жҖҺд№ҲдҪҝз”ЁPythonе®һзҺ°йҒ—дј з®—жі•
иҝҷзҜҮвҖңжҖҺд№ҲдҪҝз”ЁPythonе®һзҺ°йҒ—дј з®—жі•вҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңжҖҺд№ҲдҪҝз”ЁPythonе®һзҺ°йҒ—дј з®—жі•вҖқж–Үз« еҗ§гҖӮ
йҒ—дј з®—жі•е…·дҪ“жӯҘйӘӨпјҡ
пјҲ1пјүеҲқе§ӢеҢ–пјҡи®ҫзҪ®иҝӣеҢ–д»Јж•°и®Ўж•°еҷЁ t=0гҖҒи®ҫзҪ®жңҖеӨ§иҝӣеҢ–д»Јж•° TгҖҒдәӨеҸүжҰӮзҺҮгҖҒеҸҳејӮжҰӮзҺҮгҖҒйҡҸжңәз”ҹжҲҗ M дёӘдёӘдҪ“дҪңдёәеҲқе§Ӣз§ҚзҫӨ P
пјҲ2пјүдёӘдҪ“иҜ„д»·пјҡи®Ўз®—з§ҚзҫӨ P дёӯеҗ„дёӘдёӘдҪ“зҡ„йҖӮеә”еәҰ
пјҲ3пјүйҖүжӢ©иҝҗз®—пјҡе°ҶйҖүжӢ©з®—еӯҗдҪңз”ЁдәҺзҫӨдҪ“гҖӮд»ҘдёӘдҪ“йҖӮеә”еәҰдёәеҹәзЎҖпјҢйҖүжӢ©жңҖдјҳдёӘдҪ“зӣҙжҺҘйҒ—дј еҲ°дёӢдёҖд»ЈжҲ–йҖҡиҝҮй…ҚеҜ№дәӨеҸүдә§з”ҹж–°зҡ„дёӘдҪ“еҶҚйҒ—дј еҲ°дёӢдёҖд»Ј
пјҲ4пјүдәӨеҸүиҝҗз®—пјҡеңЁдәӨеҸүжҰӮзҺҮзҡ„жҺ§еҲ¶дёӢпјҢеҜ№зҫӨдҪ“дёӯзҡ„дёӘдҪ“дёӨдёӨиҝӣиЎҢдәӨеҸү
пјҲ5пјүеҸҳејӮиҝҗз®—пјҡеңЁеҸҳејӮжҰӮзҺҮзҡ„жҺ§еҲ¶дёӢпјҢеҜ№зҫӨдҪ“дёӯзҡ„дёӘдҪ“иҝӣиЎҢеҸҳејӮпјҢеҚіеҜ№жҹҗдёҖдёӘдҪ“зҡ„еҹәеӣ иҝӣиЎҢйҡҸжңәи°ғж•ҙ
пјҲ6пјү з»ҸиҝҮйҖүжӢ©гҖҒдәӨеҸүгҖҒеҸҳејӮиҝҗз®—д№ӢеҗҺеҫ—еҲ°дёӢдёҖд»ЈзҫӨдҪ“ P1гҖӮ
йҮҚеӨҚд»ҘдёҠпјҲ1пјү-пјҲ6пјүпјҢзӣҙеҲ°йҒ—дј д»Јж•°дёә TпјҢд»ҘиҝӣеҢ–иҝҮзЁӢдёӯжүҖеҫ—еҲ°зҡ„е…·жңүжңҖдјҳйҖӮеә”еәҰдёӘдҪ“дҪңдёәжңҖдјҳи§Јиҫ“еҮәпјҢз»Ҳжӯўи®Ўз®—гҖӮ
ж—…иЎҢжҺЁй”Җе‘ҳй—®йўҳпјҲTravelling Salesman ProblemпјҢ TSPпјүпјҡжңү n дёӘеҹҺеёӮпјҢдёҖдёӘжҺЁй”Җе‘ҳиҰҒд»Һе…¶дёӯжҹҗдёҖдёӘеҹҺеёӮеҮәеҸ‘пјҢе”ҜдёҖиө°йҒҚжүҖжңүзҡ„еҹҺеёӮпјҢеҶҚеӣһеҲ°д»–еҮәеҸ‘зҡ„еҹҺеёӮпјҢжұӮжңҖзҹӯзҡ„и·ҜзәҝгҖӮ
еә”з”ЁйҒ—дј з®—жі•жұӮи§Ј TSP й—®йўҳж—¶йңҖиҰҒиҝӣиЎҢдёҖдәӣзәҰе®ҡпјҢеҹәеӣ жҳҜдёҖз»„еҹҺеёӮеәҸеҲ—пјҢйҖӮеә”еәҰжҳҜжҢүз…§иҝҷдёӘеҹәеӣ зҡ„еҹҺеёӮйЎәеәҸзҡ„и·қзҰ»е’ҢеҲҶд№ӢдёҖгҖӮ
