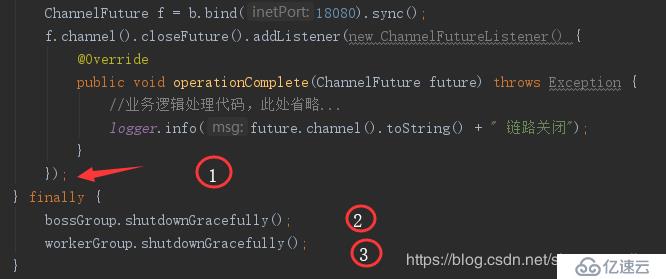
由于代码1处执行完后直接进入2、3,那么netty服务端就会关闭退出。
解决一、直接在代码1后面处加上同步阻塞sync,那么只有服务端正常关闭channel时才会执行下面的语句
解决二、把代码2和3移到operationComplete里面,那么也只有channel关闭时才会让netty的两个线程组关闭
生产环境用netty作为客户端,为了提高性能,客户端与服务端创建多条链路,同时客户端创建一个TCP连接池。结果业务高峰期OOM

从异常日志和线程资源占用来看,导致内存泄漏的原因是应用创建了大量的EventLoopGroup线程池。这就是一个TCP连接对应一个NIO线程的模式。错误之在就是采用BIO模式来调用NIO通信框架,不仅没优化效果,还发生了OOM。
正确操作是

注意:Bootstrap自身不是线程安全的,但执行Bootstrap的连接操作是串行执行的。connect方法它会创建一个新的NioSocketChannel,并从初始构造的EventLoopGroup中选择一个NioEventLoop线程执行真正的Channel连接操作,与执行Boostrap的线程无关。在同一个Boostrap创建多个客户端连接,EventLoopGroup是共享的,这些连接共用同一个NIO线程组EventLoopGroup,当某个链路发生异常或关闭时,只需要关闭并释放Channel本身即可,不能同时销毁NioEventLoop和所在线程组EventLoopGroup,下方是错误代码

Bootstrap不是线程安全的,因此在多个线程中并发操作Bootstrap是比较危险而且没有意义。

在调用ctx.writeAndFlush方法时,当消息发送完成,Netty会主动帮助应用释放内存,内存释放场景如下
(1)如果是堆内存(PooledHeapByteBuf),则将HeapByteBuffer转换成DirectByteBuffer,并释放PooledHeapByteBuf到内存池。
(2)如果是DirectByteBuffer,则不需要转换,在消息发送完成后,由ChannelOutboundBuffer的remove方法负责释放
为了在实际项目中更好地管理ByteBuf,下面分4种场景说明
(1)基于内存池的请求ByteBuf,这类主要包括PooledDirectByteBuf和PooledHeapByteBuf,它由NioEventLoop线程在处理Channel读操作时分配,需要在业务ChannelInboundHandler处理完请求消息后释放(通常在解码之后),它的释放策略如下:
ChannelInboundHandler继承自SimpleChannelInboundHandler,实现它的抽象方法channelRead0,ByteBuf的释放业务不用关心,由SimpleChannelInboundHandler负责释放
在业务ChannelInboundHandler中调用ctx.fireChannelRead(msg),让请求继续向后执行,直至调用DefaultChannelPipeline的内部类TailContext,由它负责释放请求信息
直接调用在channelRead方法里调用ReferenceCountUtil.release(reqMsg)
(2) 基于非内存池的请求ByteBuf,它也是需要按照内存池的方式释放内存
(3)基于内存池的响应ByteBuf,根据之前的分析,只要调用了writeAndFlush或flush方法,在消息发送完成后都会由Netty框架进行内存释放,业务不需要主动释放内存
(4)基于非内存池的响应ByteBuf,业务不需要主动释放内存
当然非内存池也不一定要手动释放,但最好手动释放。Netty里有4种主力的ByteBuf,其中UnpooledHeapByteBuf底下的byte[]能够依赖JVM GC自然回收;而UnpooledDirectByteBuf底下是DirectByteBuffer,是Java堆外内存,除了等JVM GC,最好也能主动进行回收,否则导致内存不足也产生内存泄露的假象;而PooledHeapByteBuf和PooledDirectByteBuf,则必须要主动将用完的byte[]/ByteBuffer放回池里,否则内存就要爆掉。
对于内存池泄露可以的监控可以配置启动参数

不同参数信息如下:
DISABLED 完全关闭内存泄露检测,并不建议
SIMPLE 以1%的抽样率检测是否泄露,默认级别
ADVANCED 抽样率同SIMPLE,但显示详细的泄露报告
PARANOID 抽样率为100%,显示报告信息同ADVANCED
最后,悄悄告诉你,网上的你些netty入门demo大都存在内存池泄露问题,只不过数据量传输少,可能运行大半年才会出现LEAK,就连《netty权威指南》入门demo也存在这个问题,也许就只是个入门demo,所以不弄得太复杂。什么你不信,你可以在入门demo的TimeClientHandler或TimeServerHandler加上下面这坨代码。
ByteBuf firstMessage = null;
for (int j = 0; j < Integer.MAX_VALUE; j++) {
firstMessage = Unpooled.buffer(1024);
for (int i = 0; i < firstMessage.capacity(); i ++) {
firstMessage.writeByte((byte) i);
}
ctx.writeAndFlush(firstMessage);
}妥妥的
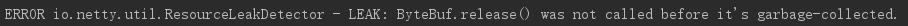
这就是为什么很多人照抄网上的demo仍会出现内存池泄露的原因
客户端频繁发送消息可以导致发送队列积压,进而内存增大,响应时间长,CPU占用高。

