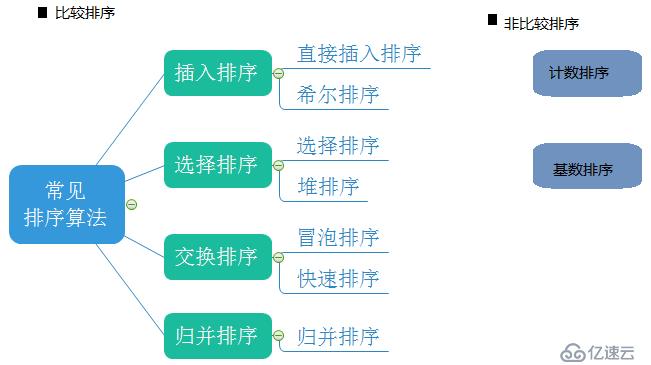
数据结构中的排序算法分为比较排序,非比较排序。比较排序有插入排序、选择排序、交换排序、归并排序,非比较排序有计数排序、基数排序。下面是排序的具体分类:
1.直接排序
主要思想:使用两个指针,让一个指针从开始,另一个指针指向前一个指针的+1位置,两个数据进行比较
void InsertSort(int* a, size_t size)
{
assert(a);
for (size_t i = 0; i < size - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0 && a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
a[end + 1] = tmp; //当进行到a[end]>tmp的时候,将tmp插入到a[end+1]的位置上
}
}2.希尔排序
主要思想:给定间距gap,将间距上的数据进行排序,然后将间距进行缩小,当间距为1时,就相当于进行直接插入排序,这就避免了,直接排序有序的情况,提高排序的效率
void shellSort(int* a, size_t size)
{
assert(a);
int gap = size;
while (gap > 1) //当gap为2或者1时,进入循环中gap = 1,相当于进行直接插入排序
{
gap = gap / 3 + 1;
for (size_t i = 0; i < size - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0 && a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
a[end + gap] = tmp;
}
}
}3.选择排序
主要思想: 每一次从所要排序的数据中选出最大的数据,放入到数组的最后位置上,用数组的下标来控制放置的位置,直到排好顺序
void selectSort(int* a, size_t size)
{
assert(a);
for (size_t i = 0; i < size - 1; i++)
{
int max = a[0];
int num = 0;
for (size_t j = 0; j < size - i; j++)
{
if (max < a[j])
{
max = a[j];
num = j;
}
}
swap(a[num], a[size - i - 1]);
}
}选择排序优化后的思想:每一次可以选两个数据,最大数据和最小数据,将最大数据从数组的最大位置开始放置,最小数据从数组的最小位置开始放置,能够提高排序的效率
void selectSort(int* a, size_t size)
{
int left = 0;
int right = size - 1;
while (left < right)
{
for (int i = left; i < right; i++)
{
int min = a[left];
int max = a[right];
if (a[i] < min)
{
min = a[i];
swap(a[i], a[left]);
}
if (a[i] > max)
{
max = a[i];
swap(a[i], a[right]);
}
}
++left;
--right;
}
}4.堆排序
主要思想:创建一个大堆进行排序,堆排序只能排序数组,通过数组的下表来计算数据在堆中的位置,将大堆的根节点与最后一个叶子节点进行交换,然后对堆中剩下的数据进行调整,直到再次成为大堆。
void AdjustDown(int* a, size_t root, size_t size)
{
assert(a);
size_t parent = root;
size_t child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] > a[child])
{
++child;
}
if (a[child] > a[parent])
{
swap(a[child], a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, size_t size)
{
for (int i = (size - 2) / 2; i >= 0; --i)
//从最后一个父亲节点开始建堆(使用i>=0时,必须使用int类型)
{
AdjustDown(a, i, size);
}
for (size_t i = 0; i < size; i++) //进行排序,最大的数往下放
{
swap(a[0], a[size - i - 1]);
AdjustDown(a, 0, size - i - 1);
}
}5.快速排序
方法一:
主要思想:先选定一个key值(一般是数组的头元素或者尾元素),这里选定数组的尾元素,给定两个指针begin和end,begin指针指向数组的头位置,end指针指向倒数第二个位置,begin指针找比key值大的数据,end指针找较key值小的数据,如果begin指针还没有和end相遇,则将a[begin]和a[end]数据进行交换。当begin和end指针相遇,则将key值和a[begin]进行交换。
int partSort(int* a, int left, int right)