1.2 е®һйӘҢд»Јз Ғ
import random
import math
import matplotlib.pyplot as plt
# иҜ»еҸ–ж•°жҚ®
f=open("test.txt")
data=f.readlines()
# е°ҶcitiesеҲқе§ӢеҢ–дёәеӯ—е…ёпјҢйҳІжӯўдёӢйқўиў«еҪ“жҲҗеҲ—иЎЁ
cities={}
for line in data:
#еҺҹе§Ӣж•°жҚ®д»Ҙ\nжҚўиЎҢпјҢе°Ҷе…¶жӣҝжҚўжҺү
line=line.replace("\n","")
#жңҖеҗҺдёҖиЎҢд»ҘEOFдёәж Үеҝ—пјҢеҰӮжһңиҜ»еҲ°е°ұиҜҒжҳҺиҜ»е®ҢдәҶпјҢйҖҖеҮәеҫӘзҺҜ
if(line=="EOF"):
break
#з©әж јеҲҶеүІеҹҺеёӮзј–еҸ·е’ҢеҹҺеёӮзҡ„еқҗж Ү
city=line.split(" ")
map(int,city)
#е°ҶеҹҺеёӮж•°жҚ®ж·»еҠ еҲ°citiesдёӯ
cities[eval(city[0])]=[eval(city[1]),eval(city[2])]
# и®Ўз®—йҖӮеә”еәҰпјҢд№ҹе°ұжҳҜи·қзҰ»еҲҶд№ӢдёҖпјҢиҝҷйҮҢз”ЁдјӘ欧ж°Ҹи·қзҰ»
def calcfit(gene):
sum=0
#жңҖеҗҺиҰҒеӣһеҲ°еҲқе§ӢеҹҺеёӮжүҖд»Ҙд»Һ-1пјҢд№ҹе°ұжҳҜжңҖеҗҺдёҖдёӘеҹҺеёӮз»•дёҖеңҲеҲ°жңҖеҗҺдёҖдёӘеҹҺеёӮ
for i in range(-1,len(gene)-1):
nowcity=gene[i]
nextcity=gene[i+1]
nowloc=cities[nowcity]
nextloc=cities[nextcity]
sum+=math.sqrt(((nowloc[0]-nextloc[0])**2+(nowloc[1]-nextloc[1])**2)/10)
return 1/sum
# жҜҸдёӘдёӘдҪ“зҡ„зұ»пјҢж–№дҫҝж №жҚ®еҹәеӣ и®Ўз®—йҖӮеә”еәҰ
class Person:
def __init__(self,gene):
self.gene=gene
self.fit=calcfit(gene)
class Group:
def __init__(self):
self.GroupSize=100 #з§ҚзҫӨ规模
self.GeneSize=48 #еҹәеӣ ж•°йҮҸпјҢд№ҹе°ұжҳҜеҹҺеёӮж•°йҮҸ
self.initGroup()
self.upDate()
#еҲқе§ӢеҢ–з§ҚзҫӨпјҢйҡҸжңәз”ҹжҲҗиӢҘе№ІдёӘдҪ“
def initGroup(self):
self.group=[]
i=0
while(i<self.GroupSize):
i+=1
#geneеҰӮжһңеңЁforд»ҘеӨ–з”ҹжҲҗеҸӘдјҡshuffleдёҖж¬Ў
gene=[i+1 for i in range(self.GeneSize)]
random.shuffle(gene)
