以下文章的前半部分是我看的时候从网络上面找的一篇指导性质的文章,写的还不错,相同的道理和话就不重复的说了,主要是语言表达能力也不好。所以我拿过来用用,后半段是我自己的解读。
考虑到作者的版权问题我们附上作者原文章地址:http://www.cnblogs.com/aaronjs/p/3370176.html
一般jQuery开发,我们都喜欢便捷式的把很多属性,比如状态标志都写到dom节点中,也就是HTMLElement
好处:直观,便捷
坏处:
循环引用
直接暴露数据,安全性?
增加一堆的自定义属性标签,对浏览器来说是没意义的
取数据的时候要对HTML节点做操作
什么是内存泄露
内存泄露是指一块被分配的内存既不能使用,又不能回收,直到浏览器进程结束。在C++中,因为是手动管理内存,内存泄露是经常出现的事情。而现在流行的C#和Java等语言采用了自动垃圾回收方法管理内存,正常使用的情况下几乎不会发生内存泄露。浏览器中也是采用自动垃圾回收方法管理内存,但由于浏览器垃圾回收方法有bug,会产生内存泄露。
内存泄露的几种情况
循环引用
Javascript闭包
DOM插入顺序
一个DOM对象被一个Javascript对象引用,与此同时又引用同一个或其它的Javascript对象,这个DOM对象可能会引发内存泄漏。这个DOM对象的引用将不会在脚本停止的时候被垃圾回收器回收。要想破坏循环引用,引用DOM元素的对象或DOM对象的引用需要被赋值为null。
含有DOM对象的循环引用将导致大部分当前主流浏览器内存泄露
第一种:多个对象循环引用

var a=new Object;var b=new Object; a.r=b; b.r=a;
第二种:循环引用自己
var a=new Object; a.r=a;
循环引用很常见且大部分情况下是无害的,但当参与循环引用的对象中有DOM对象或者ActiveX对象时,循环引用将导致内存泄露。
我们把例子中的任何一个new Object替换成document.getElementById或者document.createElement就会发生内存泄露了。
具体的就深入讨论了,这里的总结
JS的内存泄露,无怪乎就是从DOM中remove了元素,但是依然有变量或者对象引用了该DOM对象。然后内存中无法删除。使得浏览器的内存占用居高不下。这种内存占用,随着浏览器的刷新,会自动释放。
而另外一种情况,就是循环引用,一个DOM对象和JS对象之间互相引用,这样造成的情况更严重一些,即使刷新,内存也不会减少。这就是严格意义上说的内存泄露了。
所以在平时实际应用中, 我们经常需要给元素缓存一些数据,并且这些数据往往和DOM元素紧密相关。由于DOM元素(节点)也是对象, 所以我们可以直接扩展DOM元素的属性,但是如果给DOM元素添加自定义的属性和过多的数据可能会引起内存泄漏,所以应该要尽量避免这样做。 因此更好的解决方法是使用一种低耦合的方式让DOM和缓存数据能够联系起来。
jQuery引入缓存的作用
允许我们在DOM元素上附加任意类型的数据,避免了循环引用的内存泄漏风险
用于存储跟dom节点相关的数据,包括事件,动画等
一种低耦合的方式让DOM和缓存数据能够联系起来
jQuery缓存系统的真正魅力在于其内部应用中,动画、事件等都有用到这个缓存系统。试想如果动画的队列都存储到各DOM元素的自定义属性中,这样虽然可以方便的访问队列数据,但也同时带来了隐患。如果给DOM元素添加自定义的属性和过多的数据可能会引起内存泄漏,所以要尽量避免这么干。
数据缓存接口
对于jQuery.data方法,原文如下
The jQuery.data() method allows us to attach data of any type to DOM elements in a way that is safe from circular references and therefore from memory leaks. We can set several distinct values for a single element and retrieve them later:
在jQuery的官方文档中,提示用户这是一个低级的方法,应该用.data()方法来代替。$.data( element, key, value )可以对DOM元素附加任何类型的数据,但应避免循环引用而导致的内存泄漏问题
都是用来在元素上存放数据也就平时所说的数据缓存,都返回jQuery对象,但是内部的处理确有本质的区别
我们看一组对比
<div id="aaron">Aron test</div>
var aa1=$("#aaron");var aa2=$("#aaron");//=======第一组=========$(''
).data()方法aa1.data('a',1111);
aa2.data('a',2222);
aa1.data('a') //结果222222aa2.data('a') //结果222222//=======第二组=========$.data()方法$.data(aa1,"b","1111")
$.data(aa2,"b","2222")
$.data(aa1,"b") //结果111111$.data(aa2,"b") //结果222222
意外吗?,这样的细节以前是否注意到呢?
怎么通过.data()方法会覆盖前面key相同的值呢?
