想入门一下Kafka的(装一下环境、看看Kafka一些概念啥的)。后来发现Kafka用到了ZooKeeper,而我又对ZooKeeper不了解,所以想先来学学什么是ZooKeeper,再去看看什么是Kafka。
ZooKeeper相信大家已经听过这个词了,不知道大家对他了解多少呢?我第一次听到ZooKeeper的时候是在学Eureka的时候,同样ZooKeeper也可以作为注册中心。
后面听到ZooKeeper的时候,是因为ZooKeeper可以作为分布式锁的一种实现。
直至在了解Kafka的时候,发现Kafka也需要依赖ZooKeeper。Kafka使用ZooKeeper管理自己的元数据配置。
这篇文章来写写我学习ZooKeeper的笔记,如果有错的地方希望大家可以在评论区指出。
从上面我们也可以发现,好像哪都有ZooKeeper的身影,那什么是ZooKeeper呢?我们先去官网看看介绍:

官网还有另一段话:
ZooKeeper: A Distributed Coordination Service for Distributed Applications
相比于官网的介绍,我其实更喜欢Wiki中对ZooKeeper的介绍:
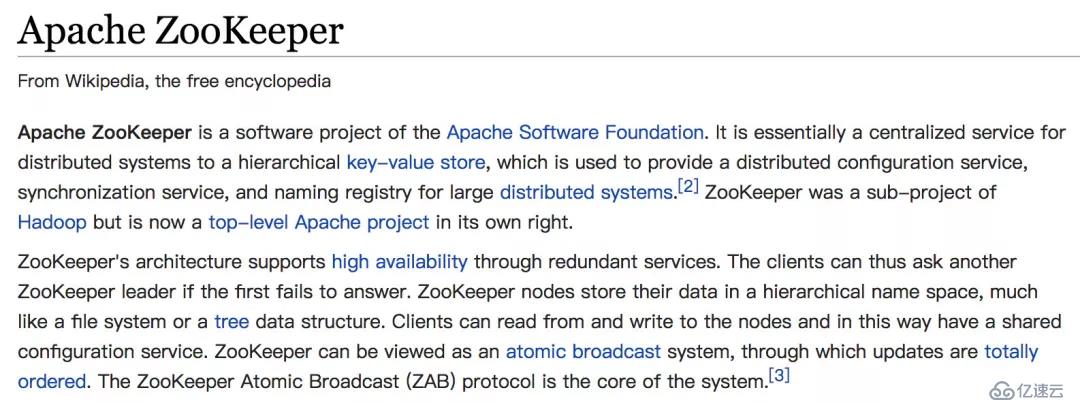
(留下不懂英语的泪水)
我简单概括一下:
ZooKeeper主要服务于分布式系统,可以用ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理。
从上面我们可以知道,可以用ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理。
统一配置管理、统一命名服务、分布式锁、集群管理每个具体的含义(后面会讲)那为什么ZooKeeper可以干那么多事?来看看ZooKeeper究竟是何方神物,在Wiki中其实也有提到:
ZooKeeper nodes store their data in a hierarchical name space, much like a file system or a tree data structure