tmpPerson=Person(gene)
self.group.append(tmpPerson)
#иҺ·еҸ–з§ҚзҫӨдёӯйҖӮеә”еәҰжңҖй«ҳзҡ„дёӘдҪ“
def getBest(self):
bestFit=self.group[0].fit
best=self.group[0]
for person in self.group:
if(person.fit>bestFit):
bestFit=person.fit
best=person
return best
#и®Ўз®—з§ҚзҫӨдёӯжүҖжңүдёӘдҪ“зҡ„е№іеқҮи·қзҰ»
def getAvg(self):
sum=0
for p in self.group:
sum+=1/p.fit
return sum/len(self.group)
#ж №жҚ®йҖӮеә”еәҰпјҢдҪҝз”ЁиҪ®зӣҳиөҢиҝ”еӣһдёҖдёӘдёӘдҪ“пјҢз”ЁдәҺйҒ—дј дәӨеҸү
def getOne(self):
#sectionзҡ„з®Җз§°пјҢеҢәй—ҙ
sec=[0]
sumsec=0
for person in self.group:
sumsec+=person.fit
sec.append(sumsec)
p=random.random()*sumsec
for i in range(len(sec)):
if(p>sec[i] and p<sec[i+1]):
#иҝҷйҮҢжіЁж„ҸеҢәй—ҙжҳҜжҜ”дёӘдҪ“еӨҡдёҖдёӘ0зҡ„
return self.group[i]
#жӣҙж–°з§ҚзҫӨзӣёе…ідҝЎжҒҜ
def upDate(self):
self.best=self.getBest()
# йҒ—дј з®—жі•зҡ„зұ»пјҢе®ҡд№үдәҶйҒ—дј гҖҒдәӨеҸүгҖҒеҸҳејӮзӯүж“ҚдҪң
class GA:
def __init__(self):
self.group=Group()
self.pCross=0.35 #дәӨеҸүзҺҮ
self.pChange=0.1 #еҸҳејӮзҺҮ
self.Gen=1 #д»Јж•°
#еҸҳејӮж“ҚдҪң
def change(self,gene):
#жҠҠеҲ—иЎЁйҡҸжңәзҡ„дёҖж®өеҸ–еҮә然еҗҺеҶҚйҡҸжңәжҸ’е…ҘжҹҗдёӘдҪҚзҪ®
#lengthжҳҜеҸ–еҮәеҹәеӣ зҡ„й•ҝеәҰпјҢpostakeжҳҜеҸ–еҮәзҡ„дҪҚзҪ®пјҢposinsжҳҜжҸ’е…Ҙзҡ„дҪҚзҪ®
geneLenght=len(gene)
index1 = random.randint(0, geneLenght - 1)
index2 = random.randint(0, geneLenght - 1)
newGene = gene[:] # дә§з”ҹдёҖдёӘж–°зҡ„еҹәеӣ еәҸеҲ—пјҢд»Ҙе…ҚеҸҳејӮзҡ„ж—¶еҖҷеҪұе“ҚзҲ¶з§ҚзҫӨ
newGene[index1], newGene[index2] = newGene[index2], newGene[index1]
return newGene
#дәӨеҸүж“ҚдҪң
