жҖҺд№ҲдҪҝз”ЁPythonж“ҚдҪңж–Үжң¬ж•°жҚ®
иҝҷзҜҮвҖңжҖҺд№ҲдҪҝз”ЁPythonж“ҚдҪңж–Үжң¬ж•°жҚ®вҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңжҖҺд№ҲдҪҝз”ЁPythonж“ҚдҪңж–Үжң¬ж•°жҚ®вҖқж–Үз« еҗ§гҖӮ
е®һйӘҢзӣ®зҡ„
зҶҹжӮүpythonзҡ„еҹәжң¬ж•°жҚ®з»“жһ„пјҢд»ҘеҸҠж–Ү件зҡ„иҫ“е…ҘдёҺиҫ“еҮәгҖӮ
е®һйӘҢж•°жҚ®
еҲ©з”Ёxxxxе№ҙxxжңәеҷЁеӯҰд№ дјҡи®®зҡ„иҜ„жөӢж•°жҚ®е’ҢиҜ„жөӢд»»еҠЎпјҢж•°жҚ®еҢ…жӢ¬и®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶпјҢиҜ„жөӢд»»еҠЎдёәйҖҡиҝҮз»ҷе®ҡзҡ„и®ӯз»ғж•°жҚ®пјҢйў„жөӢжөӢиҜ•йӣҶдёӯзҡ„е…ізі»жҳҜжӯЈдҫӢиҝҳжҳҜиҙҹдҫӢпјҢеңЁжҜҸдёӘж ·жң¬жңҖеҗҺз»ҷеҮә1жҲ–иҖ…0гҖӮ
ж•°жҚ®жҸҸиҝ°еҰӮдёӢпјҢ第дёҖеҲ—дёәе…ізі»зұ»еһӢпјҢ第дәҢеҲ—е’Ң第дёүеҲ—дёәдәәеҗҚпјҢ第еӣӣеҲ—жҳҜж ҮйўҳпјҢ第дә”еҲ—жҳҜе…ізі»дёәжӯЈдҫӢиҝҳжҳҜиҙҹдҫӢпјҢ1дёәжӯЈдҫӢпјҢ0дёәиҙҹдҫӢпјӣ第е…ӯеҲ—иЎЁзӨәи®ӯз»ғйӣҶгҖӮ
| дәӢ件 | дәәзү©1 | дәәзү©2 | ж Үйўҳ | е…ізі»пјҲ0 or 1) | и®ӯз»ғйӣҶ |
|---|
жөӢиҜ•йӣҶжҸҸиҝ°еҰӮдёӢеӣҫпјҢж јејҸеҹәжң¬дёҺи®ӯз»ғйӣҶзұ»дјјпјҢе”ҜдёҖдёҚеҗҢзҡ„жҳҜ第дә”еҲ—жІЎжңүе…ізі»жҳҜжӯЈдҫӢиҝҳжҳҜиҙҹдҫӢзҡ„ж Үи®°гҖӮ
| е…ізі» | дәәзү©1 | дәәзү©2 | дәӢ件 |
|---|
е®һйӘҢеҶ…е®№
еҜ№и®ӯз»ғйӣҶж•°жҚ®иҝӣиЎҢеӨ„зҗҶпјҢеҸӘз•ҷдёӢеүҚйқўдә”еҲ—пјҢиҫ“еҮәж–Үжң¬е‘ҪеҗҚдёәexp1_1.txtгҖӮ
еңЁз¬¬дёҖжӯҘеҫ—еҲ°зҡ„ж•°жҚ®зҡ„еҹәзЎҖдёҠеҜ№19зұ»е…ізі»иҝӣиЎҢеҲҶзұ»пјҢз”ҹжҲҗзҡ„ж–Үжң¬еӯҳж”ҫеңЁexp1_trainж–Ү件еӨ№дёӢпјҢжҢүз…§е…ізі»зұ»еҲ«еҮәзҺ°зҡ„йЎәеәҸпјҢ第дёҖдёӘе…ізі»зұ»еҲ«зҡ„ж•°жҚ®еӯҳж”ҫеңЁ1.txtдёӯпјҢ第дәҢдёӘе…ізі»зұ»еҲ«еӯҳж”ҫеңЁ2.txtдёӯпјҢзӣҙеҲ°19.txtгҖӮ
жөӢиҜ•йӣҶжҢүз…§и®ӯз»ғйӣҶзҡ„19дёӘзұ»еҲ«зҡ„йЎәеәҸе°Ҷеҗ„дёӘж ·жң¬жҢүз…§е…ізі»зұ»еҲ«еҪ’зұ»пјҢеҚізӣёеҗҢе…ізі»зұ»еһӢзҡ„ж•°жҚ®ж”ҫеҲ°дёҖдёӘж–Үжң¬ж–Ү件дёӯпјҢеҗҢж ·з”ҹжҲҗ19дёӘзұ»еҲ«зҡ„жөӢиҜ•ж–Ү件пјҢж