这篇文章主要介绍了Python的正则表达式怎么实现的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Python的正则表达式怎么实现文章都会有所收获,下面我们一起来看看吧。
正则表达式本身是独立于编程语言的知识,但是它又依附于编程语言,基本上我们所使用的编程语言都提供了对它的实现,当然了,各家的实现也是有一些差异的,有的支持的功能多一点,有的支持的少一点。
因为正则表达式是实践中使用广泛的工具,所以脱离语言的学习我认为是不靠谱的。
正则表达式主要API关系图
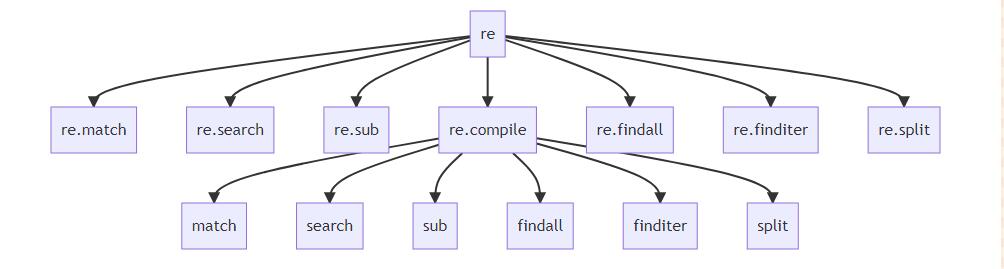
这个图是我个人总结的,我觉得基本上把这里的函数的关系弄清楚了,它们的作用是:
match 从文本的开头匹配正则表达式,返回匹配的对象,没有就返回 None
search 在整个文本中匹配正则表达式,返回第一个匹配的对象,没有就返回 None。
sub 利用正则表达式进行文本替换(正则表达式的功能:搜索和替换)
findall 从整个文本中匹配正则表达式,以列表的形式返回所有匹配的结果。
finditer 从整个文本中匹配正则表达式,以迭代器的形式返回所有匹配的结果。
split 利用正则表达式切分文本
这里可以看出,·re· 下面有很多立即可以使用的函数,然后 re.compile 下面有很多同名的函数。直接在 ·re· 模块下的是官方提供方便使用的函数,通过 re.compile 来使用是最正统的方式。所以,接下来的内容,我基本上智慧使用 re.compile 及其下的方法来实现。
compile 函数用于编译正则表达式,生成一个正则表达式 (Pattern)对象,供 match() 和 search() 以及其它函数使用。
语法:
re.compile(pattern[, flags])pattern: 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 多行模式
re.S 即为 '.' 并且包括换行符在内的任意字符('.' 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 ‘#’ 后面的注释
示例:查找字符串中的所有数字
import re
s = 'runoob 123 google 456'
result1 = re.findall(r'\d+', s)
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall(s)
result3 = pattern.findall(s, 0, 20)
print(result1)
print(result2)
print(result3)
"""
output:
[‘123', ‘456']
[‘123', ‘456']
[‘123', ‘45']
"""接下来我们要逐渐学习正则表达的内容,这些内容是非常有趣的!Interesting and Excited!
这里给出一个接下来会一直使用的示例模板,这个模板是这篇博客最重要的东西了,之后的内容都会基于它进行扩展。所以,请好好理解它。
import re
# 需要进行搜索或者匹配的文本
text = """I love you yesterday and today."""
# 正则表达式
regexp = r'love'
# 编译(对正则表达式进行编译获取 Pattern Object)
pattern = re.compile(regexp)
# 搜索
m = pattern.search(text)
if m:
print("匹配对象: ", m)
print("匹配的字符串: ", m.group())
print("匹配的开始位置: ", m.start())
print("匹配的结束位置: ", m.end())
print("匹配位置的元组: ", m.span())
else:
print("No match!")
# 替换
new_text = pattern.sub("hate", text)
print(new_text)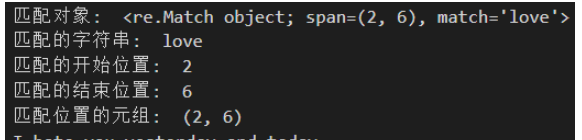
注意: 正则表达式 regexp 在开始前会使用 r 前缀,这样做的目的是为了避免在正则表达式中大量使用转义字符,破坏了整体的可读性。
Python 的正则表达式包含了很多非常易用的方法,但是这里我并不会过多介绍它们。我们会一直使用上面这种模式,因为那些易用的方法只是对它的一种封装,学习使用这种基本的方式自然就会其它的了。
匹配对象 可以获取有关正则表达式的信息,它最重要的方法和属性是:
| 方法/属性 | 目的 |
| group() | 返回正则匹配的字符串 |
| start() | 返回匹配的开始位置 |
| end() | 返回匹配的结束位置 |
| span() | 返回包含匹配 (start, end) 位置的元组 |
关于“Python的正则表达式怎么实现”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Python的正则表达式怎么实现”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://blog.csdn.net/qq_40734247/article/details/125922571



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



