什么是哈希算法?相信大部分人都不太了解,今天小编为了让大家更加了解哈希算法,给大家总结了以下内容,一起往下看吧。
HashTable--哈希表,是一种典型的 "key--value" 形式的数据结构,构建这种数据结构的目的,是为了使用户通过 key 值快速定位到我的 value ,从而进行相应的增删查改的工作。当数据量较小时,简单遍历也能达到目的,但面对大量数据处理时,造成时间和空间上的消耗,不是一般人可以承担的起的。
首先,先简单了解一下,什么是哈希。
我们的目的是在一堆数据中查找(这里以×××为例),为了节省空间,我们不可能列出一个有所有数据范围那么大的数组,因此这里我们需要建立一种映射关系HashFunc,把我的所有数据通过映射放到这段空间当中,因此哈希表也叫作散列表。
1>直接定值法
直接定址法是最简单的方法,取出关键字之后,直接或通过某种线性变换,作为我的散列地址。例如:Hash(key) = key*m+n;其中m、n为常数。
2、除留余数法
除留余数法是让我的关键码 key 通过对我的数组长度取模,得到的余数作为当前关键字的哈希地址。
除了以上的两种方法,还有平方取中法、折叠法、随机数法、平方分析法等,虽然方法不同,但目的都是一样的,为了得到每个关键字 key 的地址码,这里不再赘述。
经过 HashFunc 函数处理之后,得到了每个关键字的哈希地址,正如上面提到的,很容易出现两个关键码的哈希地址相同或者哈希地址已经被其他关键字占用的情况,这种情况我们叫做哈希冲突,或者哈希碰撞。这是在散列表中不可避免的。
这里定义了一个新名词--载荷因子α
α = 填入表中的元素个数 / 散列表的长度
载荷因子表示的是填入表中的数据占表总长度的比例。当我们在哈希表中查找一个对象时,平均查找长度是载荷因子 α 的函数。散列表的底层是一个vector,当载荷因子超过一定量的时候,我们需要对vector进行resize扩容,来减小哈希表的插入及查找压力。
为了解决哈希冲突,这里有两种方法闭散列法<开放定址法>和拉链法<哈希桶>
 开放地址法:
开放地址法:
需要指出的一点,开放地址法构造的HashTable,对载荷因子的要求极其重要。应严格限制载荷因子在0.7~0.8以下,超过0.8,查表时的不命中率会成指数上升。
上面我们提到了两种HashFunc,针对这两种方法得到的哈希地址之后,我们可以做如下处理。当得到的地址码已经被占用,则我当前 key 的地址向后推移即可。这种方法叫做线性探测。
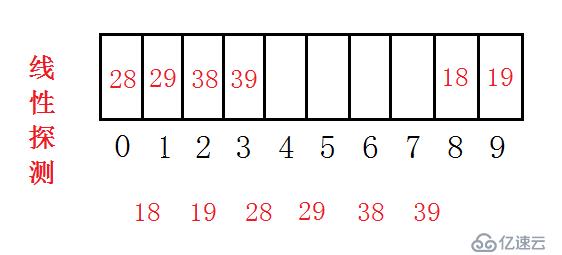
另外还有一种方法,二次探测法。解决思想是当我的哈希地址冲突后,每次不再是加1,而是每次加1^2,2^2,3^2...直到找到空的地址,这种方法很明显可以将各个数据分开,但会引入一个问题,会导致二次探测了多次,依然没有找到空闲的位置。这里用同一组例子来说明。
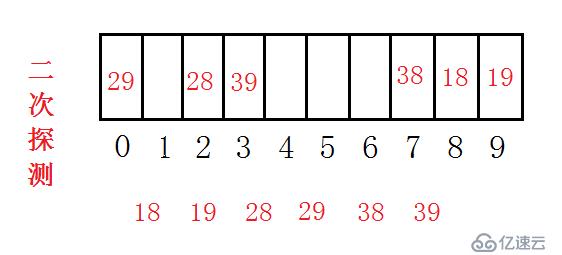
除此之外,为了减少哈希冲突,前人总结出了一组素数表,经过数学计算表明,使用苏鼠标对其做哈希表的容量,可以有效的降低哈希冲突。
const int _PrimeSize = 28;
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul,
786433ul, 1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul, 50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul, 1610612741ul, 3221225473ul, 4294967291ul
};代码实现与解释
这里首先给出哈希表中每个元素结点的类,同时给出 HashTable 的框架除了key、value之外,多增加了一个状态位,当下面用到的时候,会具体给出原因。
enum State
{
EMPTY,
EXIST,
DELETE
};
template <typename K ,typename V>
struct KVNode
{
K _key;
V _value;
State _state;
KVNode(const K& key = K(), const V& value = V())
:_key(key)
, _value(value)
, _state(EMPTY)
{}
};//Hashtable类
template <typename K, typename V>
class HashTable
{
typedef KVNode<K, V> Node;
public:
HashTable()
:_size(0)
{}
bool Insert(const K& key,const V& value)
{}
Node* Find(const K& key)
{}
bool Remove(const K& key)
{}
protected:
