这篇文章主要介绍了Pandas怎么封装Excel工具类的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Pandas怎么封装Excel工具类文章都会有所收获,下面我们一起来看看吧。
Excel是一种广泛使用的电子表格软件,它提供了大量的数据处理和计算功能,被广泛应用于数据分析和报告中。在Python中,我们可以使用pandas库来读写和处理Excel文件。但是,为了更方便和快速地操作Excel文件,我们可以封装一个Excel工具类,提供常用的读写操作方法,以提高开发效率。
这个方法可以将数据集列表转换为Excel文件。该方法使用pd.ExcelWriter()创建Excel文件写入器,然后使用pd.DataFrame()创建一个数据帧对象,再将其写入Excel文件中。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author: Hui
# @Desc: { Excel文件操作工具模块 }
# @Date: 2022/04/03 19:34
import pandas as pd
from typing import List, Union, Dict, IO
class ExcelUtils(object):
""" Excel文件操作工具类 """
@classmethod
def list_to_excel(
cls,
path_or_buffer: Union[str, IO],
data_list: list,
col_mapping: dict = None,
sheet_name: str = 'Sheet1',
**kwargs
):
"""
列表转 excel文件
Args:
path_or_buffer: 文件路径或者缓冲流
data_list: 数据集 List[dict]
col_mapping: 表头列字段映射
sheet_name: sheet名称
Returns:
"""
with pd.ExcelWriter(path_or_buffer) as writer:
_col_mapping = list(col_mapping) if col_mapping else None
df = pd.DataFrame(data=data_list, columns=_col_mapping)
if col_mapping:
df.rename(columns=col_mapping, inplace=True)
df.to_excel(writer, sheet_name=sheet_name, index=False, **kwargs)这里path_or_buffer可以是一个文件路径或者一个缓冲流对象,data_list是一个列表,包含需要写入Excel的数据。col_mapping是一个字典,用于将表头列字段映射到数据集的字段名。
# 示例
user_list = [
dict(id=1, name='hui', age=20),
dict(id=2, name='wang', age=22),
dict(id=3, name='zack', age=25),
]
user_col_mapping = {
'id': '用户id',
'name': '用户名',
'age': '年龄',
}
ExcelUtils.list_to_excel('user.xlsx', user_list, col_mapping=user_col_mapping)
# 导出为excel文件字节流处理
excel_bio = BytesIO()
ExcelUtils.list_to_excel(
excel_bio,
data_list=user_list,
col_mapping=user_col_mapping,
sheet_name='demo'
)
excel_bytes = excel_bio.getvalue()
print("excel_bytes type => ", type(excel_bytes))
>>>out
excel_bytes type => <class 'bytes'>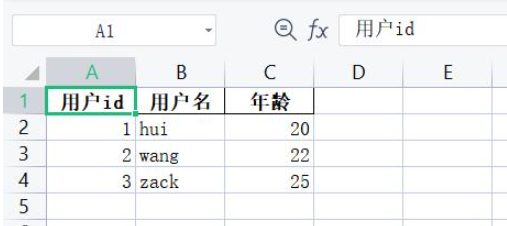
这个例子将一个用户数据集写入一个Excel文件中,并将列名映射为中文,也可以将excel保存在缓存流中(字节数据),在一些web场景中可以更方便的将缓冲流响应给前端、或者上传到一些OSS中,这样就不用创建临时文件、读取、上传。
如果有多个数据集需要写入到同一个Excel文件中,可以使用该方法。它与前面的方法类似,但接受一个列表,列表中包含多个数据集及其对应的表头列字段映射和sheet名称。
将多个数据列表写入到一个Excel文件中。
@classmethod def multi_list_to_excel( cls, path_or_buffer: Union[str, IO], data_collects: List[tuple], **kwargs ): """ 多列表转带不同 sheet的excel文件 Args: path_or_buffer: 文件路径或者缓冲流 data_collects: 大数据集 list[(data_collect, col_mapping, sheet_name)] data_collect: 数据集, col_mapping: 列字段映射, sheet_name: excel表sheet名称 Returns: """ with pd.ExcelWriter(path_or_buffer) as writer: for data_collect, col_mapping, sheet_name in data_collects: df = pd.DataFrame(data=data_collect, columns=list(col_mapping)) df.rename(columns=col_mapping, inplace=True) df.to_excel(writer, sheet_name=sheet_name, index=False, **kwargs)
参数说明:
path_or_buffer: 文件路径或者缓冲流;
data_collects: 多个数据列表的元组集合,每个元组包含三个元素:需要写入到Excel文件中的数据列表,列名与字典key的映射,Excel文件的sheet名称。
示例:
user_list = [
{'id': 1, 'name': 'hui', 'age': 18},
{'id': 2, 'name': 'wang', 'age': 19},
{'id': 3, 'name': 'zack', 'age': 20}
]
