在Java中,虚拟机将运行时区域分成6种,如图:
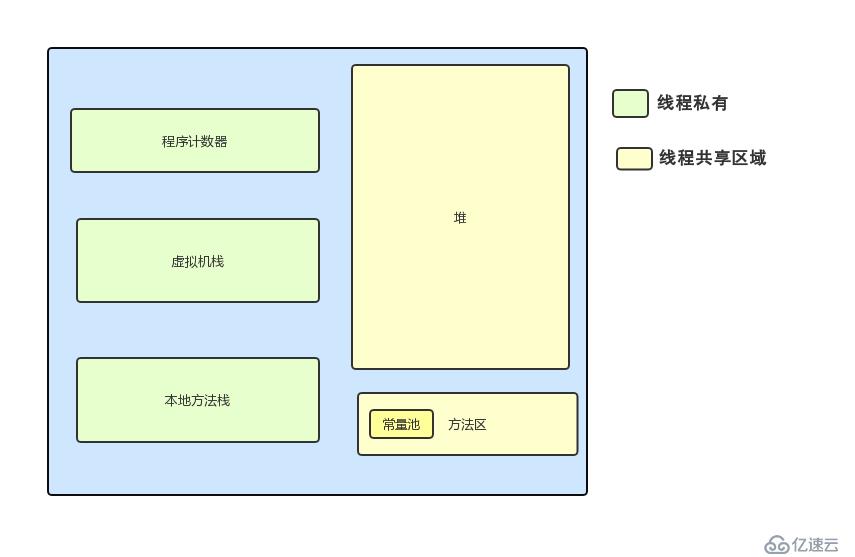
方法区:储存符号引用、被JVM加载的类信息、静态变量的地方。在Java8之后方法区被移除,使用元空间来存放类信息,常量池和其他东西被移到堆中(其实在7的时候常量池和静态变量就已经被移到堆中),不再有永久代一说。删除的原因大致如下:
由于类和方法的信息难以确定,不好设定大小,太大则影响年老代,太小容易内存溢出。
GC不好处理,回收效率低下,调优困难。
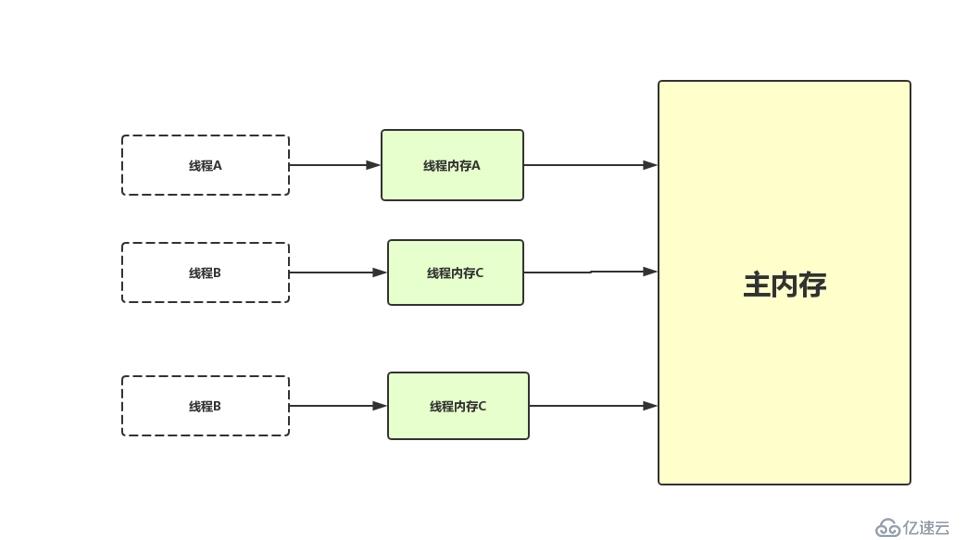
在上面的6种类型中,前三种是线程私有的,也就是说里面存放的值其他线程是看不到的,而后面三种(真正意义上讲只有堆一种)是线程之间共享的,这里面的变量对于各个线程都是可见的。如下图所示,前三种存放在线程内存中,大家都是相互独立的,而主内存可以理解为堆内存(实际上只是堆内存中的对象实例数据部分,其他例如对象头和对象的填充数据并不算入在内),为线程之间共享:
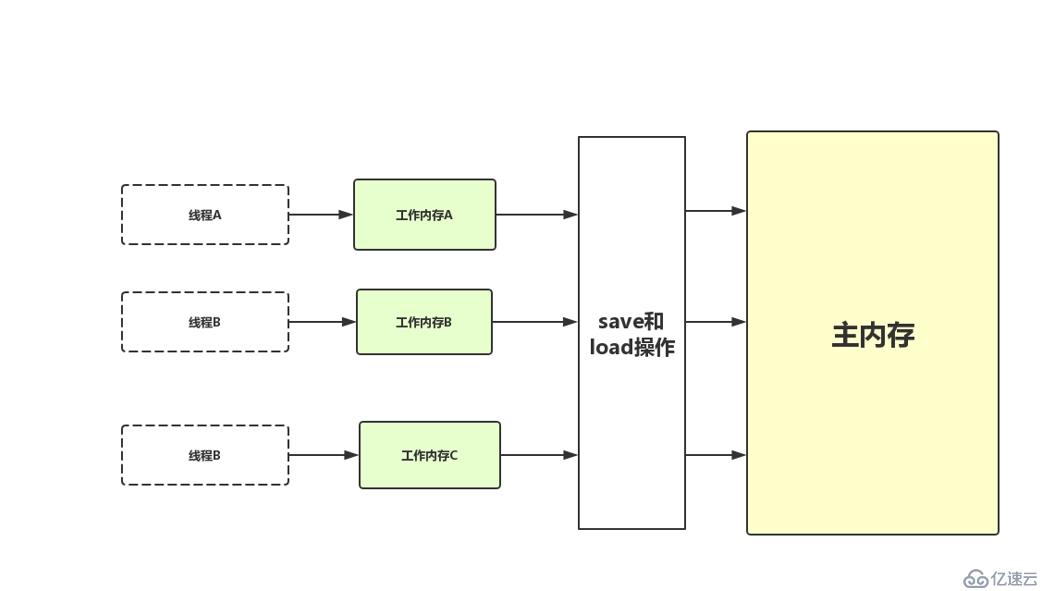
这里的变量指的是可以放在堆中的变量,其他例如局部变量、方法参数这些并不算入在内。线程内存跟主内存变量之间的交互是非常重要的,Java虚拟机把这些交互规范为以下8种操作,每一种都是原子性的(非volatile修饰的Double和Long除外)操作。
可能有人会不理解read和load、store和write的区别,觉得这两对的操作类似,可以把其当做一个是申请操作,另一个是审核通过(允许赋值)。例如:线程内存A向主内存提交了变更变量的申请(store操作),主内存通过之后修改变量的值(write操作)。如下图:
参照《深入理解Java虚拟机》
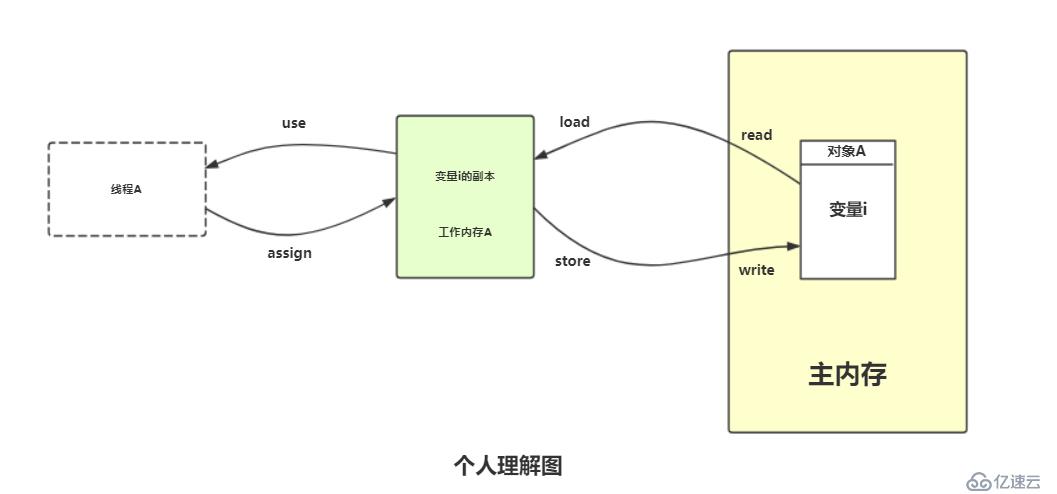
对于普通的变量来说(非volatile修饰的变量),虚拟机要求read、load有相对顺序即可,例如从主内存读取i、j两个变量,可能的操作是read i=>read j=>load j=> load i,并不一定是连续的。此外虚拟机还为这8种操作定制了操作的规则:
对于关键字volatile,大家都知道其一般作为并发的轻量级关键字,并且具有两个重要的语义:
这两个语义都是因为JMM对于volatile关键字修饰的变量会有特殊的规则:
- 在对变量执行use操作之前,其前一步操作必须为对该变量的load操作;在对变量执行load操作之前,其后一步操作必须为该变量的use操作。也就是说,使用volatile修饰的变量其read、load、use都是连续出现的,所以每次使用变量的时候都要从主内存读取最新的变量值,替换私有内存的变量副本值(如果不同的话)。