vector<Node> _table;
size_t _size;
};对于哈希表的插入,可以分为以下几步:
a) 进行容量检查
b) 通过取模得到该关键字在HashTable中的位置
c) 对得到的位置进行调整
这里要注意的一点,因为对于key_value类型的数据结构而言,关键字 key 是唯一 的,因此,当在调整的时候发现了和待插入 key 一样的值,直接返回 false 结束插入函数。
d) 对该位置的key、value、state进行调整
对于哈希表的删除,这里采用的是伪删除法。即找到该 key 之后,将该点的状态改为DELETE即可,因为我们在对 vector 进行扩容的时候,是通过resize实现的,不论是增加元素还是删除,resize出来的空间不需要去释放,这里可以减少内存的多次开辟与释放,提高效率。
另外,假设我们可以将这段空间的内容清空,会带来的问题就是,之前我们插入的时候,所有经过该结点调整过的key都需要重新移动,否则这个元素我们再也找不到。这就是我们这里引入三个状态的原因。
当找到该结点的位置之后,如果 key 值不是我们想要的 key 值,就需要继续向后找,只有当结点的状态位EMPTY时,查找才会停止,当然如果找到的EMPTY还是没有找到我们想要的 key 值,那么该关键字一定不在当前的哈希表中。需要注意,会不会存在一种情况,当我们在vector中遍历的时候,循环条件是当前结点的状态不为EMPTY,进入了死循环?会的。这是因为我们引入了DELETE的结果,设想表中的所有节点都是DELETE或者EXIST状态,且我们要查找的key不在HashTable中,死循环是必然的情况。
下面给出完整的实现代码:
template <typename K, typename V>
class HashTable
{
typedef KVNode<K, V> Node;
public:
HashTable()
:_size(0)
{}
bool Insert(const K& key,const V& value)
{
//容量检查
_CheckSize();
//获取关键字在HashTable中的位置
size_t index = _GetHashIndex(key);
//对位置进行调整
while (_table[index]._state == EXIST)
{
// 如果插入的key存在,返回false
if (_table[index]._key == key)
return false;
index++;//线性探测
if (index == _table.size())
index = 0;
}
//找到位置之后改变该位置的状态
_table[index]._key = key;
_table[index]._value = value;
_table[index]._state = EXIST;
_size++;
return true;
}
Node* Find(const K& key)
{
// 空表,直接返回
if (_table.empty())
return NULL;
size_t index = _GetHashIndex(key);
int begin = index;
while (_table[index]._state != EMPTY)
{
if (_table[index]._key == key)
{
// 该位置为已删除结点
if (_table[index]._state == DELETE)
return NULL;
else
return &_table[index];
}
//改变循环变量
index++;
if (index == _table.size())
index = 0;
// 循环一圈,没有找到
if (index == begin)
return NULL;
}
return NULL;
}
bool Remove(const K& key)
{
if (_table.empty())
return false;
Node* ret = Find(key);
if (ret != NULL)
{
ret->_state = DELETE;
--_size;
return true;
}
else
return false;
}
protected:
//获取key在HashTable中的位置
size_t _GetHashIndex(const K& key)
{
return key % _table.size();
}
//现代写法
void Swap(HashTable<K, V, HASHTABLE>& ht)
{
_table.swap(ht._table);
}
//容量检查
void _CheckSize()
{
//空表,或载荷因子大于等于8
if ((_table.size() == 0) || ((_size * 10) / _table.size() >= 8))
{