јејҸд»Қж—§е’ҢжөӢиҜ•ж–Ү件дҝқжҢҒдёҖиҮҙгҖӮеӯҳж”ҫеңЁexp1_testж–Ү件еӨ№дёӢпјҢжҜҸдёӘзұ»еҲ«зҡ„ж–Ү件д»Қж—§е‘ҪеҗҚдёә1_test.txtпјҢ2_test.txt…еҗҢж—¶еҜ№жҜҸдёӘж ·жң¬еңЁеҺҹжөӢиҜ•йӣҶдёӯеҮәзҺ°зҡ„дҪҚзҪ®иҝӣиЎҢи®°еҪ•пјҢе’Ң19дёӘжөӢиҜ•ж–Ү件дёҖдёҖеҜ№еә”иө·жқҘгҖӮжҜ”еҰӮ第дёҖзұ»вҖңдј й—»дёҚе’ҢвҖқзҡ„жҜҸдёӘж ·жң¬еңЁеҺҹж–ҮдёӯеӨ„дәҺ第еҮ иЎҢпјҢеңЁзҙўеј•ж–Ү件дёӯиҝӣиЎҢи®°еҪ•пјҢдҝқеӯҳеңЁж–Ү件index1.txtпјҢindex2.txt….
и§ЈйўҳжҖқи·Ҝ
1.第дёҖйўҳжҳҜиҖғеҜҹжҲ‘们ж–Ү件ж“ҚдҪңдёҺеҲ—иЎЁзҡ„зҹҘиҜҶпјҢдё»иҰҒиҖғеҜҹзҡ„йҡҫзӮ№жҳҜеҜ№newж–Ү件зҡ„иҜ»еҸ–пјҢж №жҚ®иҰҒжұӮеӨ„зҗҶеҗҺеңЁз”ҹжҲҗдёҖдёӘtxtж–Ү件пјҢи®©жҲ‘们зңӢдёҖдёӢе…·дҪ“зҡ„д»Јз Ғе®һзҺ°пјҡ
import os
# еҲӣе»әдёҖдёӘеҲ—иЎЁз”ЁжқҘеӯҳеӮЁж–°зҡ„еҶ…е®№
list = []
with open("task1.trainSentence.new", "r",encoding='xxx') as file_input: # жү“ејҖ.newж–Ү件,xxxж №жҚ®иҮӘе·ұзҡ„зј–з Ғж јејҸеЎ«еҶҷ
with open("exp1_1.txt", "w", encoding='xxx') as file_output: # жү“ејҖexp1_1.txt,xxxж №жҚ®иҮӘе·ұзҡ„зј–з Ғж јејҸеЎ«еҶҷж–Ү件еҰӮжһңжІЎжңүе°ұеҲӣе»әдёҖдёӘ
for Line in file_input: # йҒҚеҺҶжҜҸдёҖиЎҢзҡ„ж–Ү件
arr = Line.split('\t') # д»Ҙ\tдёәеҲҶйҡ”з¬ҰиҜ»еҸ–
if arr[0] not in list: # if the word is not in the list
list.append(arr[0]) # add the word to the list
file_output.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"\t"+arr[4]+"\n") # write the line to the file
file_input.close() #е…ій—ӯ.newж–Ү件
file_output.close() #е…ій—ӯеҲӣе»әзҡ„txtж–Ү件2.第дәҢйўҳдҫқж—§иҖғеҜҹдәҶж–Ү件ж“ҚдҪңпјҢеңЁйўҳзӣ®дёҖз”ҹжҲҗзҡ„ж–Ү件еҹәзЎҖдёҠпјҢжҢүз…§еҗҢдёҖзұ»еһӢзҡ„дәӢ件еҜ№дәӢ件иҝӣиЎҢеҲҶзұ»пјҢжҳҜеҗҰиғҪй«ҳж•Ҳзҡ„еҲҶз»„йңҖиҰҒеҲ©з”ЁеҫӘзҺҜжқЎд»¶жқҘи§ЈеҶіпјҢжҲ‘们жқҘзңӢзңӢе…·дҪ“зҡ„
д»Јз Ғе®һзҺ°
import os
file_1 = open("exp1_1.txt", encoding='xxx') # жү“ејҖж–Ү件,xxxж №жҚ®иҮӘе·ұзҡ„зј–з Ғж јејҸеЎ«еҶҷ
os.mkdir("exp1_train") # еҲӣе»әзӣ®еҪ•
