要想更好的理解volatile关键字,我们先来聊聊基于高速缓存的存储交互:
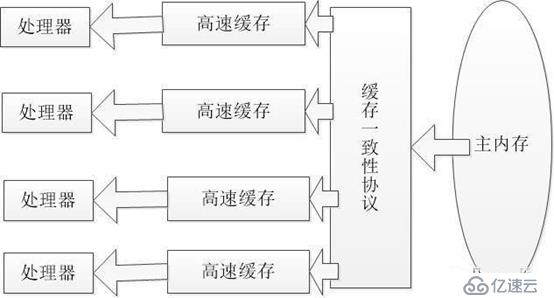
我们知道程序中进行计算的变量是存储在内存中的,而处理器的计算速度和内存的读取速度完全不在一个量级,区别犹如兰博基尼和自行车。
要让兰博基尼开一小段就停下来等会自行车显然不太合适,所以在处理器和内存之间加了一个高速缓存,高速缓存速度远高于内存,犹如奔驰,虽然和兰博基尼还有一定差距,每个处理器都对应一个高速缓存。
当要对一个变量进行计算的时候,先从内存中将该变量的值读取到高速缓存中,再去计算,效率得到明显提升,这是从硬件的的视角描述的内存。
Jvm虚拟机从另一个视角定义的内存模型规定所有变量都存储在主内存中,每个线程有自己的工作内存,每个线程的工作内存只能被该线程独占,其它线程不能访问,所有的线程只能通过主内存来共享数据。
这里的主内存可以类比于硬件视角的内存,工作内存可以类比于硬件视角的高速缓存。
线程执行程序的时候先将主内存中的变量复制到工作内存中进行计算,计算完毕后再将变量同步到主内存中。
这么做虽然解决了执行效率的问题,但是同时也带来了其它问题。
试想一下,线程A从主内存中复制了一个变量a=3到工作内存,并且对变量a进行了加一操作,a变成了4,此时线程B也从主内存中复制该变量到它自己的工作内存,它得到的a的值还是3,a的值不一致了。
用专业术语来说就是变量的可见性,此时变量a对于线程来说变得不可见了。
怎么解决这个问题?
volatile关键字闪亮登场:
当一个变量被定义为volatile之后,它对所有的线程就具有了可见性,也就是说当一个线程修改了该变量的值,所有的其它线程都可以立即知道,可以从两个方面来理解这句话:
1.线程对变量进行修改之后,要立刻回写到主内存。
2.线程对变量读取的时候,要从主内存中读,而不是工作内存。
但是这并不意味着使用了volatile关键字的变量具有了线程安全性,举个栗子:
public class AddThread implements Runnable {
private volatile int num=0;
@Override
public void run() {
for (int i=1;i<=10000;i++){
num=num+1;
System.out.println(num);
}
}
}
public class VolatileThread {
public static void main(String[] args) {
Thread[] th = new Thread[20];
AddThread addTh = new AddThread();
for(int i=1;i<=20;i++){
th[i] = new Thread(addTh);
th[i].start();
}
}
}
这里我们创建了20个线程,每个线程对num进行10000次累加。
按理结果应该是打印1,2,3.。。。。。200000 。
但是结果却是1,2,3…..x ,x小于200000.
为什么会是这样的结果?
我们仔细分析一下这行代码:num=num+1;
虽然只有一行代码,但是被编译为字节码以后会对应四条指令:
1.Getstatic将num的值从主内存取出到线程的工作内存
2.Iconst_1 和 iadd 将num的值加一
3.Putstatic将结果同步回主内存
在第一步Getstatic将num的值从主内存取出到线程的工作内存因为num加了Volatile关键字,可以保证它的值是正确的,但是在执行第二步的时候其它的线程有可能已经将num的值加大了。在第三步就会将较小的值同步到内存,于是造成了我们看到的结果。
既然如此,Volatile在什么场合下可以用到呢?