def cross(self,p1,p2):
geneLenght=len(p1.gene)
index1 = random.randint(0, geneLenght - 1)
index2 = random.randint(index1, geneLenght - 1)
tempGene = p2.gene[index1:index2] # дәӨеҸүзҡ„еҹәеӣ зүҮж®ө
newGene = []
p1len = 0
for g in p1.gene:
if p1len == index1:
newGene.extend(tempGene) # жҸ’е…Ҙеҹәеӣ зүҮж®ө
p1len += 1
if g not in tempGene:
newGene.append(g)
p1len += 1
return newGene
#иҺ·еҸ–дёӢдёҖд»Ј
def nextGen(self):
self.Gen+=1
#nextGenд»ЈиЎЁдёӢдёҖд»Јзҡ„жүҖжңүеҹәеӣ
nextGen=[]
#е°ҶжңҖдјҳз§Җзҡ„еҹәеӣ зӣҙжҺҘдј йҖ’з»ҷдёӢдёҖд»Ј
nextGen.append(self.group.getBest().gene[:])
while(len(nextGen)<self.group.GroupSize):
pChange=random.random()
pCross=random.random()
p1=self.group.getOne()
if(pCross<self.pCross):
p2=self.group.getOne()
newGene=self.cross(p1,p2)
else:
newGene=p1.gene[:]
if(pChange<self.pChange):
newGene=self.change(newGene)
nextGen.append(newGene)
self.group.group=[]
for gene in nextGen:
self.group.group.append(Person(gene))
self.group.upDate()
#жү“еҚ°еҪ“еүҚз§ҚзҫӨзҡ„жңҖдјҳдёӘдҪ“дҝЎжҒҜ
def showBest(self):
print("第{}д»Ј\tеҪ“еүҚжңҖдјҳ{}\tеҪ“еүҚе№іеқҮ{}\t".format(self.Gen,1/self.group.getBest().fit,self.group.getAvg()))
#nд»ЈиЎЁд»Јж•°пјҢйҒ—дј з®—жі•зҡ„е…ҘеҸЈ
def run(self,n):
Gen=[] #д»Јж•°
dist=[] #жҜҸдёҖд»Јзҡ„жңҖдјҳи·қзҰ»
avgDist=[] #жҜҸдёҖд»Јзҡ„е№іеқҮи·қзҰ»
#дёҠйқўдёүдёӘеҲ—иЎЁжҳҜдёәдәҶз”»еӣҫ
i=1
while(i<n):
self.nextGen()
self.showBest()
i+=1
Gen.append(i)
dist.append(1/self.group.getBest().fit)
avgDist.append(self.group.getAvg())
#з»ҳеҲ¶иҝӣеҢ–жӣІзәҝ