book_list = [
{'id': 1, 'name': 'Python基础教程', 'author': 'hui', 'price': 30},
{'id': 2, 'name': 'Java高级编程', 'author': 'wang', 'price': 50},
{'id': 3, 'name': '机器学习实战', 'author': 'zack', 'price': 70},
]
user_col_mapping = {'id': '编号', 'name': '姓名', 'age': '年龄'}
book_col_mapping = {'id': '编号', 'name': '书名', 'author': '作者', 'price': '价格'}
data_collects = [
(user_list, user_col_mapping, '用户信息'),
(book_list, book_col_mapping, '图书信息')
]
ExcelUtils.multi_list_to_excel('multi_sheet_data.xlsx', data_collects)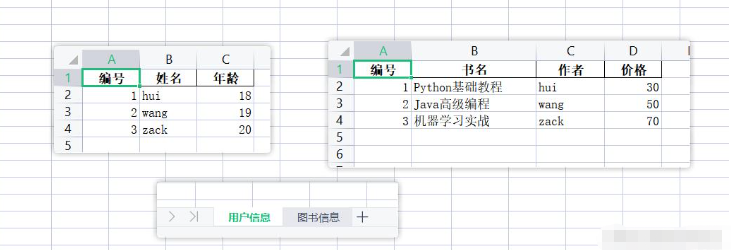
感觉这方法参数太多,不太容易知道如何入参,后续可以用dataclass抽出结构来入参这样更好理解点。
@classmethod
def read_excel(
cls,
path_or_buffer: Union[str, IO],
sheet_name: str = "Sheet1",
col_mapping: dict = None,
all_col: bool = True,
header: int = 0,
**kwargs
) -> List[dict]:
"""
读取excel表格数据,根据col_mapping替换列名
Args:
path_or_buffer: 文件路径或者缓冲流
sheet_name: 读书excel表的sheet名称
col_mapping: 列字段映射
all_col: True返回所有列信息,False则返回col_mapping对应的字段信息
header: 默认0从第一行开启读取,用于指定从第几行开始读取
Returns:
"""
use_cols = None
if not all_col:
# 获取excel表指定列数据
use_cols = list(col_mapping) if col_mapping else None
df = pd.read_excel(path_or_buffer, sheet_name=sheet_name, usecols=use_cols, header=header, **kwargs)
if col_mapping:
df.rename(columns=col_mapping, inplace=True)
return df.to_dict("records")示例代码:
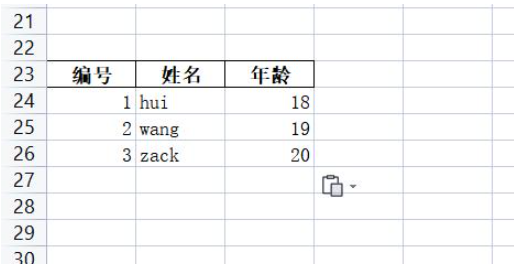
data = [
{"id": 1, "name": "hui", "age": 30},
{"id": 2, "name": "zack", "age": 25},
{"id": 3, "name": "wang", "age": 40},
]
# 将数据写入Excel文件
ExcelUtils.list_to_excel("read_demo.xlsx", data, col_mapping={"id": "用户ID", "name": "姓名", "age": "年龄"})
# 读取Excel文件
result = ExcelUtils.read_excel("read_demo.xlsx", col_mapping={"用户ID": "id", "姓名": "name"})
print(result)
>>>out
[{'id': 1, 'name': 'hui'}, {'id': 2, 'name': 'zack'}, {'id': 3, 'name': 'wang'}]可以将字典列表数据根据列字段映射转换成中文表头的excel,读取excel时也可以将中文表头转成对应业务字段。
有些模板excel文件默认前几行是说明文字,因此可以指定header参数来跳过这些说明文字,这里只是把一些常用的参数封装了下,**kwargs 还是可以使用pandas的一些参数。
@classmethod
def merge_excel_files(
cls,
input_files: List[str],
output_file: str,
sheet_name_mapping: Dict[str, str] = None,
**kwargs
):
"""
合并多个Excel文件到一个文件中(每个文件对应一个工作表)
如果Excel文件有多个作表,则默认取第一个工作表
Args:
input_files: 待合并的excel文件列表
output_file: 输出文件路径
sheet_name_mapping: 文件工作表映射,默认为文件名
{"文件名1": "sheet1", "文件名2": "sheet2"}
Returns:
"""
sheet_name_mapping = sheet_name_mapping or {}
with pd.ExcelWriter(output_file, **kwargs) as writer:
for file in input_files:
df = pd.read_excel(file)
sheet_name = sheet_name_mapping.get(file, file)
df.to_excel(writer, sheet_name=sheet_name, index=False)示例:
def merge_excel_files_demo():
# 合并多个Excel文件
ExcelUtils.merge_excel_files(
input_files=["user.xlsx", "multi_sheet_data.xlsx"],
output_file="merged_data.xlsx",
sheet_name_mapping={
"user.xlsx": "user",
"multi_sheet_data.xlsx": "multi_sheet_data"
}
)
关于“Pandas怎么封装Excel工具类”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Pandas怎么封装Excel工具类”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