{
assert(a);
int key = a[right]; //选最右端的数据作为key
int begin = left;
int end = right - 1;
while (begin < end)
{
while (begin < end && a[begin] <= key) //begin找比key大的数据
{
++begin;
}
while (begin < end && a[end] >= key) //end找比key小的数据
{
--end;
}
if (begin < end)
{
swap(a[begin], a[end]);
}
}
if (a[begin] > a[right]) //只有两个元素的情况
{
swap(a[begin], a[right]);
return begin;
}
else
{
return right;
}
return begin;
}
void QuickSort(int* a, int left, int right)
{
assert(a);
if (left >= right)
{
return;
}
int point = partSort(a, left, right);
QuickSort(a, left, point-1);
QuickSort(a, point+1, right);
}方法二:
主要思想:挖坑法实现,将最右边的数据用key进行保存,可以说这时候最后的位置相当于一个坑,能够对数据进行任意的更改,将左指针找到的较key值大的数据赋值到key的位置上,这时候左指针指向的位置可以形成一个坑,这时再用右指针找较key值小的数据,将其赋值到刚才的坑中,这时右指针指向的位置也就行成坑。最后当两个指针相遇时,将key值赋值到坑中,这时左边的数据都小于key值,右边的数据都大于key值。
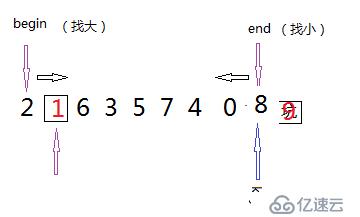
其中,若选取数组中最大或者最小的数据为key值,这是快速排序的最坏情况,利用三数取中的方法可以解决这种问题,取数组中头元素、尾元素、和中间元素的最中间大小的数据作为key值,就能够避免这样的情况。
//三数取中法
int GetMidIndex(int* a, int left, int right)
{
assert(a);
int mid = (left + right) / 2;
if (a[left] < a[right])
{
if (a[mid] < a[left]) //a[mid] < a[left] < a[right]
{
return left;
}
else if (a[mid] > a[right]) //a[left] < a[right] < a[mid]
{
return right;
}
else //a[left] < a[mid] < a[right]
{
return mid;
}
}
else
{
if (a[mid] < a[right]) //a[left] > a[right] > a[mid]
{
return right;
}
else if (a[mid] > a[left]) //a[right] < a[left] < a[mid]
{
return left;
}
else //a[right] < a[mid] < a[left]
{
return mid;
}
}
}
int partSort1(int* a, int left, int right)
{
int index = GetMidIndex(a, left, right);
swap(a[index], a[right]); //将中间的数据与最右边的数据进行交换,然后将最右边数据赋值给key
int key = a[right]; //首先将最右边的位置作为第一个坑
int begin = left;
int end = right;
while (begin < end)
{
while (begin < end && a[begin] <= key) //从左往右找较key大的数据
{
++begin;
}
a[end] = a[begin]; //将第一个坑进行覆盖,同时空出新的坑
while (begin < end && a[end] >= key) //从右往左查找较key小的数据
{
--end;
}
a[begin] = a[end]; //将第二个坑进行覆盖,同时空出新的坑
}
if (begin == end)
{
a[end] = key; //key现在的位置,左边的数据都较key值小,右边的数据豆角key值大
return begin;
}
}
void QuickSort1(int* a, int left, int right)
{
assert(a);
if (left > right)
{
return;
}
int ret = partSort1(a, left, right);
QuickSort1(a, left, ret - 1);
QuickSort1(a, ret + 1, right);
}方法三:
主要思想:选定最右边的数据为key,将cur指针指向数组的头元素,cur指针找较key值小的数据,prev指针指向cur-1的位置,当cur找到较小的数据,先进行prev++,若此时cur=prev,cur继续找较小的数据,直到cur!=prev,就将a[prev]和a[cur]进行交换,直到cur指向数组的倒数第二个元素,这时将key值和a[++prev]进行交换。