对于jQuery来说,数据缓存系统本来就是为事件系统服务而分化出来的,到后来,它的事件克隆乃至后来的动画列队实现数据的存储都是离不开缓存系统,所以数据缓存也算是jQuery的一个核心基础了
早期jQuery的缓存系统是把所有数据都放$.cache之上,然后为每个要使用缓存系统的元素节点,文档对象与window对象分配一个UUID
data的实现不像attr直接把数据作为属性捆绑到元素节点上,如果为DOM Element 附加数据;DOM Element 也是一种 Object ,但 IE6、IE7 对直接附加在 DOM Element 上的对象的垃圾回收存在问题;因此我们将这些数据存放在全局缓存(我们称之为“globalCache”)中,即 “globalCache” 包含了多个 DOM Element 的 “cache”,并在 DOM Element 上添加一个属性,存放 “cache” 对应的 uid
$().data('a') 在表现形式上,虽然是关联到dom上的,但是实际上处理就是在内存区开辟一个cache的缓存
那么JQuery内部是如何处理,各种关联情况与操作呢?
******************$(‘’).data()的实现方式********************
用name和value为对象附加数据
var obj = {};
$.data(obj, 'name', 'aaron');
$.data(obj,'name') //aaron
一个对象为对象附加数据
var obj = {};
$.data(obj, {
name1: 'aaron1',
name2: 'aaron1'
});
$.data(obj) //Object {name1: "aaron1", name2: "aaron1"}
为 DOM Element 附加数据
我们用最简单的代码来阐述这个处理的流程:
1.获取节点body
var $body = $("body")2.给body上增加一条数据,属性为foo,值为52
$body.data("foo", 52);3.取出foo
$body.data('foo')
考虑一个问题:
一个元素在正常情况下可以使用.remove()方法将其删除,并清除各自的数据。但对于本地对象而言,这是不能彻底删除的,这些相关的数据一直持续到窗口对象关闭
同样,这些问题也存在于event 对象中,因为事件处理器(handlers)也是用该方法来存储的。
那么,要解决该问题最简单的方法是将数据存储到本地对象新增的一个属性之中
所以如流程二解析一样增加一个unlock标记
cache与elem 都统一起来
if ( elem.nodeType ) {
cache[ id ] = dataObject;
elem[ expando ] = id;
} else {
elem[ expando ] = dataObject;
}
**************实现解析****************
(1)先在jQuery内部创建一个cache对象{}, 来保存缓存数据。 然后往需要进行缓存的DOM节点上扩展一个值为expando的属性,
function Data() {
Object.defineProperty( this.cache = {}, 0, {
get: function() { return {};
}
}); this.expando = jQuery.expando + Math.random();
}
注:expando的值,用于把当前数据缓存的UUID值做一个节点的属性给写入到指定的元素上形成关联桥梁,所以,所以元素本身具有这种属性的可能性很少,所以可以忽略冲突。
(2)接着把每个节点的dom[expando]的值都设为一个自增的变量id,保持全局唯一性。 这个id的值就作为cache的key用来关联DOM节点和数据。也就是说cache[id]就取到了这个节点上的所有缓存,即id就好比是打开一个房间(DOM节点)的钥匙。 而每个元素的所有缓存都被放到了一个map映射里面,这样可以同时缓存多个数据。
Data.uid = 1;
关联起dom对象与数据缓存对象的一个索引标记,换句话说
先在dom元素上找到expando对应值,也就uid,然后通过这个uid找到数据cache对象中的内容
(3)所以cache对象结构应该像下面这样:
var cache = { "uid1": { // DOM节点1缓存数据,
"name1": value1, "name2": value2
}, "uid2": { // DOM节点2缓存数据,
"name1": value1, "name2": value2
} // ......};
每个uid对应一个elem缓存数据,每个缓存对象是可以由多个name/value(名值对)对组成的,而value是可以是任何数据类型的。
流程分解:(复杂的过滤,找重的过程去掉)
第一步:jQuery本身就是包装后的数组结构,这个不需要解析了
第二步:通过data存储数据
为了把不把数据与dom直接关联,所以会把数据存储到一个cache对象上
产生一个 unlock = Data.uid++; unlock 标记号
把unlock标记号,作为一个属性值 赋予$body节点
cache缓存对象中开辟一个新的空间用于存储foo数据,this.cache[ unlock ] = {};
