这篇文章主要介绍“Python中如何使用Jieba进行词频统计与关键词提取”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Python中如何使用Jieba进行词频统计与关键词提取”文章能帮助大家解决问题。
1.导入jieba库并定义文本
import jieba
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"2.对文本进行分词
words = jieba.cut(text)这一步会将文本分成若干个词语,并返回一个生成器对象words,可以使用for循环遍历所有的词语。
3. 统计词频
word_count = {}
for word in words:
if len(word) > 1:
word_count[word] = word_count.get(word, 0) + 1这一步通过遍历所有的词语,统计每个词语出现的次数,并保存到一个字典word_count中。在统计词频时,可以通过去除停用词等方式进行优化,这里只是简单地过滤了长度小于2的词语。
4. 结果输出
for word, count in word_count.items():
print(word, count)
为了更准确地统计词频,我们可以在词频统计中加入停用词,以去除一些常见但无实际意义的词语。具体步骤如下:
定义停用词列表
import jieba
# 停用词列表
stopwords = ['是', '一种', '等']对文本进行分词,并过滤停用词
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
words = jieba.cut(text)
words_filtered = [word for word in words if word not in stopwords and len(word) > 1]统计词频并输出结果
word_count = {}
for word in words_filtered:
word_count[word] = word_count.get(word, 0) + 1
for word, count in word_count.items():
print(word, count)加入停用词后,输出的结果是:

可以看到,被停用的一种这个词并没有显示出来。
与对词语进行单纯计数的词频统计不同,jieba提取关键字的原理是基于TF-IDF(Term Frequency-Inverse Document Frequency)算法。TF-IDF算法是一种常用的文本特征提取方法,可以衡量一个词语在文本中的重要程度。
具体来说,TF-IDF算法包含两个部分:
Term Frequency(词频):指一个词在文本中出现的次数,通常用一个简单的统计值表示,例如词频、二元词频等。词频反映了一个词在文本中的重要程度,但是忽略了这个词在整个语料库中的普遍程度。
Inverse Document Frequency(逆文档频率):指一个词在所有文档中出现的频率的倒数,用于衡量一个词的普遍程度。逆文档频率越大,表示一个词越普遍,重要程度越低;逆文档频率越小,表示一个词越独特,重要程度越高。
TF-IDF算法通过综合考虑词频和逆文档频率,计算出每个词在文本中的重要程度,从而提取关键字。在jieba中,关键字提取的具体实现包括以下步骤:
对文本进行分词,得到分词结果。
统计每个词在文本中出现的次数,计算出词频。
统计每个词在所有文档中出现的次数,计算出逆文档频率。
综合考虑词频和逆文档频率,计算出每个词在文本中的TF-IDF值。
对TF-IDF值进行排序,选取得分最高的若干个词作为关键字。
举个例子:
F(Term Frequency)指的是某个单词在一篇文档中出现的频率。计算公式如下:
T F = ( 单词在文档中出现的次数 ) / ( 文档中的总单词数 )
例如,在一篇包含100个单词的文档中,某个单词出现了10次,则该单词的TF为
10 / 100 = 0.1
IDF(Inverse Document Frequency)指的是在文档集合中出现某个单词的文档数的倒数。计算公式如下:
I D F = l o g ( 文档集合中的文档总数 / 包含该单词的文档数 )
例如,在一个包含1000篇文档的文档集合中,某个单词在100篇文档中出现过,则该单词的IDF为 l o g ( 1000 / 100 ) = 1.0
TFIDF是将TF和IDF相乘得到的结果,计算公式如下:
T F I D F = T F ∗ I D F
需要注意的是,TF-IDF算法只考虑了词语在文本中的出现情况,而忽略了词语之间的关联性。因此,在一些特定的应用场景中,需要使用其他的文本特征提取方法,例如词向量、主题模型等。
import jieba.analyse
# 待提取关键字的文本
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
# 使用jieba提取关键字
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
# 输出关键字和对应的权重
for keyword, weight in keywords:
print(keyword, weight)在这个示例中,我们首先导入了jieba.analyse模块,然后定义了一个待提取关键字的文本text。接着,我们使用jieba.analyse.extract_tags()函数提取关键字,其中topK参数表示需要提取的关键字个数,withWeight参数表示是否返回关键字的权重值。最后,我们遍历关键字列表,输出每个关键字和对应的权重值。
这段函数的输出结果为:
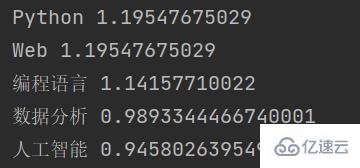
可以看到,jieba根据TF-IDF算法提取出了输入文本中的若干个关键字,并返回了每个关键字的权重值。
关于“Python中如何使用Jieba进行词频统计与关键词提取”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



