我们先看一下HashSet和TreeSet在整个集合框架中的位置。他们都实现了Set接口。他们之间的区别是HashSet不能保证元素的顺序,TreeSet中的元素可以按照某个顺序排列。他们的元素都不能重复。
先来看一下HashSet:
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("张三");
set.add("李四");
set.add("王五");
System.out.println(set);
System.out.println(set.size());
System.out.println(set.contains("张三"));
}
打印输出的顺序是是: [李四, 张三, 王五]
可以看出和存进去的顺序不一致。
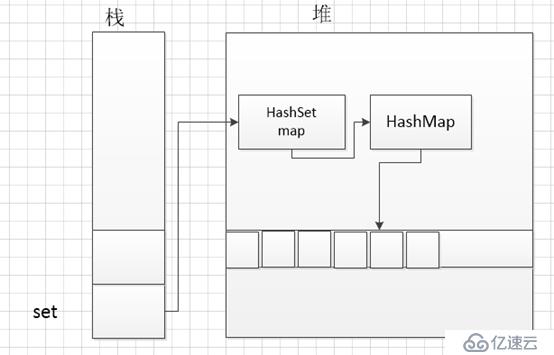
我们先看一下 Set<String> set = new HashSet<String>();
这行代码创建了一个HashSet,构造函数如下:
public HashSet() {
map = new HashMap<>();
}
可以看到实际上是创建了一个HashMap的对象。没错,HashSet底层就是一个HashMap.
再来看一下这行代码:set.add("张三");
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
非常的简单,就是调用了一下HashMap的put方法对元素进行插入。
这里的PERSENT是什么呢?继续顺藤摸瓜:
private static final Object PRESENT = new Object();原来就是一个普通的Object对象前面用static final修饰说明是不可变的。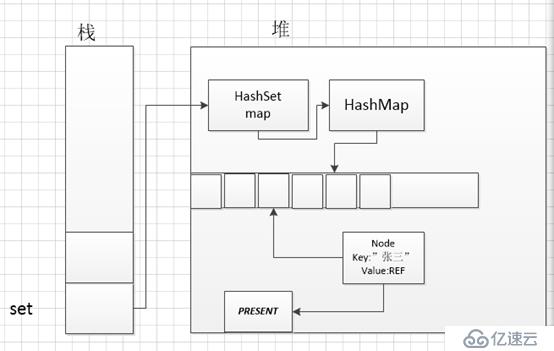
继续添加:set.add("李四");
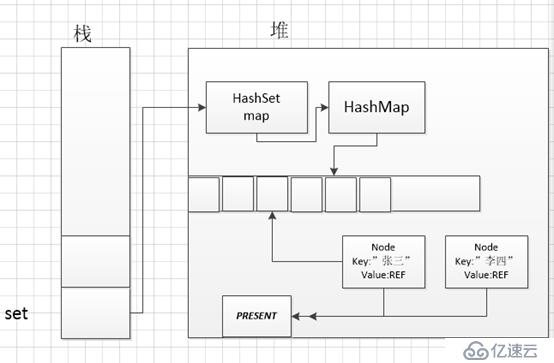
可以看出来HashMap的key分别为”张三”,”李四”,“王五”, 因为HashSet用不到value,他们的value都是一样的指向同一个地方。继续往下看:System.out.println(set.size());public int size() {
return map.size();
}
也是调用的HashMap的size方法。
System.out.println(set.contains("张三"));
public boolean contains(Object o) {
return map.containsKey(o);
}
同样调用的HashMap的contains方法。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