size_t newSize = _GetPrimeSize(_table.size());
HashTable<K, V, HASHTABLE> hasht;
hasht._table.resize(newSize);
// 将原来的HashTable中的key,value插入到新表中
for (size_t i = 0; i < _table.size(); i++)
{
if (_table[i]._state == EXIST)
{
hasht.Insert(_table[i]._key, _table[i]._value);
}
}
this->Swap(hasht);
}
}
// 从素数表找到下次扩容的容量
size_t _GetPrimeSize(const size_t& size)
{
const int _PrimeSize = 28;
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul,
786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (size_t i = 0; i < _PrimeSize; i++)
{
if (_PrimeList[i] > size)
return _PrimeList[i];
}
return _PrimeList[_PrimeSize-1];
}
protected:
vector<Node> _table;
size_t _size;
};拉链法:
对于拉链法,这里实际上是构建了哈希桶。如图:
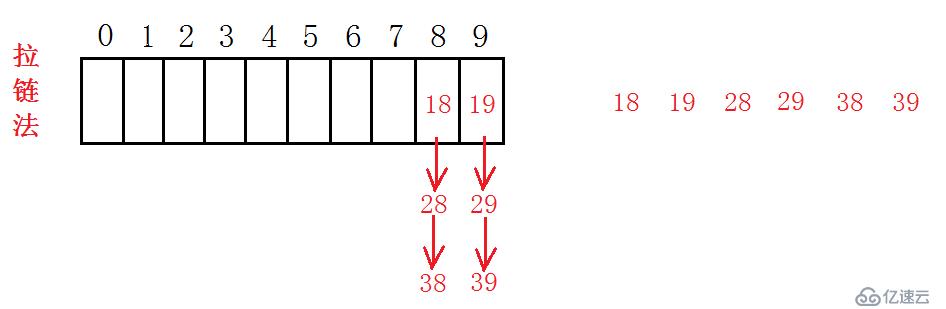 同样一组数据放到拉链法构成的哈希表中,每一个结点不再是只记录key、value值,这里多存放了一个指向next的指针,这样的话vector的每个点上都可以向下追加任意个结点。拉链法似乎更加的有效,载荷因子在这里也显得不是那么重要,但我们依旧需要考虑这个问题。载荷因子虽然在这里的限制比开放地址法更加宽松了些,但是如果我们只是在10个结点下无限制的串加结点,也是会增大查找的时间复杂度。这里我们把载荷因子提高到1,减轻增容的压力。另外,vector中保存的是 Node* ,这是为了兼容我的向下指针,这样的话,也就不再需要状态标志。初次之外,其他部分和开放地址法相比,思想大致相同。
同样一组数据放到拉链法构成的哈希表中,每一个结点不再是只记录key、value值,这里多存放了一个指向next的指针,这样的话vector的每个点上都可以向下追加任意个结点。拉链法似乎更加的有效,载荷因子在这里也显得不是那么重要,但我们依旧需要考虑这个问题。载荷因子虽然在这里的限制比开放地址法更加宽松了些,但是如果我们只是在10个结点下无限制的串加结点,也是会增大查找的时间复杂度。这里我们把载荷因子提高到1,减轻增容的压力。另外,vector中保存的是 Node* ,这是为了兼容我的向下指针,这样的话,也就不再需要状态标志。初次之外,其他部分和开放地址法相比,思想大致相同。
template<typename K,typename V>
struct KVNode
{
K _key;
V _value;
KVNode<K, V>* _next;
KVNode(const K& key, const V& value)
:_key(key)
, _value(value)
, _next(NULL)
{}
};
template<typename K, typename V>
class HashTableList
{
typedef KVNode<K, V> Node;
public:
HashTableList()
:_size(0)
{}
Node* Find(const K& key)
{}
bool Insert(const K& key,const V& value)
{}
bool Remove(const K& key)
{}
protected:
vector<Node*> _htlist;
size_t _size;
}; 插入结点:这里我采用的是头插法,原因其实很简单,因为头插的效率比较高,而且只要简单想想,就可以发现,除了结点已经存在以外,其他这里的所有情况可以统一来处理,这就大大简化了代码的冗杂。
查找结点:查找的话,首先定位到哈希地址,然后只需要在对应的位置向下遍历即可。
删除结点:删除结点不建议调用Find函数,如没有找到的话,直接返回,但如果找到的话,还需要再找一遍去删除。所以这里直接去哈希中找相应的key。首先还是需要定位到key所对应的哈希地址,只要不为NULL,就一直向下查找,找不到就返回false,找到了直接 delete 掉就好。
下面给出完整的实现代码:
template<typename K, typename V>
class HashTableList
{
typedef KVNode<K, V> Node;
public:
HashTableList()