os.chdir("exp1_train") # дҝ®ж”№иҝӣзЁӢзҡ„е·ҘдҪңзӣ®еҪ•пјҲдҪҝз”ЁиҜҘзӣ®еҪ•пјү
a = file.readline() # жҢүиЎҢиҜ»еҸ–exp1_1.txtж–Ү件
arr = a.split("\t") # жҢү\tй—ҙйҡ”з¬ҰдҪңдёәеҲҶеүІ
b = 1 #и®ҫзҪ®еҲҶз»„ж–Ү件зҡ„еәҸеҲ—
file_2 = open("{}.txt".format(b), "w", encoding="xxx") # жү“ејҖж–Ү件,xxxж №жҚ®иҮӘе·ұзҡ„зј–з Ғж јејҸеЎ«еҶҷ
for line in file_1: # жҢүиЎҢиҜ»еҸ–ж–Ү件
arr_1 = line.split("\t") # жҢү\tй—ҙйҡ”з¬ҰдҪңдёәеҲҶеүІ
if arr[0] != arr_1[0]: # еҰӮжһңиҜ»еҸ–ж–Ү件зҡ„第дёҖеҲ—еҶ…е®№дёҺеӯҳе…Ҙж–°ж–Ү件зҡ„第дёҖеҲ—зұ»еһӢдёҚеҗҢ
file_2.close() # е…іжҺүиҜҘж–Ү件
b += 1 # ж–Ү件еәҸеҲ—еҠ дёҖ
f_2 = open("{}.txt".format(b), "w", encoding="xxx") # еҲӣе»әж–°ж–Ү件пјҢд»ҘеҸҰдёҖз§Қзұ»еһӢеҲҶзұ»,xxxж №жҚ®иҮӘе·ұзҡ„зј–з Ғж јејҸеЎ«еҶҷ
arr = line.split("\t") # жҢү\tй—ҙйҡ”з¬ҰдҪңдёәеҲҶеүІ
f_2.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"t"+arr[4]+"\t""\n") # е°ҶзӣёеҗҢзұ»еһӢзҡ„ж–Ү件еҶҷе…Ҙ
f_1.close() # е…ій—ӯйўҳзӣ®дёҖеҲӣе»әзҡ„exp1_1.txtж–Ү件
f_2.close() # е…ій—ӯеҲӣе»әзҡ„жңҖеҗҺдёҖдёӘзұ»еһӢзҡ„ж–Ү件3.е°Ҷи®ӯз»ғйӣҶзҡ„19дёӘзұ»еҲ«жҢүз…§дәәзү©зҡ„е…ізі»иҝӣиЎҢиҝӣдёҖжӯҘзҡ„еҲҶзұ»пјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮеӯ—е…ёеҜ№ж•°жҚ®иҝӣиЎҢйҒҚеҺҶпјҢжҹҘжүҫе…ізі»пјҢжҠҠе…ізі»зӣёеҗҢзҡ„еҶ…е®№ж”ҫеҲ°дёҖдёӘж–Ү件еӨ№дёӯпјҢдёҚеҗҢеҲҷж–°е»әдёҖдёӘгҖӮ
import os
with open("exp1_1.txt", encoding='xxx') as file_in1: # жү“ејҖж–Ү件,xxxж №жҚ®иҮӘе·ұзҡ„зј–з Ғж јејҸеЎ«еҶҷ
i = 1 # зұ»еһӢеәҸеҲ—
arr2 = {} # еҲӣе»әеӯ—е…ё
for line in file_in1: # жҢүиЎҢйҒҚеҺҶ
arr3 = line[0:2] # иҜ»еҸ–е…ізі»
if arr3 not in arr2.keys():
arr2[arr3] = i
i += 1 # зұ»еһӢ+1
file_in = open("task1.test.new") # жү“ејҖж–Ү件task1.test.new
os.mkdir("exp1_test") # еҲӣе»әзӣ®еҪ•