ZooKeeper的数据结构,跟Unix文件系统非常类似,可以看做是一颗树,每个节点叫做ZNode。每一个节点可以通过路径来标识,结构图如下:
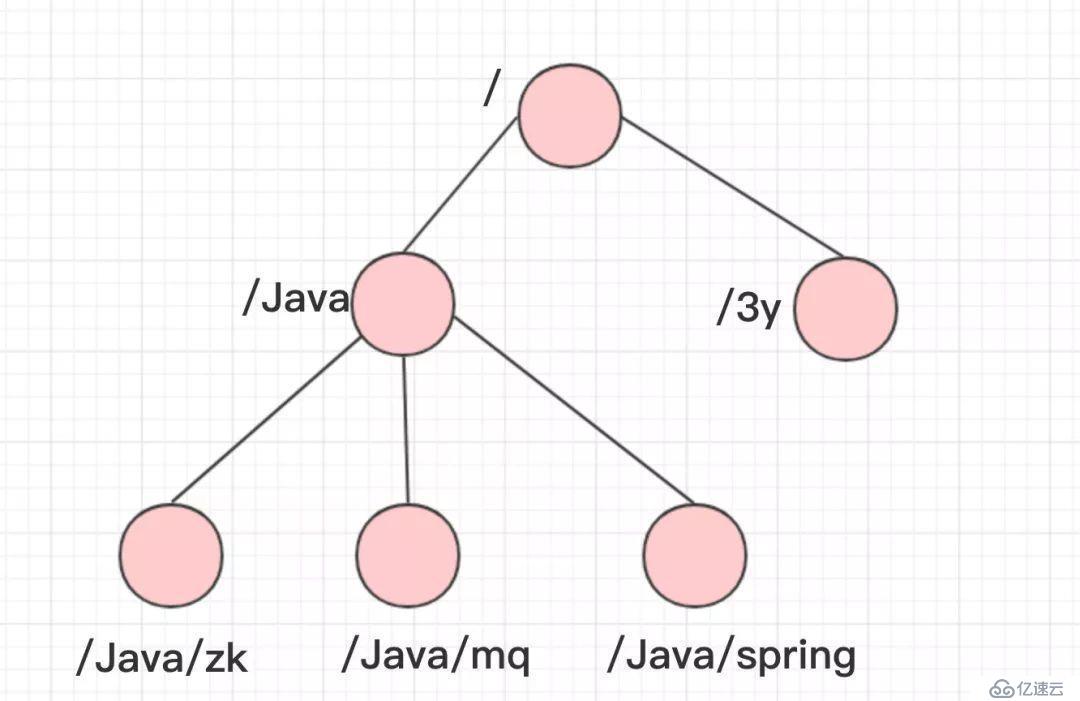
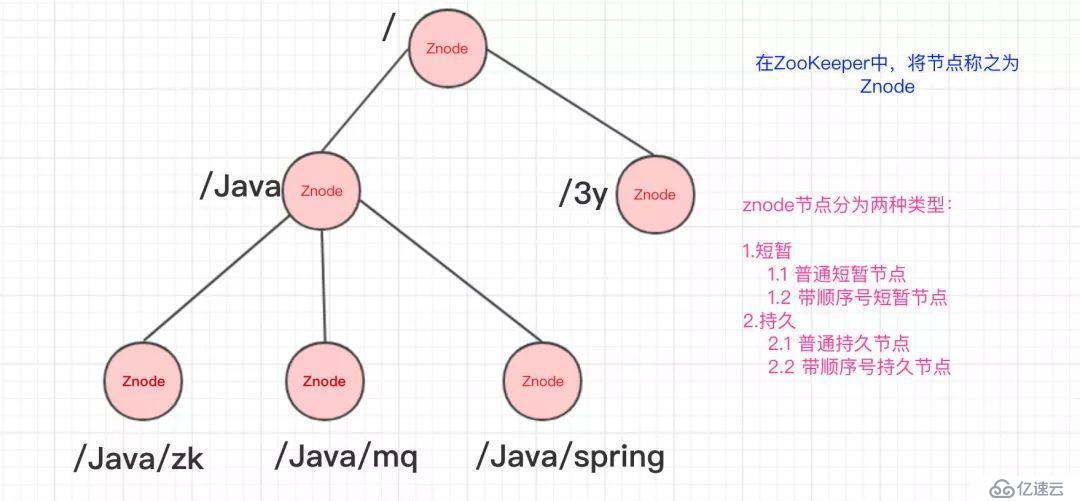
那ZooKeeper这颗"树"有什么特点呢??ZooKeeper的节点我们称之为Znode,Znode分为两种类型:
短暂/临时(Ephemeral):当客户端和服务端断开连接后,所创建的Znode(节点)会自动删除
ZooKeeper和Redis一样,也是C/S结构(分成客户端和服务端)
在上面我们已经简单知道了ZooKeeper的数据结构了,ZooKeeper还配合了监听器才能够做那么多事的。
常见的监听场景有以下两项:
监听Znode节点的数据变化
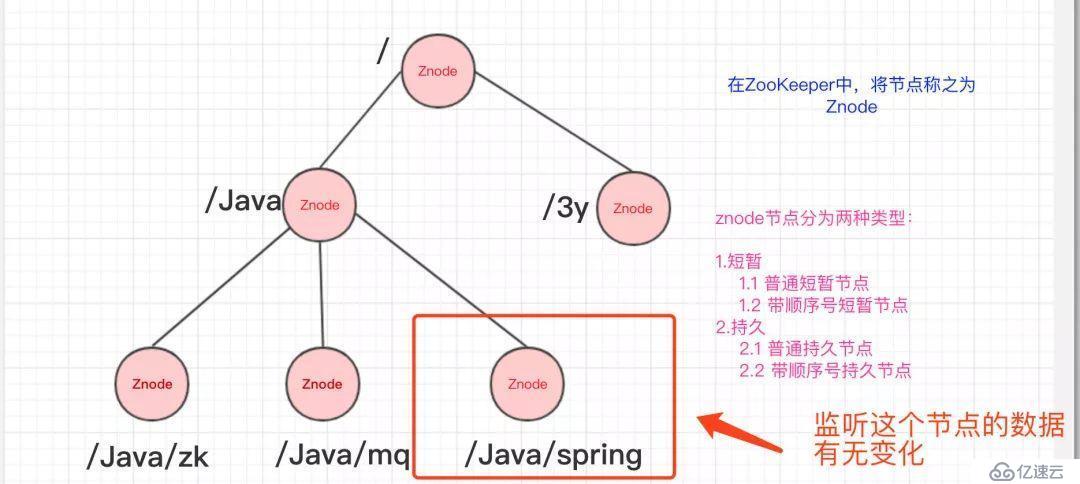
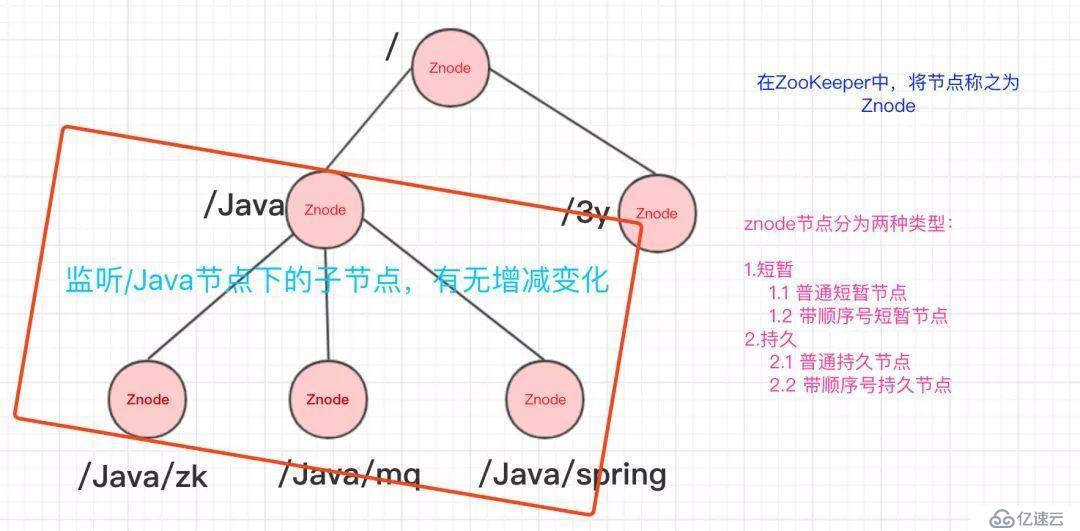