plt.plot(Gen,dist,'-r')
plt.plot(Gen,avgDist,'-b')
plt.show()
ga=GA()
ga.run(3000)
print("иҝӣиЎҢ3000д»ЈеҗҺжңҖдјҳи§Јпјҡ",1/ga.group.getBest().fit)1.3 е®һйӘҢз»“жһң
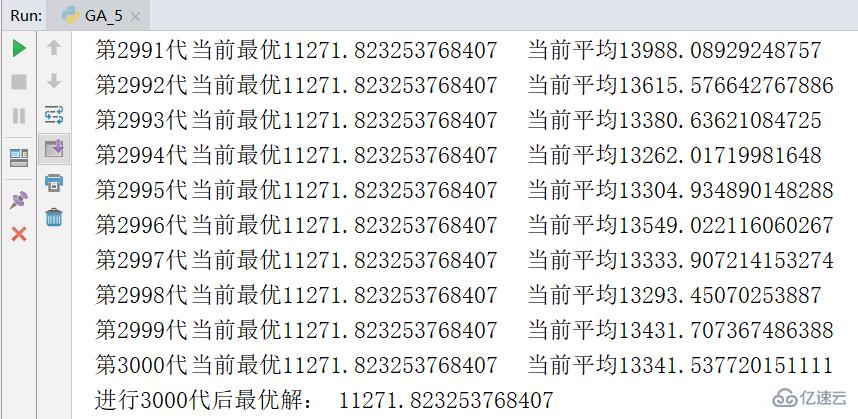
дёӢеӣҫжҳҜиҝӣиЎҢдёҖж¬Ўе®һйӘҢзҡ„з»“жһңжҲӘеӣҫпјҢжұӮеҮәзҡ„жңҖдјҳи§ЈжҳҜ 11271
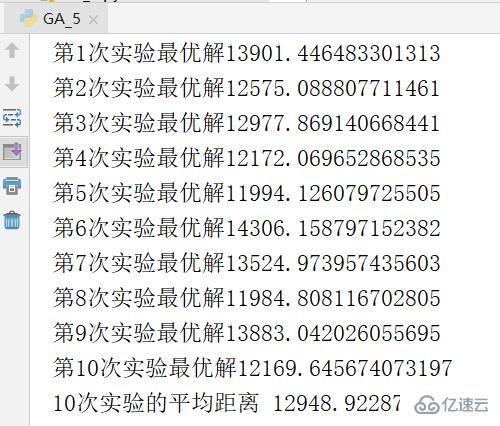
дёәйҒҝе…Қе®һйӘҢзҡ„еҒ¶з„¶жҖ§пјҢиҝӣиЎҢ 10 ж¬ЎйҮҚеӨҚе®һйӘҢпјҢ并жұӮе№іеқҮеҖјпјҢз»“жһңеҰӮдёӢгҖӮ
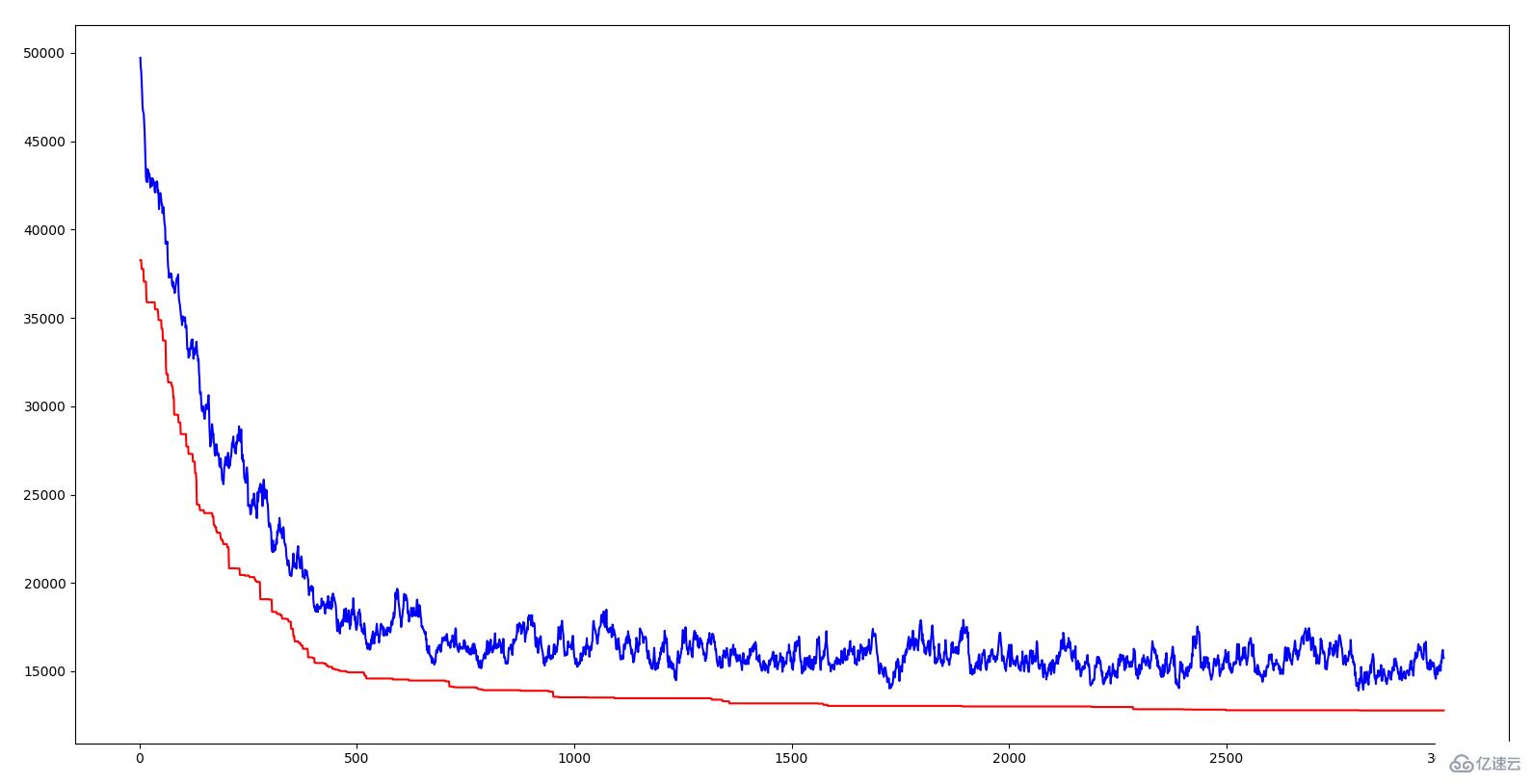
дёҠеӣҫжЁӘеқҗж ҮжҳҜд»Јж•°пјҢзәөеқҗж ҮжҳҜи·қзҰ»пјҢзәўиүІжӣІзәҝжҳҜжҜҸдёҖд»Јзҡ„жңҖдјҳдёӘдҪ“зҡ„и·қзҰ»пјҢи“қиүІжӣІзәҝжҳҜжҜҸдёҖд»Јзҡ„е№іеқҮи·қзҰ»гҖӮеҸҜд»ҘзңӢеҮәдёӨжқЎзәҝйғҪе‘ҲдёӢйҷҚи¶ӢеҠҝпјҢд№ҹе°ұжҳҜиҜҙйғҪеңЁиҝӣеҢ–гҖӮе№іеқҮи·қзҰ»дёӢйҷҚиҜҙжҳҺз”ұдәҺдјҳиүҜеҹәеӣ зҡ„еҮәзҺ°пјҲд№ҹе°ұжҳҜжҹҗдёҖж®өеҹҺеёӮеәҸеҲ—пјүпјҢдҪҝеҫ—иҝҷз§ҚдјҳиүҜзҡ„жҖ§зҠ¶еҫҲеҝ«дј ж’ӯеҲ°ж•ҙдёӘзҫӨдҪ“гҖӮе°ұеғҸиҮӘ然з•Ңдёӯзҡ„дјҳиғңеҠЈжұ°дёҖж ·пјҢе…·жңүйҖӮеә”зҺҜеўғзҡ„еҹәеӣ жүҚиғҪз”ҹеӯҳдёӢжқҘпјҢзӣёеә”зҡ„пјҢз”ҹеӯҳдёӢжқҘзҡ„йғҪжҳҜе…·жңүдјҳиүҜеҹәеӣ зҡ„гҖӮз®—жі•дёӯеј•е…ҘдәӨеҸүзҺҮе’ҢеҸҳејӮзҺҮзҡ„ж„Ҹд№үе°ұеңЁдәҺж—ўиҰҒдҝқиҜҒеҪ“еүҚдјҳиүҜеҹәеӣ пјҢеҸҲиҰҒиҜ•еӣҫдә§з”ҹжӣҙдјҳиүҜзҡ„еҹәеӣ гҖӮеҰӮжһңжүҖжңүдёӘдҪ“йғҪдәӨеҸүпјҢйӮЈд№ҲжңүдәӣдјҳиүҜзҡ„еҹәеӣ зүҮж®өеҸҜиғҪдјҡдёўеӨұпјӣеҰӮжһңйғҪдёҚдәӨеҸүпјҢйӮЈд№ҲдёӨдёӘдјҳз§Җзҡ„еҹәеӣ зүҮж®өж— жі•з»„еҗҲдёәжӣҙдјҳз§Җзҡ„еҹәеӣ пјӣеҰӮжһңжІЎжңүеҸҳејӮпјҢйӮЈе°ұж— жі•дә§з”ҹжӣҙйҖӮеә”зҺҜеўғзҡ„дёӘдҪ“гҖӮдёҚеҫ—дёҚж„ҹеҸ№иҮӘ然зҡ„жҷәж…§жҳҜеҰӮжӯӨејәеӨ§гҖӮ
