矩阵我们在线性代数中所学的一种有力的工具,可用它可以处理很多的工程问题。今天,我们不讨论矩阵本身,而是研究如何来存储矩阵,使得矩阵的运算能够更加高效。
首先,我们了解矩阵中的一种特殊矩阵——>稀疏矩阵。那么什么是稀疏矩阵呢?如果在矩阵中,多数的元素为0,通常认为非零元素比上矩阵所有元素的值小于等于0.05时,则称此矩阵为稀疏矩阵(sparse matrix)。有时候为了节省存储空间,我们可以对这类矩阵进行压缩存储。所谓压缩存储是指对多个值相同的元只分配一个存储空间,对零元不分配空间。
了解了这些,我们如何来进行稀疏矩阵的压缩存储呢?按照压缩存储的概念,我们只存非零元素。但是,我们除了要存储它的值以外,我们还要记下其行和列的值。因此,我们可以定义一个三元组来确定每个非零元素。
三元组结构定义代码:
template<class T>
struct Triple //三元组
{
T _value;
size_t _row;
size_t _col;
Triple(const T& value=T(),size_t row=0,size_t col=0)
:_value(value)
,_row(row)
,_col(col)
{}
};转置运算是一种最简单的矩阵运算。对于一个m*n的矩阵,它的转置矩阵则是n*m的矩阵。显然,一个稀疏矩阵的转置仍是稀疏矩阵。
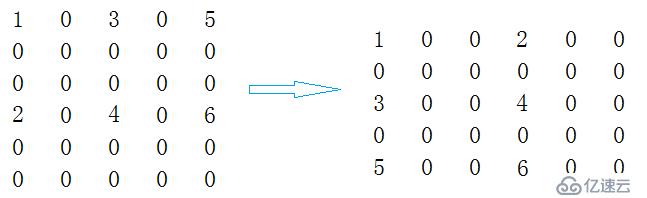
那么利用三元组的压缩存储我们应该如何来进行转置呢?
First>>将矩阵的行列值进行交换。
Second>>将三元组中的i和j的值进行交换。
Third>>重新排列三元组的位置即可。即按照原始矩阵的列序进行转置,对原始三元组进行扫描一遍。
矩阵定义及转置:
template<class T>
class SparseMatrix
{
public:
SparseMatrix(T* a,size_t m,size_t n,const T& invalid)
:_rowsize(m)
,_colsize(n)
,_invalid(invalid)
{
for(size_t i=0; i<m; i++)
{
for(size_t j=0; j<n; j++)
{
if(a[i*n+j]!=invalid)
{
_a.push_back(Triple<T>(a[i*n+j],i,j));
}
}
}
}
SparseMatrix()
:_rowsize(0)
,_colsize(0)
{}
void Display()//打印矩阵
{
size_t index=0;
for(size_t i=0; i<_rowsize; i++)
{
for(size_t j=0; j<_colsize; j++)
{
if(index<_a.size() && _a[index]._row==i && _a[index]._col==j)
{
cout<<_a[index]._value<<" ";
index++;
}
else
{
cout<<_invalid<<" ";
}
}
cout<<endl;
}
}
SparseMatrix<T> Transport()
{
SparseMatrix<T> tmp;
tmp._colsize=_rowsize;
tmp._rowsize=_colsize;
tmp._invalid=_invalid;
for(size_t i=0; i<_colsize; i++) //遍历每一列
{
size_t index=0;
while(index<_a.size()) //遍历原始三元组
{
if(_a[index]._col==i) //若两者相等
{
Triple<T> t( _a[index]._value,_a[index]._col, _a[index]._row);
tmp._a.push_back(t);;//存入新的三元组
/*Triple<T> tp;
tp._col = _a[index]._row;
tp._row = _a[index]._col;
tp._value = _a[index]._value;
tmp._a.push_back(tp);*/
}
index++;
}
}
return tmp;
}
protected:
vector<Triple<T> > _a;
size_t _rowsize;
size_t _colsize;
T _invalid;
};上述算法的时间复杂度是O(矩阵的列数*非零元素个数)。如果元素很多就会浪费很多的时间。那么,可不可以进行优化呢?下面我们,采取一种以空间换时间的算法,也就是通常所说的快速转置。它的算法是如何实现的呢?
我们可以采用两个数组来进行存放每一列中非零元素的个数以及每一列第一个非零元素的位置。
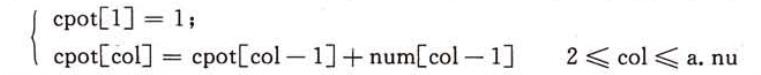
这样就可以得到转置后的矩阵的三元组。
快速转置算法代码实现:
SparseMatrix<T> FastTransport()
{
SparseMatrix<T> tmp;
tmp._colsize=_rowsize;
tmp._rowsize=_colsize;
tmp._invalid=_invalid;
int *rowcounts=new int[tmp._rowsize];//每一列中非零元素的个数
int *rowstart=new int[tmp._rowsize];//每一列第一个非零元素在三元组中的位置
memset(rowcounts,0,(sizeof(int)* _colsize));//初始化
memset(rowstart,0,(sizeof(int)* _colsize));
size_t index=0;
while(index<_a.size())
{
rowcounts[_a[index]._col]++; //遍历将每一列的非零元素个数存入rowcounts
++index;
}
rowstart[0]=0;
for(size_t i=1; i<_colsize; i++)
{
rowstart[i]=rowstart[i-1]+rowcounts[i-1]; //将每一列非零元素的起始位置存入rowsart
}
index=0;
tmp._a.resize(_a.size());
while(index<_a.size())
{
size_t rowIndex=_a[index]._col;
int &start=rowstart[rowIndex];
Triple<T> tp;
tp._col = _a[index]._row;
tp._row = _a[index]._col;
tp._value = _a[index]._value;
tmp._a[start++]=tp;
index++;
}
return tmp;
}这样的时间复杂度就是O(列数+非零元素个数)。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