- 在对变量执行assign操作之前,其后一步操作必须为store;在对变量执行store之前,其前一步必须为对相同变量的assign操作。也就是说,其对同一变量的assign、store、write操作都是连续出现的,所以每次对变量的改变都会立马同步到主内存中。
- 在主内存中有变量a、b,动作A为当前线程对变量a的use或者assign操作,动作B为与动作A对应load或store操作,动作C为与动作B对应的read或write操作;动作D为当前线程对变量b的use或assign操作,动作E为与D对应的load或store操作,动作F为与动作E对应的read或write操作;如果动作A先于动作D,那么动作C要先于动作F。也就是说,如果当前线程对变量a执行的use或assign操作在对变量buse或assign之前执行的话,那么当前线程对变量a的read或write操作肯定要在对变量b的read或write操作之前执行。
从上面volatile的特殊规则中,我们可以知道1、2条其实就是volatile内存可见性的语义,第三条就是禁止指令重排序的语义。另外还有其他的一些特殊规则,例如对于非volatile修饰的double或者long这两个64位的数据类型中,虚拟机允许对其当做两次32位的操作来进行,也就是说可以分解成非原子性的两个操作,但是这种可能性出现的情况也相当的小。因为Java内存模型虽然允许这样子做,但却“强烈建议”虚拟机选择实现这两种类型操作的原子性,所以平时不会出现读到“半个变量”的情况。
虽然volatile修饰的变量可以强制刷新内存,但是其并不具备原子性,稍加思考就可以理解,虽然其要求对变量的(read、load、use)、(assign、store、write)必须是连续出现,即以组的形式出现,但是这两组操作还是分开的。比如说,两个线程同时完成了第一组操作(read、load、use),但是还没进行第二组操作(assign、store、write),此时是没错的,然后两个线程开始第二组操作,这样最终其中一个线程的操作会被覆盖掉,导致数据的不准确。如下面代码:
public class TestForVolatile {
public static volatile int i = 0;
public static void main(String[] args) throws InterruptedException {
// 创建四个线程,每个线程对i执行一定次数的自增操作
new Thread(() -> {
int k = 0;
while (k++ < 10000) {
i++;
}
System.err.println("线程" + Thread.currentThread().getName() + "执行完毕");
}).start();
new Thread(() -> {