:_size(0)
{}
Node* Find(const K& key)
{
if (_htlist.empty())
return NULL;
int index = GetHashIndex(key);
Node* cur = _htlist[index];
while (cur)
{
if (cur->_key == key)
return cur;
cur = cur->_next;
}
return NULL;
}
bool Insert(const K& key,const V& value)
{
_Check();
size_t index = GetHashIndex(key);
if (Find(key))
return false;
Node* tmp = new Node(key, value);
tmp->_next = _htlist[index];
_htlist[index] = tmp;
_size++;
return true;
}
bool Remove(const K& key)
{
if (_htlist.empty())
return false;
int index = GetHashIndex(key);
Node* cur = _htlist[index];
Node* prev = NULL;
while (cur)
{
if (cur->_key == key)
{
if (prev == NULL)
_htlist[index] = cur->_next;
else
prev->_next = cur->_next;
delete cur;
cur = NULL;
_size--;
return true;
}
cur = cur->_next;
}
return false;
}
void Print() // 测试函数
{
for (size_t i = 0; i < _htlist.size(); i++)
{
Node* cur = _htlist[i];
cout << "the "<< i << "th " << "->";
while (cur)
{
cout << cur->_key << "->";
cur = cur->_next;
}
cout << "NULL" << endl;
}
}
protected:
int GetHashIndex(const K& key)
{
return key % _htlist.size();
}
void Swap(HashTableList<K, V, __HashList>& ht)
{
_htlist.swap(ht._htlist);
}
void _Check()
{
if (_htlist.empty() || (_size == _htlist.size())) // 载荷因子提升到1
{
size_t newsize = GetNewSize(_size);
vector<Node*> tmp;
tmp.resize(newsize);
// 拷贝
for (size_t i = 0; i < _htlist.size(); i++)
{
Node* cur = _htlist[i];
while (cur) // 哈希链处理
{
Node* next = cur->_next;
_htlist[i] = next;
size_t k = cur->_key;
cur->_next = tmp[k % newsize];
tmp[k % newsize] = cur;
cur = next;
}
}
_htlist.swap(tmp);
}
}
size_t GetNewSize(const size_t& sz)
{
const int _PrimeSize = 28;
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul,
786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (size_t i = 0; i < _PrimeSize;i++)
{
if (sz < _PrimeList[i])
return _PrimeList[i];
}
return _PrimeList[_PrimeSize - 1];
}
protected:
vector<Node*> _htlist;
size_t _size;
}; 关于整数的哈希算法就到这里,下面给出一张本篇文章的一张简图,便于大家理解HashTable。对于字符串哈希的处理,下一篇会进行介绍。
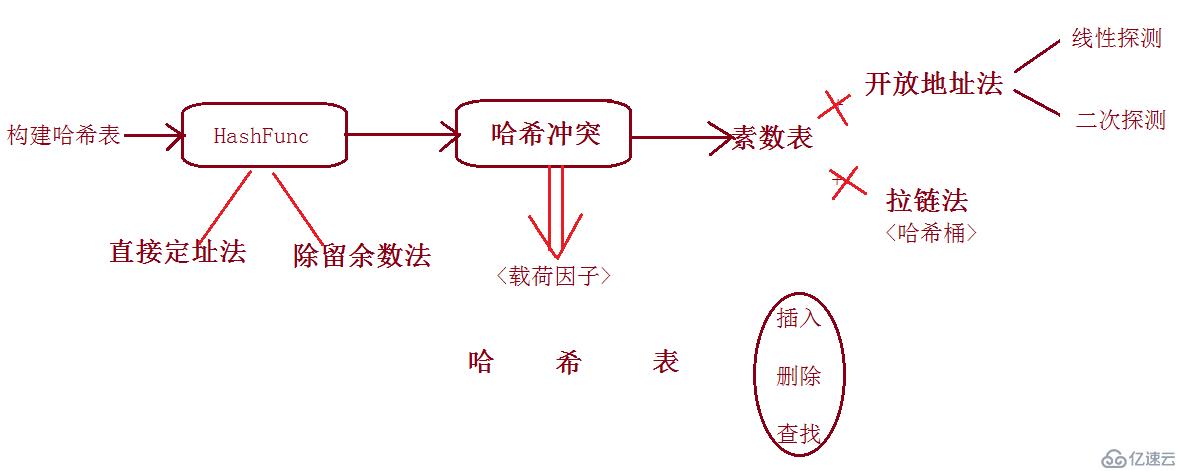
关于哈希算法就分享到这里了,希望以上内容可以对大家有一定的参考价值,可以学以致用。如果喜欢本篇文章,不妨把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



