本篇内容介绍了“Java中怎么对字符串进行utf-8编码”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
我们在调用第三方 API 时,常常会被要求用到路径变量,而路径变量一般都是 utf-8 编码的,因此需要对传入的字符串参数进行 utf-8 编码处理。
本文提供一种使用 URLEncoder 库进行编码的方式。
废话少说,上代码。
// 使用 URLEncoder 库对字符串进行 utf-8 编码
import java.net.URLEncoder;
public String encodePathVariable(String pathVariable) {
String ret = "default";
try {
ret = URLEncoder.encode(pathVariable, "utf-8");
System.out.println(pathVariable + " : " + ret);
}catch(Exception e) {
System.out.println(e);
}
return ret;
}如何按照utf-8的字节截取字符串呢?
utf-8,中文一个汉字是三个字节,一个字母或特殊符号是1个字节。
String类没有提供按字节截取字符串的方法,
StringUtil提供了截取的方法,但是默认是8858-1的,而且不能指定编码格式
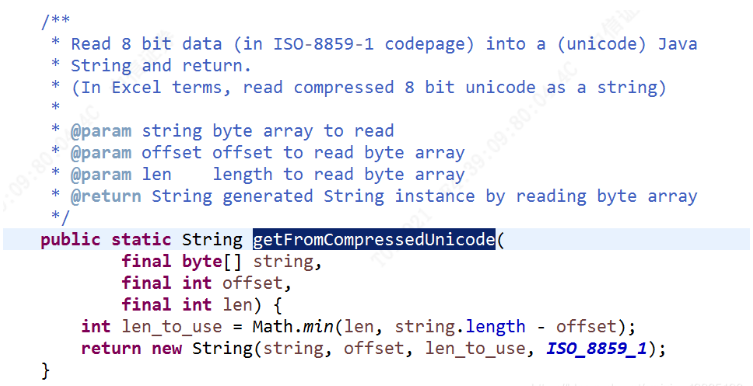
但是给了我们思路,我们就将这段代码粘贴出来,将后面的编码格式给改成utf-8的

建个测试方法测试下
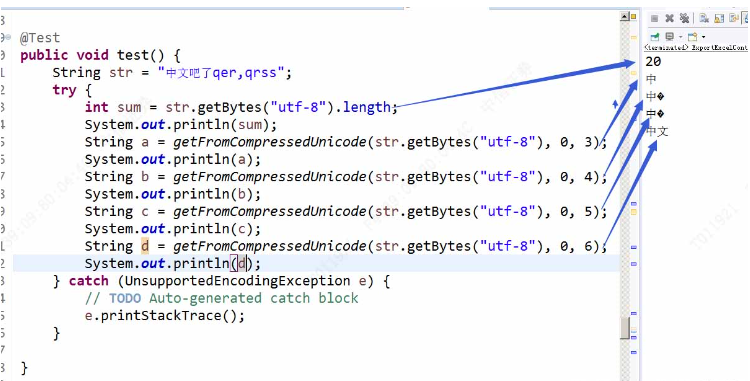
还是有些问题,截取3个字节时,正好把中字截取出来了,4个字节时有乱码,5个字节时,还有乱码,6个字节时,打印了两个字节,正好两个中文汉字。也就是说,本身是三个字节的文字,我们只取了它的1个字节,所以识别不出来出现了乱码!
经过反复测试,乱码就是�这种符号,别的符号没测出来,应该也没啥别的符号,我们就将这种符号截取掉就行了。
最后测试的代码

乱码没有了,而且准确率还高,因为字符串的情况挺复杂的,什么都有,文字,标点,特殊符号,穿插其中,字节也不一样,网上看了很多例子,都是他们自己编写的算法啥的,用了之后,错误率挺高的。
/**
*string:字符串
offset:从哪个字节开始
len:从哪个字节结束
*/
public static String getFromCompressedUnicode(String string,int offset,int len) throws UnsupportedEncodeingException{
byte[] bytes = string.getBytes("utf-8");
int len_to_use = Math.min(len,bytes.length - offset);
return new String(bytes,offset,len_to_use,"utf-8").replaceAll("�","")
}“Java中怎么对字符串进行utf-8编码”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://blog.csdn.net/qq_39249627/article/details/125132429



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