没错,通过监听+Znode节点(持久/短暂[临时]),ZooKeeper就可以玩出这么多花样了。
下面我们来看看用ZooKeeper怎么来做:统一配置管理、统一命名服务、分布式锁、集群管理。
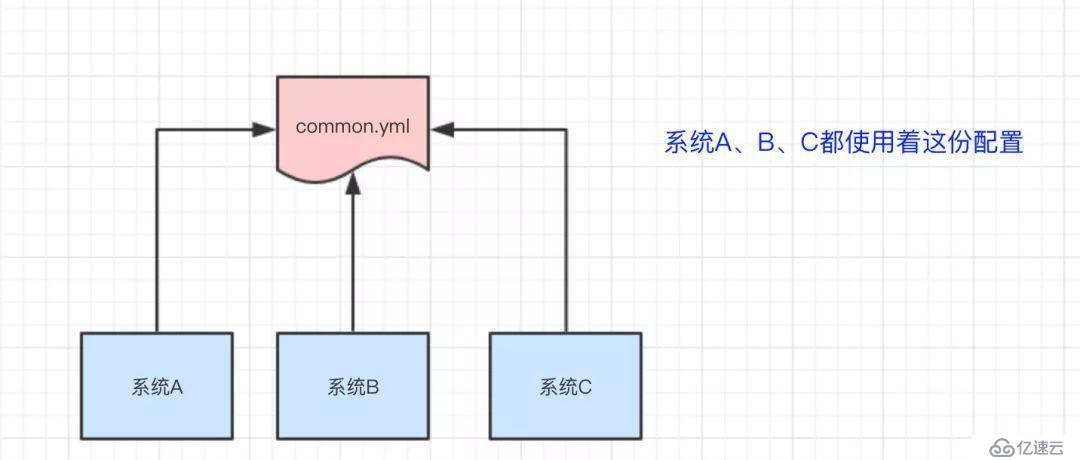
比如我们现在有三个系统A、B、C,他们有三份配置,分别是ASystem.yml、BSystem.yml、CSystem.yml,然后,这三份配置又非常类似,很多的配置项几乎都一样。
于是,我们希望把ASystem.yml、BSystem.yml、CSystem.yml相同的配置项抽取出来成一份公用的配置common.yml,并且即便common.yml改了,也不需要系统A、B、C重启。
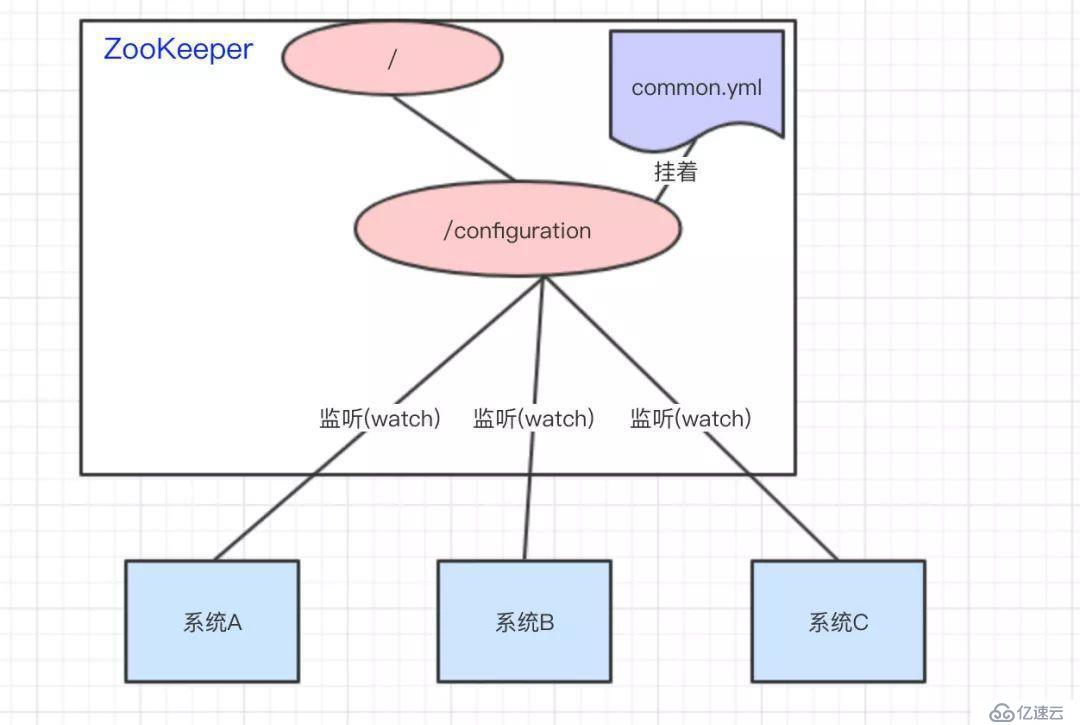
做法:我们可以将common.yml这份配置放在ZooKeeper的Znode节点中,系统A、B、C监听着这个Znode节点有无变更,如果变更了,及时响应。
参考资料:
基于zookeeper实现统一配置管理
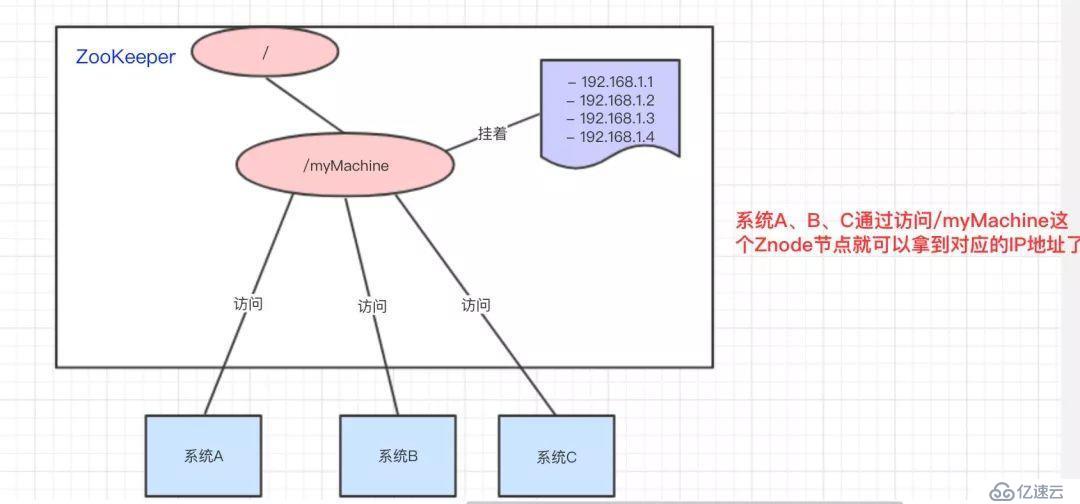
统一命名服务的理解其实跟域名一样,是我们为这某一部分的资源给它取一个名字,别人通过这个名字就可以拿到对应的资源。
比如说,现在我有一个域名www.java3y.com,但我这个域名下有多台机器:
192.168.1.1
192.168.1.2
192.168.1.3
别人访问www.java3y.com即可访问到我的机器,而不是通过IP去访问。
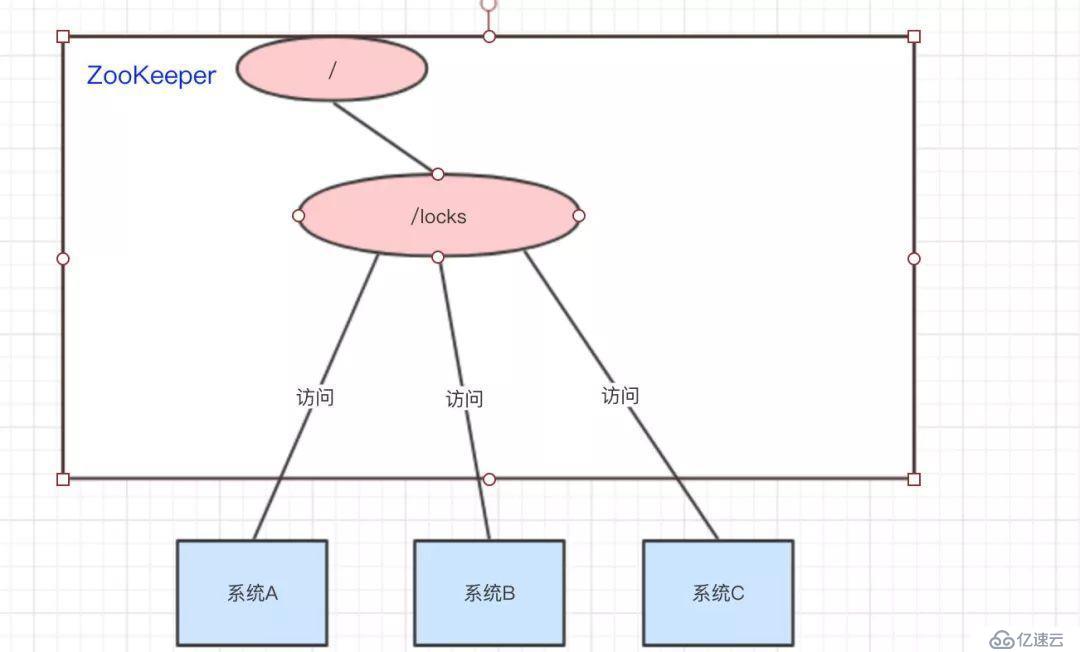
我们可以使用ZooKeeper来实现分布式锁,那是怎么做的呢??下面来看看:
系统A、B、C都去访问/locks节点
访问的时候会创建带顺序号的临时/短暂(EPHEMERAL_SEQUENTIAL)节点,比如,系统A创建了id_000000节点,系统B创建了id_000002节点,系统C创建了id_000001节点。
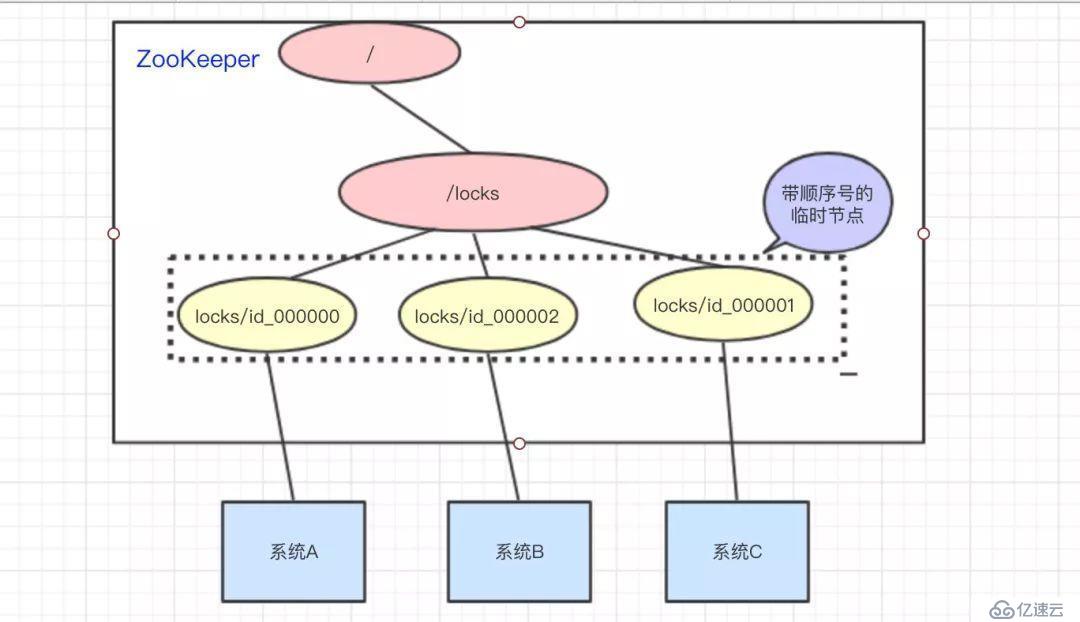