此时我们可以为客户端设置高低水位机制,防止自身队列消息积压


此外,除了客户端消息队列积压也可能因网络链接处理能力、服务器读取速度小于己方发送速度有关。所以在日常监控中,需要将Netty的链路数、网络读写速度等指标纳入监控系统,发现问题之后需要及时告警。
服务端转发请求
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ctx.write(msg);
char [] req = new char[64 * 1024];
executorService.execute(()->
{
char [] dispatchReq = req;
//简单处理之后,转发请求消息到后端服务,代码省略
try
{
//模拟业务逻辑处理耗时
TimeUnit.MICROSECONDS.sleep(100);
}catch (Exception e)
{
e.printStackTrace();
}
});
}结果发现内存和CPU占用高,同时QPS下降,停止压测一段时间,CPU占用和内存下降,QPS恢复正常。
用MAT分析


得出是线程池的char[]积压,进入老年代,导致频繁full gc。究其原因是,每次都创建64kb的char来存放处理消息,哪怕实际接收消息有 100字节。修改char大小为消息大小,问题得到解决

原因:在handler里面是直接处理业务信息,导致IO的操作阻塞,无法读取Client端发来的消息
建议将业务操作将由另一个线程处理,而不应放在IO线程里处理
推荐线程的计算公式:
(1) 线程数量=(线程总时间/瓶颈资源时间)*瓶颈资源的线程并行数
(2)QPS=1000/线程总时间*线程数
1、版本升级后偶现服务端发送给客户端的应答数据被篡改?
netty升级4后,线程模型发生变化,响应消息的编码由NioEventLoop线程异步执行,业务线程返回。这时如果编码操作在修改应答消息的业务逻辑后执行,则运行结果错误,数据被篡改。
2、升级后为什么上下文丢失问题?
Netty4修改了outbound的线程模型,正好影响了业务消息发送时的上下文传递,最终导致业务线程变量丢失
3、升级后没有像官方描述那样性能得到提升,反而下降了?
可将耗时的反序列操作放到业务线程里,而不是ChannelHandler,因为Netty4只有一个NioEventLoop线程来处理这个操作,业务耗时ChannelHandler被I/O线程串行执行,所以执行效率低。Netty3在消息发送线程模型上,充分利用业务线程的并行编码和ChanelHandler的优势,在一个周期T内可以处理N条业务消息。
性能优化建议:适当高大work线程组的线程数(NioEventLoopGroup),分担每个NioEventLoop线程的负载,提升ChannelHandler执行的并发度。同时,将业务上耗时的操作从ChannelHandler移除,放入业务线程池处理。对于不合适转移到业务线程处理的一些耗时逻辑,也可以通过为ChannelHandler绑定线程池的方式提升性能。Netty3的Downstream由业务线程执行,意味着某一时刻有多个业务线程同时操作ChannelHandler,用户需要并发保护。
server端使用netty自带的线程池来处理业务

而client端如下

实际结果server端的QPS只有个位数,究其原因是一个tcp连接对应一个channel,一个channel就对应一个DefaultEventExecutor(业务线程) 执行,所以它虽然给channel绑定线程池,但一个channel还是一个业务线程在处理。解决办法是在ChannelHandler里面再创建一个线程池,此时就能利用线程池的并行处理能力。

当然, server端使用netty自带的线程池来处理业务,它的用法是当建立多个tcp连接时,每个连接能对应一个线程来处理ChannelHandler。所以它在多tcp连接时能提高业务的并行处理能力。
Netty提供的业务线程池能降低了锁竞争,提升了系统的并发处理性能。如果使用业务自定义实现的线程池,如果追求更高的性能,就要在消除或减轻锁竞争上下工夫(ThreadPoolExecutor采用的是“一个阻塞队列+N个工作线程”的模型,如果业务线程数比较多,就会形成激烈的锁竞争)
可用流量×××方案, 流量×××和流控的最大区别在于,流控会拒绝消息,流量×××不拒绝和丢弃消息,无论接收量多大,它总能以近似恒定的速度下发消息,跟变压器的原理和功能类似。
接收端代码如下:
// 配置服务端的NIO线程组
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 100)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast("Channel Traffic Shaping", new ChannelTrafficShapingHandler(1024 * 1024, 1024 * 1024, 1000));
ByteBuf delimiter = Unpooled.copiedBuffer("$_"
.getBytes());
ch.pipeline().addLast(
new DelimiterBasedFrameDecoder(2048 * 1024,
delimiter));
ch.pipeline().addLast(new StringDecoder());
ch.pipeline().addLast(new TrafficShapingServerHandler());
}
});
// 绑定端口,同步等待成功
ChannelFuture f = b.bind(port).sync();
// 等待服务端监听端口关闭
f.channel().closeFuture().sync();
} finally {
// 优雅退出,释放线程池资源
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





