在项目中为什么要使用消息队列
消息队列使用场景主要有三个:
解耦,异步,削峰
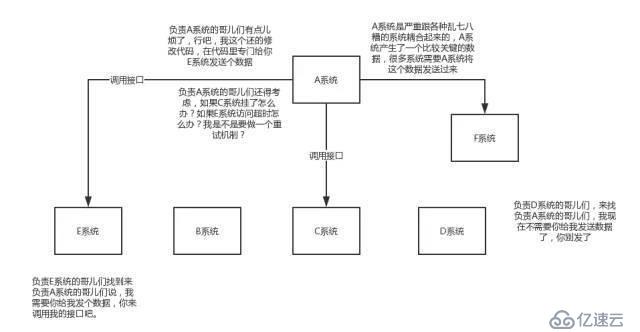
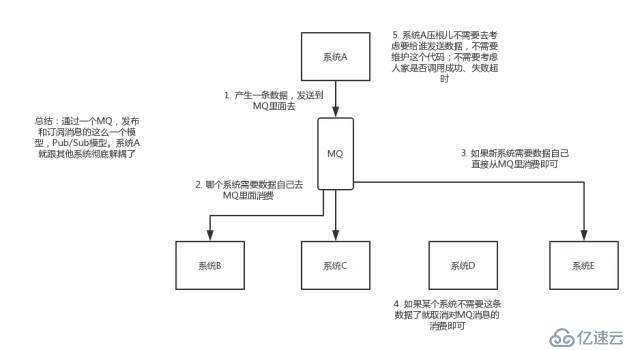
如上图所示,可能存在某一个系统产生关键数据,所有系统都需要其进行提供数据,导致A系统与要提供数据系统产生耦合,系统拓展,其他系统的需求修改都会导致A系统产生修改。
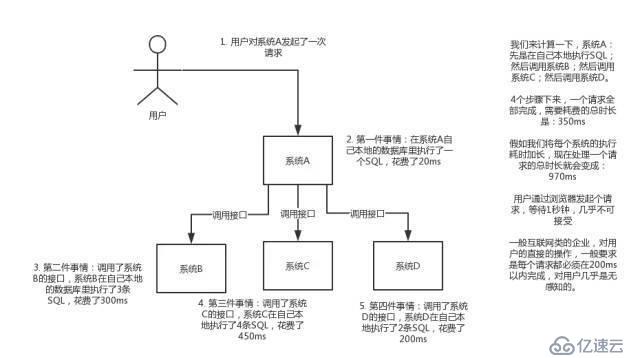
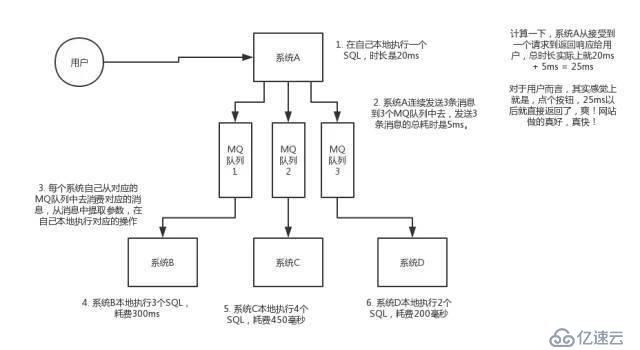
如果用户一个点击,需要几个系统间的一系列反应,同时每一个系统肯都存在一定的耗时,那么可以使用mq对不同的系统进行发送命令,进行异步操作。
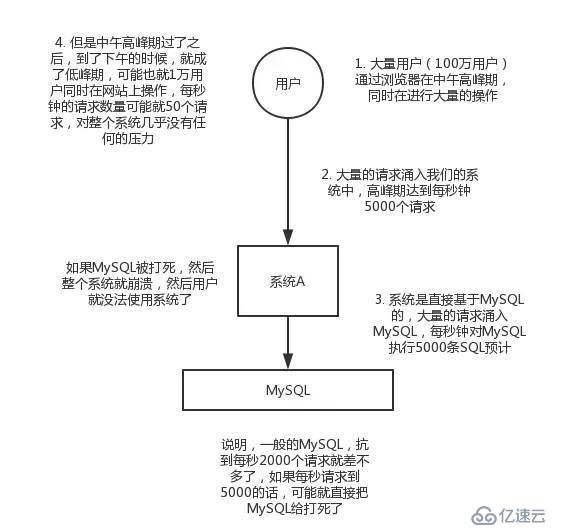
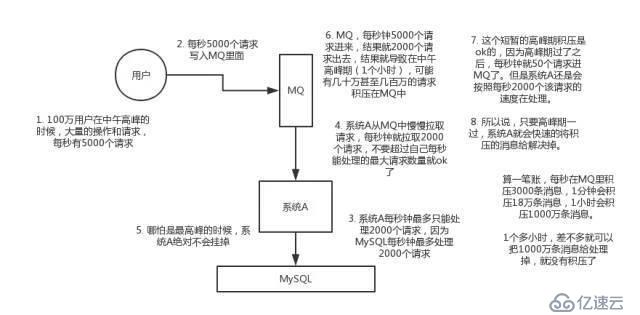
主要是如果存在用户使用的高峰期,例如存在大量的请求访问数据库(mysql每秒2000个请求),超过就会卡死,我们使用MQ作为类似于缓冲区的作用,高峰取时在MQ中进行大量请求积压,处理器按照自己的最大处理能力取请求量,等请求期过后再把它消耗掉。
1、系统的可用性降低:很多服务都依赖于MQ,一旦MQ故障,系统崩溃。
2、系统变的复杂,序列考虑问题变多:发送消息重复,多了,乱序,丢掉。
3.、一致性问题:系统A给BCD发送,只有都成功才返回成功,结果BC成功,但是D失败,但是返回页面结果是成功。
ActiveMQ
最早大家都用ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,单机吞吐量,万级,吞吐量比RocketMQ和Kafka要低了一个数量级,响应为ms级别,有较低的概率丢失数据。
RabbitMQ
单机吞吐率万级,吞吐量比RocketMQ和Kafka要低了一个数量级,但是适合于中小型企业,因为自带了友好的监控和维护界面,社区相对比较活跃,几乎每个月都发布几个版本分,在国内一些互联网公司近几年用rabbitmq也比较多一些,但是问题也是显而易见的,RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重,同时语言在国内很少有人会。
RocketMQ
单机吞吐量10万级,RocketMQ也是可以支撑高吞吐的一种MQ,topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降,这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic,可用性非常高,分布式架构,在阿里大规模应用过,有阿里品牌保障,日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,源码是JAVA。
Kafka
单机吞吐量10万级别,这是kafka最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景。topic从几十个到几百个的时候,吞吐量会大幅度下降。
所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源,可用性非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