дёҠйқўиҜҙеҲ°зҡ„еҹәеӣ зүҮж®өе°ұжҳҜ TSP дёӯзҡ„дёҖе°Ҹж®өеҹҺеёӮеәҸеҲ—пјҢеҪ“жҹҗдёҖж®өеәҸеҲ—зҡ„и·қзҰ»е’ҢзӣёеҜ№иҫғе°Ҹж—¶пјҢе°ұиҜҙжҳҺиҝҷж®өеәҸеҲ—жҳҜиҝҷеҮ дёӘеҹҺеёӮзҡ„зӣёеҜ№иҫғеҘҪзҡ„йҒҚеҺҶйЎәеәҸгҖӮйҒ—дј з®—жі•йҖҡиҝҮе°Ҷиҝҷдәӣдјҳз§Җзҡ„зүҮж®өз»„еҗҲиө·жқҘе®һзҺ°дәҶ TSP и§Јзҡ„дёҚж–ӯдјҳеҢ–гҖӮиҖҢз»„еҗҲзҡ„ж–№жі•жӯЈжҳҜеҖҹйүҙиҮӘ然зҡ„жҷәж…§пјҢйҒ—дј гҖҒеҸҳејӮгҖҒйҖӮиҖ…з”ҹеӯҳгҖӮ
1.4 е®һйӘҢжҖ»з»“
1гҖҒеҰӮдҪ•еңЁз®—жі•дёӯе®һзҺ°вҖңдјҳиғңеҠЈжұ°вҖқпјҹ
жүҖи°“дјҳиғңеҠЈжұ°д№ҹе°ұжҳҜдјҳиүҜзҡ„еҹәеӣ дҝқз•ҷпјҢдёҚйҖӮеә”зҺҜеўғзҡ„еҹәеӣ ж·ҳжұ°гҖӮеңЁдёҠиҝ° GA з®—жі•дёӯпјҢжҲ‘дҪҝз”Ёзҡ„жҳҜиҪ®зӣҳиөҢпјҢд№ҹе°ұжҳҜеңЁйҒ—дј зҡ„жӯҘйӘӨдёӯпјҲж— и®әжҳҜеҗҰдәӨеҸүпјүпјҢж №жҚ®жҜҸдёӘдёӘдҪ“зҡ„йҖӮеә”еәҰжқҘжҢ‘йҖүгҖӮиҝҷж ·е°ұиғҪиҫҫеҲ°йҖӮеә”еәҰй«ҳеҫ—дёӘдҪ“жңүжӣҙеӨҡзҡ„еҗҺд»ЈпјҢд№ҹе°ұиҫҫеҲ°дәҶдјҳиғңеҠЈжұ°зҡ„зӣ®зҡ„гҖӮ
еңЁе…·дҪ“зҡ„е®һзҺ°иҝҮзЁӢдёӯпјҢжҲ‘зҠҜдәҶдёӘй”ҷиҜҜпјҢиө·еҲқеңЁйҒ—дј жӯҘйӘӨзӯӣйҖүдёӘдҪ“ж—¶пјҢжҲ‘жҜҸйҖүеҮәдёҖдёӘдёӘдҪ“е°ұе°ҶиҝҷдёӘдёӘдҪ“д»ҺзҫӨдҪ“дёӯеҲ йҷӨгҖӮзҺ°еңЁжғіжғіпјҢиҝҷз§ҚеҒҡжі•еҚҒеҲҶж„ҡи ўпјҢе°Ҫз®ЎеҪ“ж—¶жҲ‘е·Із»Ҹе®һзҺ°дәҶиҪ®зӣҳиөҢпјҢдҪҶеҰӮжһңйҖүеҮәдёӘдҪ“е°ұеҲ йҷӨпјҢйӮЈд№Ҳе°ұдјҡеҜјиҮҙжҜҸдёӘдёӘдҪ“йғҪдјҡе№ізӯүең°з”ҹиӮІеҗҺд»ЈпјҢжүҖи°“зҡ„иҪ®зӣҳиөҢд№ҹдёҚиҝҮжҳҜиғҪи®©йҖӮеә”еәҰй«ҳзҡ„е…ҲиҝӣиЎҢйҒ—дј гҖӮиҝҷз§ҚеҒҡжі•е®Ңе…ЁиғҢзҰ»дәҶвҖңдјҳиғңеҠЈжұ°вҖқзҡ„еҲқиЎ·гҖӮжӯЈзЎ®зҡ„еҒҡжі•жҳҜйҖүе®ҢдёӘдҪ“иҝӣиЎҢйҒ—дј еҗҺеҶҚйҮҚж–°ж”ҫеӣһзҫӨдҪ“пјҢиҝҷж ·жүҚиғҪдҝқиҜҒйҖӮеә”еәҰй«ҳзҡ„дёӘдҪ“дјҡиҝӣиЎҢеӨҡж¬ЎйҒ—дј пјҢдә§з”ҹжӣҙеӨҡеҗҺд»ЈпјҢе°ҶдјҳиүҜзҡ„еҹәеӣ жӣҙе№ҝжіӣзҡ„ж’ӯж’’пјҢеҗҢж—¶дёҚйҖӮеә”зҡ„дёӘдҪ“дјҡдә§з”ҹе°‘йҮҸеҗҺд»ЈжҲ–иҖ…зӣҙжҺҘиў«ж·ҳжұ°гҖӮ
2 гҖҒеҰӮдҪ•дҝқиҜҒиҝӣеҢ–дёҖзӣҙжҳҜеңЁжӯЈеҗ‘иҝӣиЎҢпјҹ