接着,拿到/locks节点下的所有子节点(id_000000,id_000001,id_000002),判断自己创建的是不是最小的那个节点
如果是,则拿到锁。
释放锁:执行完操作后,把创建的节点给删掉
举个例子:
系统A拿到/locks节点下的所有子节点,经过比较,发现自己(id_000000),是所有子节点最小的。所以得到锁
系统B拿到/locks节点下的所有子节点,经过比较,发现自己(id_000002),不是所有子节点最小的。所以监听比自己小1的节点id_000001的状态
系统C拿到/locks节点下的所有子节点,经过比较,发现自己(id_000001),不是所有子节点最小的。所以监听比自己小1的节点id_000000的状态
……
等到系统A执行完操作以后,将自己创建的节点删除(id_000000)。通过监听,系统C发现id_000000节点已经删除了,发现自己已经是最小的节点了,于是顺利拿到锁
经过上面几个例子,我相信大家也很容易想到ZooKeeper是怎么"感知"节点的动态新增或者删除的了。
还是以我们三个系统A、B、C为例,在ZooKeeper中创建临时节点即可:
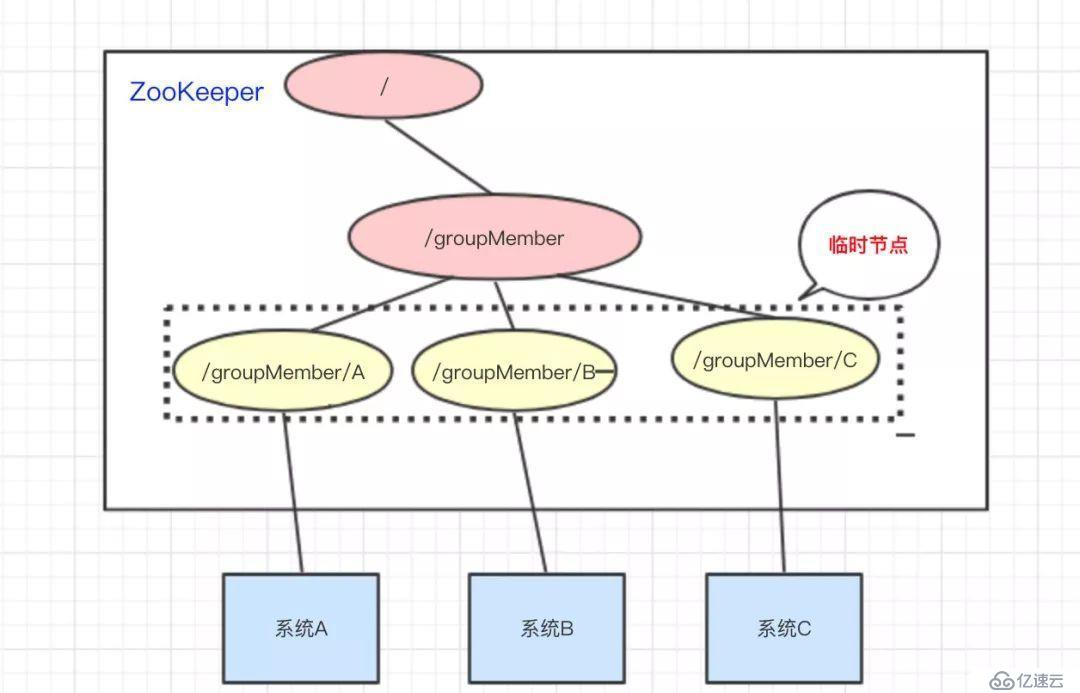
只要系统A挂了,那/groupMember/A这个节点就会删除,通过监听groupMember下的子节点,系统B和C就能够感知到系统A已经挂了。(新增也是同理)
除了能够感知节点的上下线变化,ZooKeeper还可以实现动态选举Master的功能。(如果集群是主从架构模式下)
原理也很简单,如果想要实现动态选举Master的功能,Znode节点的类型是带顺序号的临时节点(EPHEMERAL_SEQUENTIAL)就好了。
这篇文章主要讲解了ZooKeeper的入门相关的知识,ZooKeeper通过Znode的节点类型+监听机制就实现那么多好用的功能了!
当然了,ZooKeeper要考虑的事没那么简单的,后面有机会深入的话,我还会继续分享,希望这篇文章对大家有所帮助~
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