最后把foo数据挂到cache上,cache[ data ] = value;
第三步:通过data获取数据
从$body节点中获取到unlock标记
通过unlock在cache中取到对应的数据
流程图:
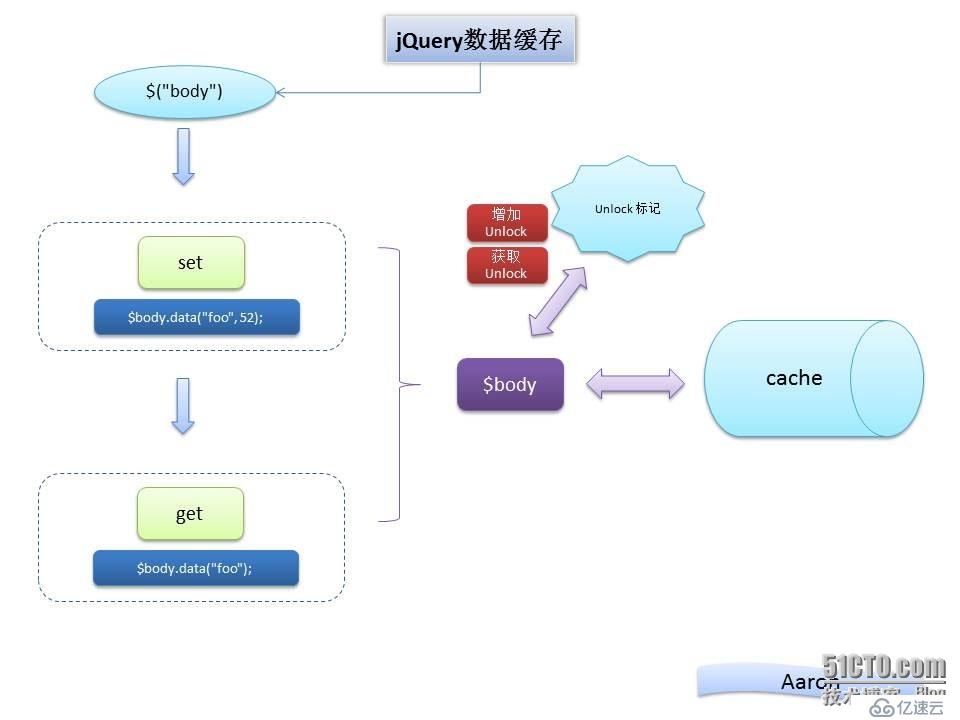
整个过程结束,其实分解后逻辑很简单的,只是要处理各种情况下,代码结构封装就显得很复杂了
Body元素:expando:uid
jQuery203054840829130262140.37963378243148327: 3
数据缓存cache
uid:Object
那么jQuery.data() 与 .data() 有什么区别?
1.jQuery.data(element,[key],[value])源代码
jQuery.extend({
acceptData: Data.accepts,
hasData: function( elem ){}, //直接调用 data_user.access 数据类的接口,传入的是elem整个jQuery对象
data: function( elem, name, data ) { return data_user.access( elem, name, data );
},
........
2.data([key],[value])
jQuery.fn.extend({
data: function( elem, name, data ) { return jQuery.access( this, function( value )){ //区别在each方法了,处理的是每一个元素dom节点
this.each(function() {
}
}
}
},
........
源代码从源码的简单对比就很明显的看出来
看jQuery.data(element,[key],[value]),每一个element都会有自己的一个{key:value}对象保存着数据,所以新建的对象就算有key相同它也不会覆盖原来存在的对象key所对应的value,因为新对象保存是是在另一个{key:value}对象中
$("div").data("a","aaaa") 它是把数据绑定每一个匹配div节点的元素上
源码可以看出来,说到底,数据缓存就是在目标对象与缓存体间建立一对一的关系,整个Data类其实都是围绕着 thia.cache 内部的数据做 增删改查的操作
为了更准确的理解jq的data函数处理,我自己写了一个方法来实现data,数据缓存:
var $ = {};
//这个模拟的就是jquery中的全局的缓存
$.catche = {};
//这个就是模拟了jq的全局缓存的一个标志key
$.internalKey = (new Date()).getTime();
//这个就是类uuid的用法
$.prop_index = 1;
//获取得到元素
var obj = document.querySelector("#testDiv");
/***
*这就是模拟jq的data方法做的数据缓存
**/
function data(obj,attr,val){
//判断obj是否是节点
var isNode = obj.nodeType;
var ele;
//参数修正
if(!isNode){
if(arguments.length <= 2){
val = attr;
attr = obj;
ele = this;
}
}else{
ele = obj;
}
isNode = ele.nodeType;
//获得数据的id
var id = isNode?ele[$.internalKey]:ele[$.internalKey]&&$.internalKey;
//如果不存在id
if(!id){
//在jq里面还实现了,从已经删除的id序列里面启用删除过的id
id = isNode?ele[$.internalKey]= $.prop_index++: $.internalKey;
}
var valObj = isNode?$.catche:ele;
if(!valObj[id]){
valObj[id] = {};
}
var returnData = "";
if(typeof attr == "string"){
if(val != undefined)
{
returnData = val;
valObj[id][attr] = val;
}else{
returnData = valObj[id][attr];
}
}else{
returnData = valObj[id];
}
$.catche = valObj;
return returnData;
}
obj.data = data;
// console.log(data(obj,"hell","1212"));
// console.log(data(obj,"hell"));
obj.data("hello","aaa");
console.log("val:"+obj.data("hello"));通过自己的测试实现了jq的data的数据缓存,也无需在dom元素节点上面添加任何属性,这个大概就是jquery的实现data数据缓存的机制。如果有理解不当的地方望指正。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





