文章首发于微信公众号《程序员果果》
地址:https://mp.weixin.qq.com/s/8VM-c_UkxYcVw2Itiapw4w

从图中我们很容器看出,容器技术资源占用比较少,由于虚拟机需要模拟硬件的行为,对CUP和内存的损耗比较大。所以同样配置的服务器,容器技术就有以下优点:
那既然容器有这些优点,为什么直到Docker的出现,才真正的被关注呢?一个重要原因就是容器技术的复杂性。容器本身就很复杂,他依赖于Linux内核的很多特性,而且他不易安装,也不易于管理和实现自动化。而Docker就是为了改变这一切而产生的。
Docker 包含了一下几个重要主要部分:

docker的镜像是一个层叠的只读文件系统,最低端是一个引导文件系统(即bootfs),第二层是root文件系统(即rootfs),它位于bootfs之上,可以是一种或多种操作系统,比如ubuntu或者centos。在docker中,root文件系统永远只能是只读状态,并且docker运用联合加载技术又会在root文件系统之上加载更多的只读文件系统,联合加载指的是一次加载多个文件系统,但是在外面看起来只能看到一个文件系统,联合加载会将各层文件系统叠加到一起,这样最终的文件系统会包含所有的底层文件和目录,docker将这样的文件系统称为镜像。
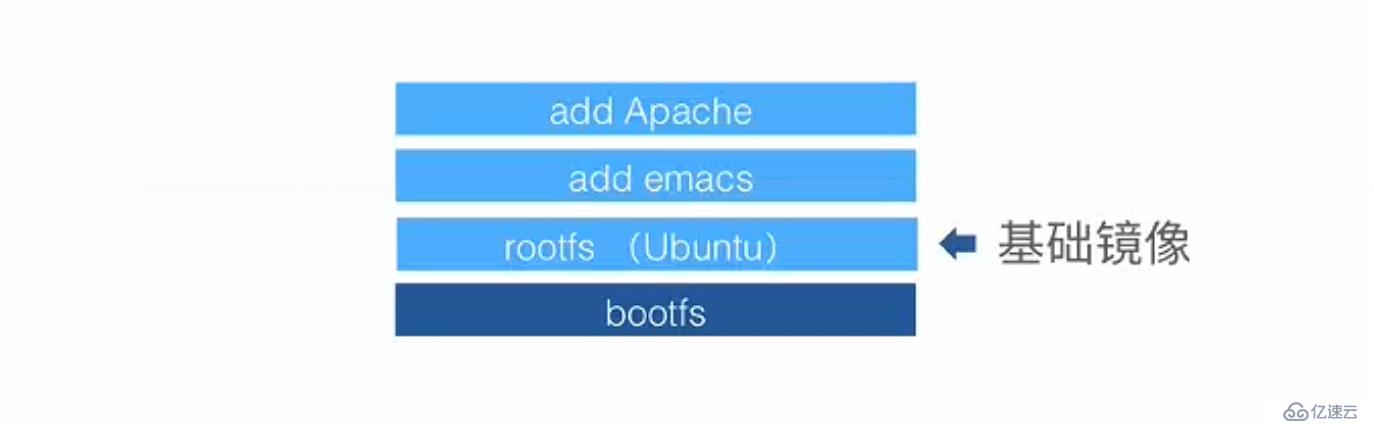
当一个容器启动时,docker会在该镜像的最顶层加载一个读写文件系统,也就是一个可写的文件层,我们在docker运行的程序,就是在这个层中进行执行的,当docker第一次启动一个容器时,初始的读写层是空的,当文件系统发生变化时,这些变化都会应用到这一层上,比如像修改一个文件,该文件首先会从读写层下面的只读层复制到该读写层,该文件的只读版本依然存在,但是已经被读写层中的该文件副本所隐藏,这就是docker的一个重要技术:写时复制(copy on write)。每个只读镜像层都是只读的,永远不会变化,当创建一个新容器时,docker会构建出一个镜像栈,如下图所示:

Docker依赖于Linux内核的两个重要特性:
很多编程语言都包含了“命名空间”的概念,我们可以认为“命名空间”是一种“封装”的概念, 而“封装”本身实际上实现的是代码的隔离。而在操作系统中,命名空间提供的是系统资源的隔离,而系统资源包括了进程、网络、文件系统等。
我们从Docker公开的文档来看,它使用了5种命名空间:
那么,这些隔离的资源,是如何被管理起来的呢?这就需要用到——Control groups(cgroup)控制组了。
Control groups是Linux内核提供的,一种可以限制、记录、隔离进程组所使用的物理资源的机制。
最初是由google工程师提出,并且在2007年时被Linux的内核的2.6.24版本引进。可以说,Control groups就是为容器而生的,没有Control groups就没有容器技术的今天。
Control groups提供了以下功能:
资源限制:例如,memory(内存)子系统可以为进程组设定一个内存使用的上限,一旦进程组使用的内存达到了限额,该进程组再发出内存申请时,就会发出“out of memory”(内存溢出)的警告。
优先级设定:它可以设定哪些进程组可以使用更大的CPU或者磁盘IO的资源。
资源计量:它可以计算进程组使用了多少系统资源。尤其是在计费系统中,这一点十分重要。
到这里我们了解了Namespace和CGroup的概念和职能,而这两个特性带给了Docker哪些能力呢?如下:
文件系统隔离:首先是文件系统的隔离,每个Docker的容器,都可以拥有自己的root文件系统。
进程隔离:每个容器都运行在自己的进程环境中。
网络隔离:容器间的虚拟网络接口和IP地址都是分开的。
欢迎关注我的公众号《程序员果果》,关注有惊喜~~
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





