ№з¬¬дёҖз»ҙеәҰзҡ„ж•°жҚ®иҝӣиЎҢйҡҸжңәжҺ’еҲ—гҖӮ
з®ҖиҖҢиЁҖд№Ӣпјҡnp.random.permutationеҮҪж•°зҡ„дҪңз”Ёе°ұжҳҜжҢүз…§з»ҷе®ҡеҲ—иЎЁз”ҹжҲҗдёҖдёӘжү“д№ұеҗҺзҡ„йҡҸжңәеҲ—иЎЁ
еңЁеӨ„зҗҶж•°жҚ®йӣҶж—¶пјҢйҖҡеёёеҸҜд»ҘдҪҝз”ЁиҜҘеҮҪж•°иҝӣиЎҢжү“д№ұж•°жҚ®йӣҶеҶ…йғЁйЎәеәҸпјҢ并жҢүз…§еҗҢж ·зҡ„йЎәеәҸиҝӣиЎҢж ҮзӯҫеәҸеҲ—зҡ„жү“д№ұгҖӮ
дәҢ:е®һдҫӢ
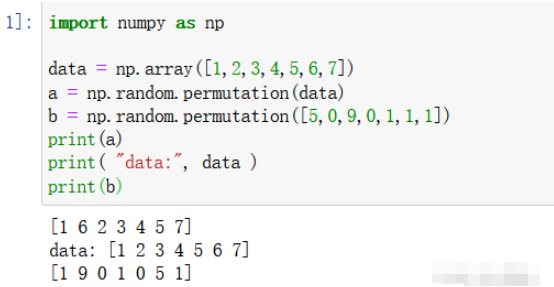
2.1 зӣҙжҺҘеӨ„зҗҶж•°з»„жҲ–еҲ—иЎЁж•°
import numpy as np
data = np.array([1,2,3,4,5,6,7])
a = np.random.permutation(data)
b = np.random.permutation([5,0,9,0,1,1,1])
print(a)
print( "data:", data )
print(b)
2.2 й—ҙжҺҘеӨ„зҗҶпјҡдёҚж”№еҸҳеҺҹж•°жҚ®пјҲеҜ№ж•°з»„дёӢж Үзҡ„еӨ„зҗҶпјү
label = np.array([1,2,3,4,5,6,7])
a = np.random.permutation(np.arange(len(label)))
print("Label[a] :" ,label[a] )
иЎҘпјҡдёҖиҲ¬еҸӘиғҪз”ЁдәҺNз»ҙж•°з»„ еҸӘиғҪе°Ҷж•ҙж•°ж ҮйҮҸж•°з»„иҪ¬жҚўдёәж ҮйҮҸзҙўеј•
why?label1[a1] label1жҳҜеҲ—иЎЁпјҢa1жҳҜеҲ—иЎЁдёӢж Үзҡ„йҡҸжңәжҺ’еҲ— дҪҶжҳҜпјҒ еҲ—иЎЁз»“жһ„жІЎжңүж ҮйҮҸзҙўеј• label1[a1]жҠҘй”ҷ
label1=[1,2,3,4,5,6,7]
print(len(label1))
a1 = np.random.permutation(np.arange(len(label1)))#жңүз»“жһң
print(a1)
print("Label1[a1] :" ,label1[a1] )#иҝҷеҲ—иЎЁз»“жһ„жІЎжңүж ҮйҮҸзҙўеј• жүҖд»ҘдјҡжҠҘй”ҷ
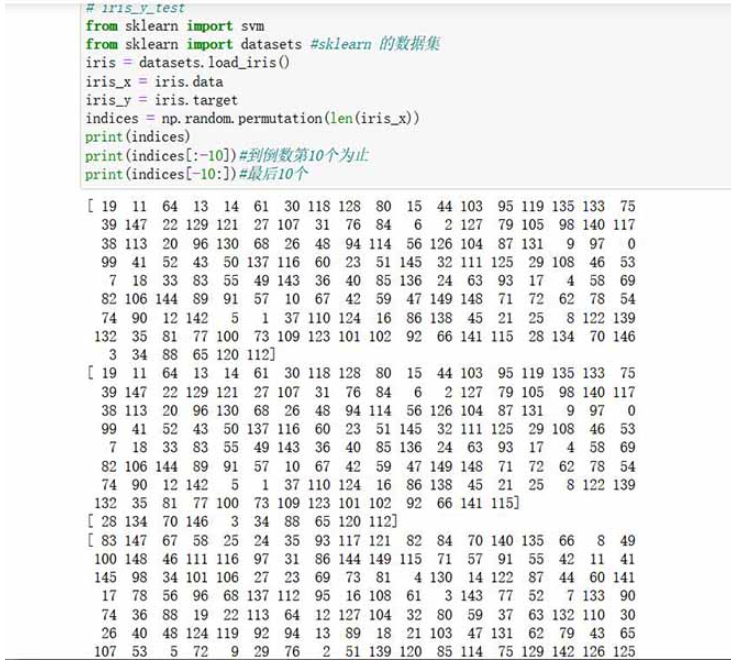
2.3 е®һдҫӢпјҡйёўе°ҫиҠұж•°жҚ®дёӯеҜ№йёўе°ҫиҠұзҡ„йҡҸжңәжү“д№ұ(еҸҜд»ҘзӣҙжҺҘз”Ёпјү
from sklearn import svm
from sklearn import datasets #sklearn зҡ„ж•°жҚ®йӣҶ
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
indices = np.random.permutation(len(iris_x))
#жӯӨж—¶ жү“д№ұзҡ„жҳҜж•°з»„зҡ„дёӢж Үзҡ„жҺ’еәҸ
print(indices)
print(indices[:-10])#еҲ°еҖ’数第10дёӘдёәжӯў
print(indices[-10:])#жңҖеҗҺ10дёӘ
# print(type(iris_x)) <class 'numpy.ndarray'>
#9:1еҲҶзұ»
#iris_x_train = iris_x[indices[:-10]]#дҪҝз”Ёзҡ„ж•°з»„жү“д№ұеҗҺзҡ„дёӢж Ү
#iris_y_train = iris_y[indices[:-10]]
#iris_x_test= iris_x[indices[-10:]]
#iris_y_test= iris_y[indices[-10:]]
ж•°з»„дёӢж Ү еҚіж ҮйҮҸзҙўеј•зҡ„йҮҚж–°еҲҶеёғжғ…еҶөпјҡ дёӢж ҮжҳҜ0ејҖе§Ӣ
иҜ»еҲ°иҝҷйҮҢпјҢиҝҷзҜҮвҖңpythonдёӯnp.random.permutationеҮҪж•°жҖҺд№ҲдҪҝз”ЁвҖқж–Үз« е·Із»Ҹд»Ӣз»Қе®ҢжҜ•пјҢжғіиҰҒжҺҢжҸЎиҝҷзҜҮж–Үз« зҡ„зҹҘиҜҶзӮ№иҝҳйңҖиҰҒеӨ§е®¶иҮӘе·ұеҠЁжүӢе®һи·өдҪҝз”ЁиҝҮжүҚиғҪйўҶдјҡпјҢеҰӮжһңжғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