一个变量,如果有多个线程只有一个线程会去修改这个变量,其它线程都只是读取该变量的值就可以使用Volatile关键字,为什么呢?一个线程修改了该变量,其它线程会立刻获取到修改后的值。
因为Volatile的特性可以保证这些线程获取到的都是正确的值,而他们又不会去修改这个变量,不会造成该变量在各个线程中不一致的情况。当然这种场合也可以用synchronized关键字
当运算结果并不依赖变量的当前值的时候该变量也可以使用Volatile关键字,上栗子:
public class shutDownThread implements Runnable {
volatile boolean shutDownRequested;
public void shutDown(){
shutDownRequested = true;
}
@Override
public void run() {
while (!shutDownRequested) {
System.out.println("work!");
}
}
}
public class Demo01 {
public static void main(String[] args) throws InterruptedException {
Thread[] th = new Thread[10];
shutDownThread t = new shutDownThread();
for(int i=0;i<=9;i++){
th[i] = new Thread(t);
th[i].start();
}
Thread.sleep(2000);
t.shutDown();
}
}
当调用t.shutDown()方法将shutDownRequested的值设置为true以后,因为shutDownRequested 使用了volatile ,所有线程都获取了它的最新值true,while循环的条件“!shutDownRequested”不再成立,“ System.out.println("work!");”打印work的代码也就停止了执行。
Volatile还可以用来禁止指令重排序。
什么是指令重排序?
Int num1 = 3; 1
Int num2 = 4; 2
Int num3 = num1+num2; 3
在这段代码中cpu在执行的时候会对代码进行优化,以达到更快的执行速度,有可能会交换1处和2处的代码执行的顺序,这就是指令重排序。
指令重排序并不是为了执行速度不择手段的任意重排代码顺序,这样必然会乱套,重排序必须遵循一定的规则,1处和2处的代码之间没有任何关系,他们的执行顺序对结果不会照成任何影响,也就是说1->2>3的执行和2->1->3的执行最后结果都为num3=7.我们说1处和2处的操作没有数据依赖性,没有数据依赖性的代码可以重排序。
再看一下2处和3处的代码,如果把他们交换顺序,结果会不一样,为什么会不一样呢?因为这两处操作都操作了num2这个变量,并且在第二处操作中修改了num2的值。
如果有两个操作操作了同一个变量,并且其中一个为写操作,那么这两个操作就存在数据依赖性,对于有数据依赖性的操作,不能重排序,所以2处和3处的操作不能重排序。
还有一个规则是无论怎么重新排序,单线程的执行结果不能被改变,也就是说在单线程的情况下,我们是感受不到重排序带来的影响的。
在多线程的情况下重排序会对程序造成什么影响呢?
举个栗子:
//定义一个布尔型的变量表示是否读取配置文件,初始为未读取
Volatile boolean flag = false; 1
//线程A执行 读取配置文件以后将flag改为true
readConfig(); 2
flag = true; 3
//线程B执行循环检测flag,如果为false表示未读取配置文件,则休眠。如果为true表示已读取配置文件,则执行doSomething()
while(!flag){ 4
sleep(); 5
}
doSomething(); 6
在这段伪代码中如果1处的代码没有用Volatile关键字,可能由于指令重排序的优化,在A线程中,3处的代码 flag=true在2处代码之前执行,导致B线程在配置文件还未读取的情况下去执行相关操作,从而引起错误。
而Volatile关键字可以避免这种情况发生。
他是如何做到的呢?
通过汇编代码可以看出,在3处当我们对Volatile修饰的变量做赋值操作的时候,多执行了一个指令 “lock add1 $0x0,(%esp)”.
这个指令的作用是使该指令之后的所有操作不能重排序到该指令的前面,专业术语叫做内存屏障。
正是因为内存屏障的存在能够保证代码的正确执行,所以读取Volatile关键字修饰的变量和普通变量没有什么差别,但是做写入操作的时候由于要插入内存屏障,会影响到效率。
实际上在jdk对Synchronized进行优化以后,Synchronized的性能明显提升和Volatile已经差别不大了,Volatile的用法比较复杂,容易出错,Synchronized也可以解决变量可见性的问题,所以通常情况下我们优先选择Synchronized,但是Synchronized不能禁止指令重排序,貌似这是Volatile的适用场合。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