жүҖи°“жӯЈеҗ‘иҝӣиЎҢд№ҹе°ұжҳҜдёӢдёҖд»Јзҡ„жңҖдјҳдёӘдҪ“дёҖе®ҡжҜ”дёҠдёҖд»ЈжӣҙйҖӮеә”жҲ–иҖ…еҗҢзӯүйҖӮеә”зҺҜеўғгҖӮжҲ‘йҮҮз”Ёзҡ„ж–№жі•жҳҜжңҖдјҳдёӘдҪ“зӣҙжҺҘиҝӣе…ҘдёӢдёҖд»ЈпјҢдёҚеҸӮдёҺдәӨеҸүеҸҳејӮзӯүж“ҚдҪңгҖӮиҝҷж ·иғҪеӨҹйҳІжӯўеӣ иҝҷдәӣж“ҚдҪңиҖҢвҖңжұЎжҹ“вҖқдәҶеҪ“еүҚжңҖдјҳз§Җзҡ„еҹәеӣ иҖҢеҜјиҮҙеҸҚеҗ‘иҝӣеҢ–зҡ„еҮәзҺ°гҖӮ
жҲ‘еңЁе®һзҺ°иҝҮзЁӢдёӯиҝҳеҮәзҺ°дәҶеҸҰдёҖзӮ№й—®йўҳпјҢжҳҜдј еј•з”ЁиҝҳжҳҜдј еҖјжүҖеҜјиҮҙзҡ„гҖӮеҜ№дёӘдҪ“зҡ„еҹәеӣ иҝӣиЎҢдәӨеҸүе’ҢеҸҳејӮж—¶з”Ёзҡ„жҳҜдёҖдёӘеҲ—иЎЁпјҢPython дёӯдј еҲ—иЎЁж—¶дј зҡ„е®һйҷ…дёҠжҳҜдёҖдёӘеј•з”ЁпјҢиҝҷж ·е°ұеҜјиҮҙдёӘдҪ“иҝӣиЎҢдәӨеҸүе’ҢеҸҳејӮеҗҺдјҡж”№еҸҳдёӘдҪ“жң¬иә«зҡ„еҹәеӣ гҖӮеҜјиҮҙзҡ„з»“жһңе°ұжҳҜиҝӣеҢ–йқһеёёзј“ж…ўпјҢ并且дјҙйҡҸеҸҚеҗ‘иҝӣеҢ–гҖӮ
3гҖҒдәӨеҸүеҰӮдҪ•е®һзҺ°пјҹ
йҖүе®ҡдёҖдёӘдёӘдҪ“зҡ„зүҮж®өж”ҫе…ҘеҸҰдёҖдёӘдҪ“пјҢ并е°ҶдёҚйҮҚеӨҚзҡ„еҹәеӣ зҡ„дҫқж¬Ўж”ҫе…Ҙе…¶д»–дҪҚзҪ®гҖӮ
еңЁе®һзҺ°иҝҷдёҖжӯҘж—¶пјҢеӣ дёәеӯҰз”ҹзү©ж—¶еҜ№зңҹе®һжҹ“иүІдҪ“иЎҢдёәзҡ„еӣәжңүи®ӨиҜҶпјҢвҖңеҗҢжәҗжҹ“иүІдҪ“дәӨеҸүдә’жҚўеҗҢжәҗеҢәж®өвҖқпјҢеҜјиҮҙжҲ‘й”ҷиҜҜе®һзҺ°иҜҘеҠҹиғҪгҖӮжҲ‘еҸӘе°ҶдёӨдёӘдёӘдҪ“зҡ„зӣёеҗҢдҪҚзҪ®зҡ„зүҮж®өдә’жҚўжқҘе®ҢжҲҗдәӨеҸүпјҢжҳҫ然иҝҷж ·зҡ„еҒҡжі•жҳҜй”ҷиҜҜзҡ„пјҢиҝҷдјҡеҜјиҮҙеҹҺеёӮзҡ„йҮҚеӨҚеҮәзҺ°гҖӮ
4гҖҒеңЁеҲҡејҖе§ӢеҶҷиҝҷдёӘз®—жі•ж—¶пјҢжҲ‘жҳҜеҚҠ OOPпјҢеҚҠйқўеҗ‘иҝҮзЁӢең°еҶҷгҖӮ
еҗҺз»ӯжөӢиҜ•иҝҮзЁӢдёӯеҸ‘зҺ°иҰҒж”№еҸӮж•°пјҢжӣҙж–°дёӘдҪ“дҝЎжҒҜж—¶еҫҲйә»зғҰпјҢдәҺжҳҜе…ЁйғЁж”№дёә OOPпјҢ然еҗҺж–№дҫҝеӨҡдәҶгҖӮеҜ№дәҺиҝҷз§ҚжЁЎжӢҹзңҹе®һдё–з•Ңзҡ„й—®йўҳпјҢOOP жңүеҫҲеӨ§зҡ„зҒөжҙ»жҖ§е’Ңз®ҖдҫҝжҖ§гҖӮ
5гҖҒеҰӮдҪ•йҳІжӯўеҮәзҺ°еұҖйғЁжңҖдјҳи§Јпјҹ