os.chdir("exp1_test") # дҝ®ж”№иҝӣзЁӢзҡ„е·ҘдҪңзӣ®еҪ•пјҲдҪҝз”ЁиҜҘзӣ®еҪ•пјү
for line in file_in:
arr = line[0:2]
with open("{}_test.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
file_out.write(line)
i = 1
file_in.seek(0)
os.mkdir("exp1_index")
os.chdir("exp1_index")
for line in file_in:
arr = line[0:2]
with open("index{}.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
line = line[0:-1]
file_out.write(line + '\t' + "{}".format(i) + "\n")
i += 1з”ЁpythonеӨ„зҗҶж•°еҖјеһӢж•°жҚ®
е®һйӘҢзӣ®зҡ„
зҶҹжӮүpythonзҡ„еҹәжң¬ж•°жҚ®з»“жһ„пјҢд»ҘеҸҠж–Ү件зҡ„иҫ“е…ҘдёҺиҫ“еҮәгҖӮ
е®һйӘҢж•°жҚ®
xxxxе№ҙxxеӨ©жұ еӨ§иөӣпјҢд№ҹжҳҜдёӯеӣҪй«ҳж Ўз¬¬xеұҠеӨ§ж•°жҚ®жҢ‘жҲҳиөӣзҡ„ж•°жҚ®гҖӮж•°жҚ®еҢ…жӢ¬дёӨдёӘиЎЁпјҢеҲҶеҲ«жҳҜз”ЁжҲ·иЎҢдёәиЎЁmars_tianchi_user_actions.csvе’ҢжӯҢжӣІиүәдәәиЎЁmars_tianchi_songs.csvгҖӮеӨ§иөӣејҖж”ҫжҠҪж ·зҡ„жӯҢжӣІиүәдәәж•°жҚ®пјҢд»ҘеҸҠе’Ңиҝҷдәӣиүәдәәзӣёе…ізҡ„6дёӘжңҲеҶ…пјҲ20150301-20150831пјүзҡ„з”ЁжҲ·иЎҢдёәеҺҶеҸІи®°еҪ•гҖӮйҖүжүӢйңҖиҰҒйў„жөӢиүәдәәйҡҸеҗҺ2дёӘжңҲпјҢеҚі60еӨ©пјҲ20150901-20151030пјүзҡ„ж’ӯж”ҫж•°жҚ®гҖӮ

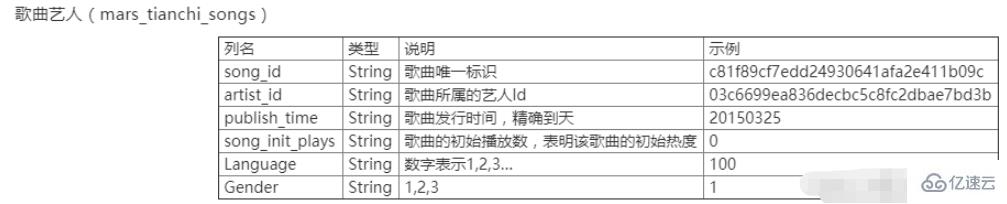

е®һйӘҢеҶ…е®№
еҜ№жӯҢжӣІиүәдәәж•°жҚ®mars_tianchi_songsиҝӣиЎҢеӨ„зҗҶпјҢз»ҹи®ЎеҮәиүәдәәзҡ„дёӘж•°д»ҘеҸҠжҜҸдёӘиүәдәәзҡ„жӯҢжӣІж•°йҮҸгҖӮиҫ“еҮәж–Үд»¶ж јејҸдёәexp2_1.csvпјҢ第дёҖеҲ—дёәиүәдәәзҡ„IDпјҢ第дәҢеҲ—дёәиҜҘиүәдәәзҡ„жӯҢжӣІж•°зӣ®гҖӮжңҖеҗҺдёҖиЎҢиҫ“еҮәиүәдәәзҡ„дёӘж•°гҖӮ
е°Ҷз”ЁжҲ·иЎҢдёәиЎЁе’ҢжӯҢжӣІиүәдәәиЎЁд»ҘжӯҢжӣІsong_idдҪңдёәе…іиҒ”пјҢеҗҲ并дёәдёҖдёӘеӨ§иЎЁгҖӮеҗ„еҲ—еҗҚз§°дёә第дёҖеҲ°з¬¬дә”еҲ—дёҺз”ЁжҲ·иЎҢдёәиЎЁзҡ„еҲ—еҗҚдёҖиҮҙпјҢ第е…ӯеҲ°з¬¬еҚҒеҲ—дёәжӯҢжӣІиүәдәәиЎЁдёӯзҡ„第дәҢеҲ—еҲ°з¬¬е…ӯеҲ—зҡ„еҲ—еҗҚгҖӮиҫ“еҮәж–Ү件еҗҚдёәexp2_2.csvгҖӮ
