本篇内容介绍了“pytorch框架怎么应用”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor )库,在机器学习和其他数学密集型应用有广泛应用。与Tensorflow的静态计算图不同,pytorch的计算图是动态的,可以根据计算需要实时改变计算图。
a.pytorch相对于tensorflow出现的较晚一些,主要是针对深度神经网络而开发出来,这几年发展也是十分不错;tensorflow出现的较早,它的优点是分布式计算,在面临较大数据时相对效率较高;
b.pytorch是动态框架,tensorflow是静态框架,主要区别就是静态框架在构建计算图的时候提前构建好,之后则无法改变,固定了计算的流程,势必带来了不灵活性,如果我们要改变计算的逻辑,或者随着时间变化的计算逻辑,这样的动态计算TensorFlow是实现不了的;而动态框架可以根据具体计算情况进行改变
c.tensorflow的库相对完备齐全,而pytorch还在完善中;所以tensorflow在可视化方面十分出色;
d.pytorch对python十分友好,更加python化的框架,而tensorflow的话更加像独立的语言和框架
1. overview
pytorch 由低层到上层主要有三大块功能模块,如下图所示
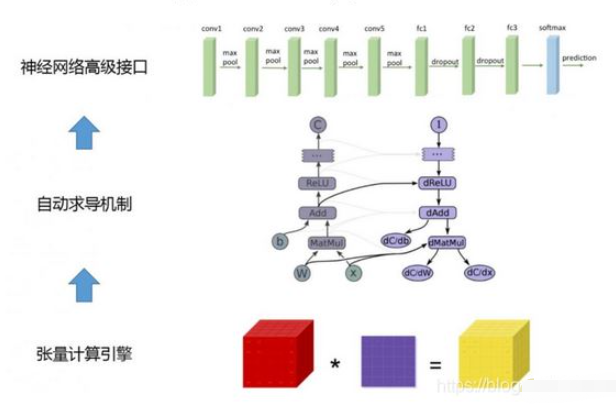
1.1 张量计算引擎(tensor computation)
Tensor 计算引擎,类似 numpy 和 matlab,基本对象是tensor(类比 numpy 中的 ndarray 或 matlab 中的 array)。除提供基于 CPU 的常用操作的实现外,pytorch 还提供了高效的 GPU 实现,这对于深度学习至关重要。
1.2 自动求导机制(autograd)
由于深度学习模型日趋复杂,因此,对自动求导的支持对于学习框架变得必不可少。pytorch 采用了动态求导机制,使用类似方法的框架包括: chainer,dynet。作为对比,theano,tensorflow 采用静态自动求导机制。
1.3 神经网络的高层库(NN)
pytorch 还提供了高层的。对于常用的网络结构,如全连接、卷积、RNN 等。同时,pytorch 还提供了常用的、optimizer 及参数。
2. 自定义 Module
2.1 Function
Function 是 pytorch 自动求导机制的核心类。Function 是无参数或者说无状态的,它只负责接收输入,返回相应的输出;对于反向,它接收输出相应的梯度,返回输入相应的梯度。
2.2 Module
类似于 Function,Module 对象也是 callable ,输入和输出也是 Variable。不同的是,Module 是[可以]有参数的。Module 包含两个主要部分:参数及计算逻辑(Function 调用)。由于ReLU激活函数没有参数,这里我们以最基本的全连接层为例来说明如何自定义Module。
| 名称 | 作用 |
|---|---|
| torch | 类似 NumPy 的张量库,强 GPU 支持 ; |
| torch.autograd | 基于 tape 的自动区别库,支持 torch 之中的所有可区分张量运行; |
| torch.nn | 为最大化灵活性未涉及、与 autograd 深度整合的神经网络库; |
| torch.optim | 与 torch.nn 一起使用的优化包,包含 SGD、RMSProp、LBFGS、Adam 等标准优化方式; |
| torch.multiprocessing | python 多进程并发,进程之间 torch Tensors 的内存共享; |
| torch.utils | 数据载入器。具有训练器和其他便利功能; |
| torch.legacy(.nn/.optim) | 处于向后兼容性考虑,从 Torch 移植来的 legacy 代码 |
| torchvision | 独立于pytorch的关于图像操作的一些方便工具库 |
和数值相关的
Tensor Variable Parameter
Tensor:
PyTorch中的计算基本都是基于Tensor的,可以说是PyTorch中的基本计算单元。
Variable:
Tensor的一个Wrapper,其中保存了Variable的创造者,Variable的值(tensor),还有Variable的梯度(Variable)。自动求导机制的核心组件,因为它不仅保存了 变量的值,还保存了变量是由哪个op产生的。这在反向传导的过程中是十分重要的。
Variable的前向过程的计算包括两个部分的计算,一个是其值的计算(即,Tensor的计算),还有就是Variable标签的计算。标签指的是什么呢?如果您看过PyTorch的官方文档 Excluding subgraphs from backward 部分的话,您就会发现Variable还有两个标签:requires_grad和volatile。标签的计算指的就是这个。
Parameter:
这个类是Variable的一个子集,PyTorch给出这个类的定义是为了在Module(下面会谈到)中添加模型参数方便。
模型相关的
Function Module
Function:
如果您想在PyTorch中自定义OP的话,您需要继承这个类,您需要在继承的时候复写forward和backward方法,可能还需要复写__init__方法(由于篇幅控制,这里不再详细赘述如果自定义OP)。您需要在forward中定义OP,在backward说明如何计算梯度。
关于Function,还需要知道的一点就是,Function中forward和backward方法中进行计算的类型都是Tensor,而不是我们传入的Variable。计算完forward和backward之后,会包装成Varaible返回。这种设定倒是可以理解的,因为OP是一个整体嘛,OP内部的计算不需要记录creator
Module:
这个类和Function是有点区别的,回忆一下,我们定义Function的时候,Funciton本身是不需要变量的,而Module是变量和Function的结合体。在某些时候,我们更倾向称这种结构为Layer。但是这里既然这么叫,那就这么叫吧。
Module实际上是一个容器,我们可以继承Module,在里面加几个参数,从而实现一个简单全连接层。我们也可以继承Module,在里面加入其它Module,从而实现整个VGG结构。
“pytorch框架怎么应用”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