int k = 0;
while (k++ < 10000) {
i++;
}
System.err.println("线程" + Thread.currentThread().getName() + "执行完毕");
}).start();
new Thread(() -> {
int k = 0;
while (k++ < 10000) {
i++;
}
System.err.println("线程" + Thread.currentThread().getName() + "执行完毕");
}).start();
new Thread(() -> {
int k = 0;
while (k++ < 10000) {
i++;
}
System.err.println("线程" + Thread.currentThread().getName() + "执行完毕");
}).start();
// 睡眠一定时间确保四个线程全部执行完毕
Thread.sleep(1000);
// 最终结果为33555,没有预期的4W
System.out.println(i);
}
}
结果图:
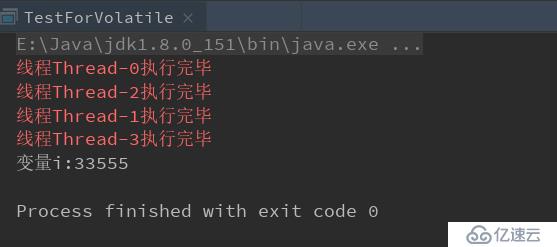
解释一下:因为i++操作其实为i = i + 1,假设在主内存i = 99的时候同时有两个线程完成了第一组操作(read、load、use),也就是完成了等号后面变量i的读取操作,这时候是没问题的,然后进行运算,都得出i+1=100的结果,接着对变量i进行赋值操作,这就开始第二组操作(assign、store、write),是不是同时赋值的无所谓,这样一来,两个线程都会以i = 100把值写到主内存中,也就是说,其中一个线程的操作结果会被覆盖,相当于无效操作,这就导致上面程序最终结果的不准确。
如果要保证原子性的话可以使用synchronize关键字,其可以保证原子性和内存可见性(但是不具备有禁止指令重排序的语义,这也是为什么double-check的单例模式中,实例要用volatile修饰的原因);当然你也可以使用JUC包的原子类AtomicInteger之类的。
如果单靠volatile和synchronized来维持程序的有序性的话,那么难免会变得有些繁琐。然而大部分时候我们并不需要这样做,因为Java中有一个“先行发生原则”:如果操作A先行发生于操作B,那么进行B操作之前A操作的变化都能被B操作观察到,也就是说B能看到A对变量进行的修改。 这里的先后指的是执行顺序的先后,与时间无关。例如在下面伪代码中:
// 在线程A执行,定为A操作
i = 0;
// 线程B执行,定义为B操作
j = i;
// 线程C执行,定义为C操作