жҢүз…§иүәдәәз»ҹи®ЎжҜҸдёӘиүәдәәжҜҸеӨ©жүҖжңүжӯҢжӣІзҡ„ж’ӯж”ҫйҮҸпјҢиҫ“еҮәж–Ү件дёәexp2_3.csvпјҢеҗ„дёӘеҲ—еҗҚдёәиүәдәәid,ж—ҘжңҹDs,жӯҢжӣІж’ӯж”ҫжҖ»йҮҸгҖӮжіЁж„ҸпјҡиҝҷйҮҢеҸӘз»ҹи®ЎжӯҢжӣІзҡ„ж’ӯж”ҫйҮҸпјҢдёҚеҢ…жӢ¬дёӢиҪҪе’Ң收и—Ҹзҡ„ж•°йҮҸгҖӮ
и§ЈйўҳжҖқи·ҜпјҡпјҲеҲ©з”Ёpandasеә“пјү
1.
пјҲ1пјүеҲ©з”Ё.drop_duplicates() еҲ йҷӨйҮҚеӨҚеҖј
пјҲ2пјүеҲ©з”Ё.loc[:,‘artist_id’].value_counts() жұӮеҮәжӯҢжүӢйҮҚеӨҚж¬Ўж•°пјҢеҚіжҜҸдёӘжӯҢжүӢзҡ„жӯҢжӣІж•°зӣ®
пјҲ3пјүеҲ©з”Ё.loc[:,‘songs_id’].value_counts() жұӮеҮәжӯҢжӣІжІЎжңүйҮҚеӨҚ
import pandas as pd
data = pd.read_csv(r"C:\mars_tianchi_songs.csv") # иҜ»еҸ–ж•°жҚ®
Newdata = data.drop_duplicates(subset=['artist_id']) # еҲ йҷӨйҮҚеӨҚеҖј
artist_sum = Newdata['artist_id'].count()
#artistChongFu_count = data.duplicated(subset=['artist_id']).count() artistChongFu_count = data.loc[:,'artist_id'].value_counts() йҮҚеӨҚж¬Ўж•°пјҢеҚіжҜҸдёӘжӯҢжүӢзҡ„жӯҢжӣІж•°зӣ®
songChongFu_count = data.loc[:,'songs_id'].value_counts() # жІЎжңүйҮҚеӨҚпјҲжӯҢжүӢпјү
artistChongFu_count.loc['artist_sum'] = artist_sum # жІЎжңүйҮҚеӨҚпјҲжӯҢжӣІпјүartistChongFu_count.to_csv('exp2_1.csv') # иҫ“еҮәж–Үд»¶ж јејҸдёәexp2_1.csvеҲ©з”Ёmerge()еҗҲ并дёӨдёӘиЎЁ
import pandas as pd import os
data = pd.read_csv(r"C:\mars_tianchi_songs.csv")
data_two = pd.read_csv(r"C:\mars_tianchi_user_actions.csv")
num=pd.merge(data_two, data) num.to_csv('exp2_2.csv')еҲ©з”Ёgroupby()[].sum()иҝӣиЎҢйҮҚеӨҚжҖ§зӣёеҠ
import pandas as pd
data =pd.read_csv('exp2_2.csv')
DataCHongfu = data.groupby(['artist_id','Ds'])['gmt_create'].sum()#йҮҚеӨҚйЎ№зӣёеҠ DataCHongfu.to_csv('exp2_3.csv')д»ҘдёҠе°ұжҳҜе…ідәҺвҖңжҖҺд№ҲдҪҝз”ЁPythonж“ҚдҪңж–Үжң¬ж•°жҚ®вҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