int partSort2(int* a, int left, int right)
{
int key = a[right];
int cur = left;
int prev = left - 1;
while (cur < right)
{
if (a[cur] < key && ++prev != cur)
{
swap(a[cur], a[prev]);
}
++cur;
}
swap(a[right], a[++prev]);
return prev;
}
void QuickSort2(int* a, int left, int right)
{
assert(a);
if (left > right)
{
return;
}
int ret = partSort2(a, left, right);
QuickSort2(a, left, ret - 1);
QuickSort2(a, ret + 1, right);
} 优化:当区间gap<13,采用直接排序效率会高于都采用快速排序,能够减少程序压栈的开销
//核心代码
void QuickSort1(int* a, int left, int right)
{
assert(a);
if (left > right)
{
return;
}
int gap = right - left + 1;
if (gap < 13)
{
InsertSort(a, gap);
}
int ret = partSort1(a, left, right);
QuickSort1(a, left, ret - 1);
QuickSort1(a, ret + 1, right);
}——如果不使用递归,那应该怎样实现快速排序算法呢?(利用栈进行保存左边界和右边界)
//核心代码
void QuickSort_NonR(int* a, int left, int right)
{
assert(a);
stack<int> s;
if (left < right) //当left < right证明需要排序的数据大于1
{
s.push(right);
s.push(left);
}
while (!s.empty())
{
left = s.top();
s.pop();
right = s.top();
s.pop();
if (right - left < 13)
{
InsertSort(a, right - left + 1);
}
else
{
int div = partSort1(a, left, right);
if (left < div - 1)
{
s.push(div - 1);
s.push(left);
}
if (div + 1 < right)
{
s.push(right);
s.push(div + 1);
}
}
}
}6.归并排序
主要思想:与合并两个有序数组算法相似,需要借助一块O(N)的空间,将一个数组中的元素分为两部分,若这两个部分都能够有序,则利用合并的思想进行合并,过程一直进行递归
void _Merge(int* a, int* tmp, int begin1, int end1, int begin2, int end2)
{
int index = begin1; //用来标记tmp数组的下标
while (begin1 <= end1 && begin2 <= end2)
//先判断begin1和begin2的大小,然后将小的数据从begin到end拷贝到tmp上,
//出循环的条件begin1>=end1 || begin2 >= end2
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
//将剩下的begin1或者begin2在进行拷贝
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
}
void _MergeSort(int* a, int* tmp, int left, int right)
{
if (left < right)
{
int mid = (right + left) / 2;
_MergeSort(a, tmp, left, mid);
_MergeSort(a, tmp, mid + 1, right);
_Merge(a, tmp, left, mid, mid + 1, right); //借助tmp进行排序
//将tmp上面排序后的数据再拷贝到上层的数组中
for (int i = left; i <= right; ++i)
{
a[i] = tmp[i];
}
}
}
void MergeSort(int* a, int size) //归并排序数组
{
assert(a);
int* tmp = new int[size]; //开辟N个空间
int left = 0;
int right = size - 1;
_MergeSort(a, tmp, left, right);
delete[] tmp;
} 上面主要介绍的为各个比较排序的算法实现,非比较排序(计数、基数)在下篇:“数据结构—各类‘排序算法’实现(下)”
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