i = 1;假设A操作先于B操作发生,暂时忽略C操作,那么最终得到的结果必定是i = j = 1;但是如果此时加入C操作,并且跟A、B操作没有确定先行发生关系,那么最终的结果就变成了不确定,因为C可能在B之前执行也可能在B之后执行,所以此时就会出现数据不准确的情况。如果一开始没有A操作先行于B操作这个前提的话,那么就算没有C操作,结果也是不确定的。
当然,符合先行发生原则的并不一定按照这个规则来执行,只有在操作之间会有依赖的时候(即下一个操作用到上个操作的变量),此时的先行发生原则才一定适用。例如在下面的伪代码中,虽然符合先行发生原则,但是也不保证能有序执行。
// 同一线程执行以下操作
// A操作
int i = 0;
// B操作
int j = 1;这里完全符合程序次序规则(先行发生原则的一种),但是两个操作之间并没有依赖,所以虚拟机完全可以对其进行重排序,使得B操作在A操作之前执行,当然这对程序的正确性并没有影响。
那么该如何判断是否符合先行发生原则呢?就连前面的例子都是通过假设来得出先行发生的。莫慌,Java内存模型为我们提供一些规则,只要符合这些规则之一,那就符合先行发生原则。可以类比为先行发生原则为接口,下面的规则则为实现此接口的实现类。
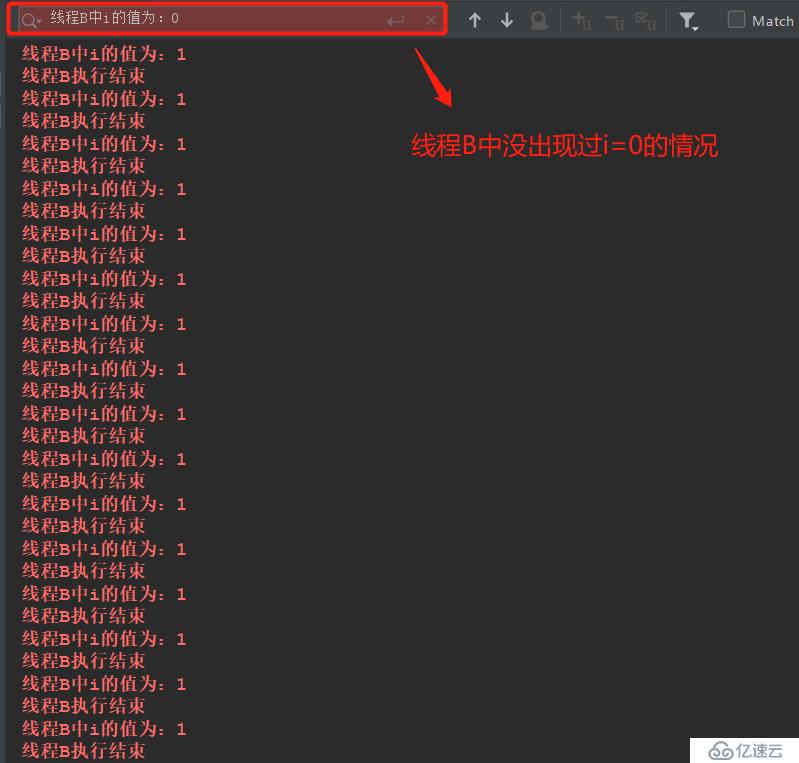
线程启动规则:一个线程的start()方法先行发生于该线程的每一个动作,也就是说线程的start()方法要先于该线程的run()方法中的任何操作。如下面例子,我在线程A中改变了共享变量i的值,然后在启动B线程,B线程中run方法是读取并打印i的值,执行1W次,最终的结果读取到的都为1:
public static int i = 0;
public static void main(String[] args) {
for (int k = 0; k < 10000; k++) testThread();
}
public static void testThread() {
Thread threadB = new Thread(() -> {
System.err.println("线程B中i的值为:" + i);
System.err.println("线程B执行结束");
});
new Thread(() -> {
i = 1;
// 在修改了共享变量i的值后,启动线程B
threadB.start();
System.err.println("线程A中执行完之后i的值为:" + i);
}).start();
} 结果图:
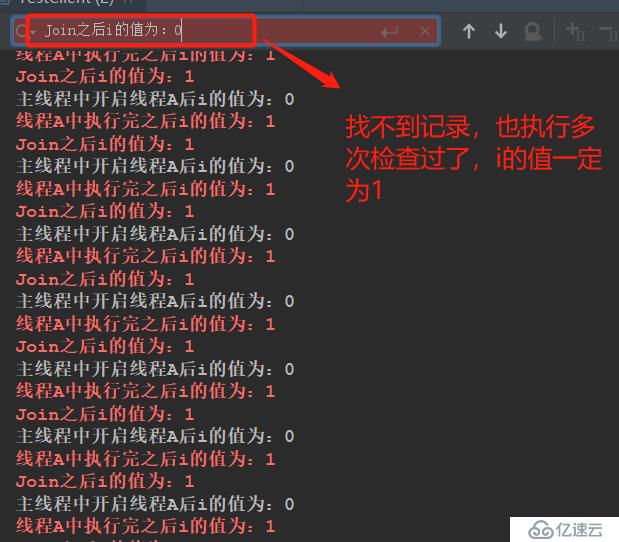
线程终止规则:线程的所有操作先行于该线程的终止检测,也就是先于join()方法执行。如下面代码中,我在A线程对共享变量i执行100W的自增,再执行100W-1的自减,执行1000次左右,最终join的所有结果都一定是1。