еңЁжөӢиҜ•иҝҮзЁӢдёӯеҸ‘зҺ°еҒ¶е°”дјҡеҮәзҺ°еұҖйғЁжңҖдјҳи§ЈпјҢеңЁеҫҲй•ҝж—¶й—ҙеҶ…дёҚдјҡ继з»ӯиҝӣеҢ–пјҢиҖҢжӯӨж—¶зҡ„и§ЈеҸҲзҰ»жңҖдјҳи§ЈиҫғиҝңгҖӮе“ӘжҖ•жҳҜеҗҺз»ӯи°ғж•ҙеҗҺпјҢе°Ҫз®ЎзҰ»жңҖдјҳи§Јиҝ‘дәҶпјҢдҪҶдҫқ然жҳҜвҖңеұҖйғЁжңҖдјҳвҖқпјҢеӣ дёәиҝҳжІЎжңүиҫҫеҲ°жңҖдјҳгҖӮ
з®—жі•еңЁиө·еҲқдјҡ收ж•ӣеҫ—еҫҲеҝ«пјҢиҖҢи¶ҠеҫҖеҗҺе°ұдјҡи¶ҠжқҘи¶Ҡж…ўпјҢз”ҡиҮіж №жң¬дёҚеҠЁгҖӮеӣ дёәеҲ°еҗҺжңҹпјҢжүҖжңүдёӘдҪ“йғҪжңүзқҖзӣёеҜ№жқҘиҜҙе·®дёҚеӨҡзҡ„дјҳз§Җеҹәеӣ пјҢиҝҷж—¶зҡ„дәӨеҸүеҜ№дәҺиҝӣеҢ–зҡ„дҪңз”Ёе°ұеҫҲејұдәҶпјҢиҝӣеҢ–зҡ„дё»иҰҒеҠЁеҠӣе°ұжҲҗдәҶеҸҳејӮпјҢиҖҢеҸҳејӮе°ұжҳҜдёҖз§ҚжҡҙеҠӣз®—жі•дәҶгҖӮиҝҗж°”еҘҪзҡ„иҜқиғҪеҫҲеҝ«еҸҳејӮеҮәжӣҙеҘҪзҡ„дёӘдҪ“пјҢиҝҗж°”дёҚеҘҪе°ұеҫ—дёҖзӣҙзӯүгҖӮ
йҳІжӯўеұҖйғЁжңҖдјҳи§Јзҡ„и§ЈеҶіж–№жі•жҳҜеўһеӨ§з§ҚзҫӨ规模пјҢиҝҷж ·е°ұдјҡжңүжӣҙеӨҡзҡ„дёӘдҪ“еҸҳејӮпјҢе°ұдјҡжңүжӣҙеӨ§еҸҜиғҪжҖ§дә§з”ҹиҝӣеҢ–зҡ„дёӘдҪ“гҖӮиҖҢеўһеӨ§з§ҚзҫӨ规模зҡ„ејҠз«ҜжҳҜжҜҸдёҖд»Јзҡ„и®Ўз®—ж—¶й—ҙдјҡеҸҳй•ҝпјҢд№ҹе°ұжҳҜиҜҙиҝҷдёӨиҖ…жҳҜзӣёдә’жҠ‘еҲ¶зҡ„гҖӮе·ЁеӨ§зҡ„з§ҚзҫӨ规模иҷҪ然жңҖз»ҲиғҪйҒҝе…ҚеұҖйғЁжңҖдјҳи§ЈпјҢдҪҶжҳҜжҜҸдёҖд»Јзҡ„ж—¶й—ҙеҫҲй•ҝпјҢйңҖиҰҒеҫҲй•ҝж—¶й—ҙжүҚиғҪжұӮеҮәжңҖдјҳи§ЈпјӣиҖҢиҫғе°Ҹзҡ„з§ҚзҫӨ规模иҷҪ然жҜҸдёҖд»Ји®Ўз®—ж—¶й—ҙеҝ«пјҢдҪҶеңЁиӢҘе№Ід»ЈеҗҺе°ұдјҡйҷ·е…ҘеұҖйғЁжңҖдјҳгҖӮ
зҢңжғідёҖз§ҚеҸҜиғҪзҡ„дјҳеҢ–ж–№жі•пјҢеңЁиҝӣеҢ–еҲқжңҹз”Ёиҫғе°Ҹзҡ„з§ҚзҫӨ规模пјҢд»ҘжӯӨжқҘеҠ еҝ«иҝӣеҢ–йҖҹеәҰпјҢеҪ“йҖӮеә”еәҰиҫҫеҲ°жҹҗдёҖйҳҲеҖјеҗҺпјҢеўһеҠ з§ҚзҫӨ规模е’ҢеҸҳејӮзҺҮжқҘйҒҝе…ҚеұҖйғЁжңҖдјҳи§Јзҡ„еҮәзҺ°гҖӮз”Ёиҝҷз§ҚеҠЁжҖҒи°ғж•ҙзҡ„ж–№жі•жқҘжқғиЎЎжҜҸдёҖд»Ји®Ўз®—ж•ҲзҺҮе’Ңж•ҙдҪ“и®Ўз®—ж•ҲзҺҮд№Ӣй—ҙзҡ„е№іиЎЎгҖӮ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңжҖҺд№ҲдҪҝз”ЁPythonе®һзҺ°йҒ—дј з®—жі•вҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





