在imooc网上跟着老师写了两个爬虫,一个最简单的直接爬整个页面,一个完善版把章节标题和对应编号打出来了。
看完之后,自己也想写一个爬虫,用自己的博客做测试,虽然结果并没有很成功- -,还是把代码放上来。
目标是抓取章节的标题。
博客页面:
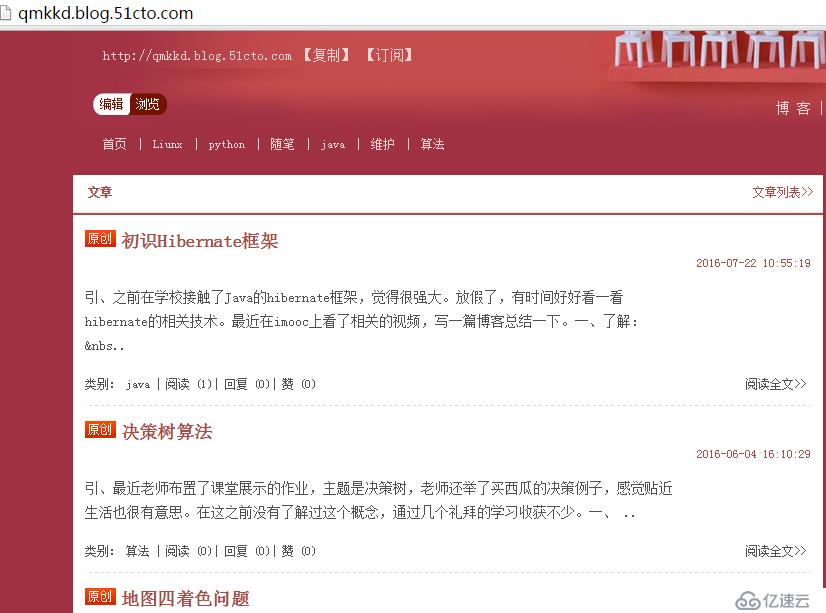
对应标签:

页面源代码:
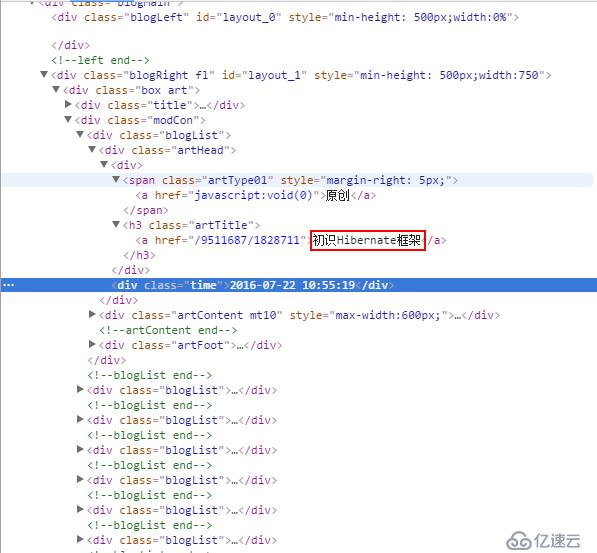
经过分析,我们应该要抓取class=artHead的<div>,往下还有一个没有类的<div>,然后找到它的<h4>标签下子标签<a>的内容,就是章节的名字。
上代码:
//引入http模块
var http = require('http');
//确定要抓取的页面
//debug:本来写了qmkkd.blog.51cto.com,一直出错,在前面加上http就好了。
var url = '';//这里的url是'http://qmkkd.blog.51cto.com';,博客显示不出来,有毒
//引入cherrio模块,类似服务器端的jquery
var cheerio=require('cheerio');
function filterChapters(html){
//将html变成jquery对象
var $ = cheerio.load(html);
var artHeads = $('.artHead');
var blogData=[];
artHeads.each(function(item){
var artHead = $(this);
//获取文章标题
var artTitle = artHead.find('h4').children('a').text();
blogData.push(artTitle);
})
return blogData;
}
function printBlogInfo(blogData){
blogData.forEach(function(item){
var artTitle = item;
console.log(item+'\n');
})
}
http.get(url,function(res){
var buffers=[];
var nread = 0;
res.on('data',function(data){
buffers.push(data);
nread+=data.length;
});
//网上找到的处理中文乱码问题的方法,但好像没有解决T_T
//之后还采用了bufferhelper类,好像也不对=-=
//应该是基础不好的问题,暂时debug不了,先放着
res.on('end',function(){
var buffer =null;
switch(buffers.length){
case 0:buffer=new Buffer(0);
break;
case 1:buffer=buffers[0];
break;
default:
buffer = new Buffer(nread);
for(var i=0,pos=0,l=buffers.length;i<l;i++){
var chunk = buffers[i];
chunk.copy(buffer,pos);
pos+=chunk.length;
}
break;
}
var html=buffer.toString();
var blogData = filterChapters(html);
printBlogInfo(blogData);
})
}).on('error',function(){ //执行http请求失败时,返回错误信息
console.log('获取博客数据出错');
})亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