public static int i = 0;
public static void main(String[] args) throws InterruptedException {
// 执行1000次
for (int k = 0; k < 1000; k++) {
i = 0;
testThread();
}
}
public static void testThread() throws InterruptedException {
Thread threadA = new Thread(() -> {
int k = 0;
while (k++ < 100 * 100 * 100) {
i++;
}
while (--k > 1) {
i--;
}
System.err.println("线程A中执行完之后i的值为:" + i);
});
threadA.start();
// 加上下面这段代码的话,join之前读到的i可能为0也可能大于0(不一定是1),原因是变量i主内存的read和write操作没有固定顺序
// TimeUnit.NANOSECONDS.sleep(1);
System.out.println("主线程中开启线程A后i的值为:" + i);
// 线程A终止
threadA.join();
// join之后的结果一定为1
System.err.println("Join之后i的值为:" + i);
}结果图:
这8种就是Java提供的不需要任何同步器的自然规则了,只要符合在8条之一,那么就符合先行发生原则;反之,则不然。可以通过下面的例子理解:
// 对象中有一个变量i
private int i = 0;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
// 在线程A执行set操作A
setI(1);
// 在线程B执行相同对象的get操作B
int j = getI();我们假设在时间上A操作先执行,然后再接着执行B操作,那么B得到的i是多少呢?
我们将上面的规则一个个的往里套,不同线程,程序次序规则OUT;没有加锁和volatile关键字,管程锁定和volatile变量规则OUT;关于线程的三个规则和对象终止规则也不符合,OUT;最后一个更不用提,OUT;综上,这个操作并不符合先行发生原则,所以这个操作是没法保证的,也就是说B得到的变量i为1为0都有可能,即是线程不安全的。所以判断线程是否安全的依据是先行发生原则,跟时间顺序并没有太大的关系。
像上面这种情况要修正的话,使其符合其中一条规则即可,例如加上volatile关键字或者加锁(同一把锁)都可以解决这个问题。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



