许多网站在进行某些操作前会要求输入验证码以此来抵御爬虫和***。此篇主要讲述如何通过代码来识别一些常见的验证码。以此探究图片识别的过程以及如何避免生成容易被识别的验证码。
图片识别的过程
取样本
清洗区分样本
提取样本特征
Java有丰富的图片处理类,本次操作使用java语言。
一、取目标网站的验证码样本。在web页面中查看验证码请求的地址。通过http请求批量获取验证码并保存在本地。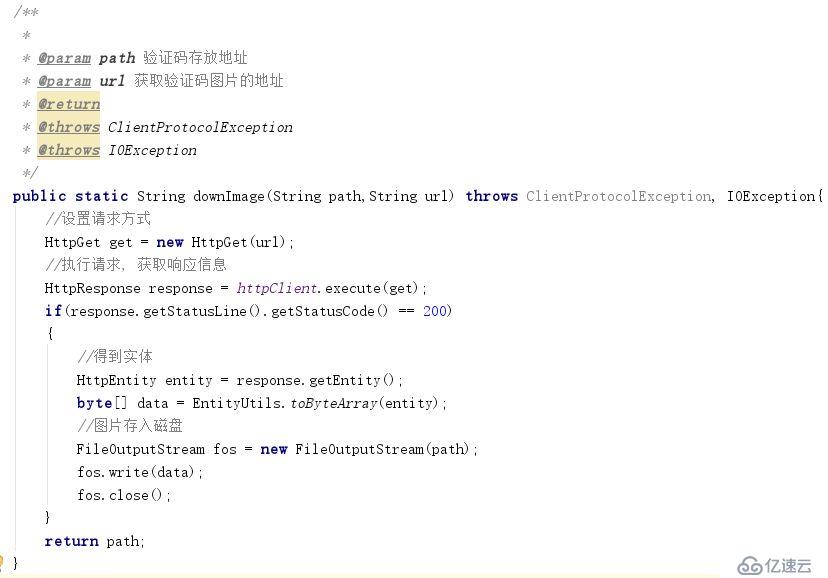
二、区分样本。对每张验证码图片进行人工识别区分,重命名为该图片的验证码。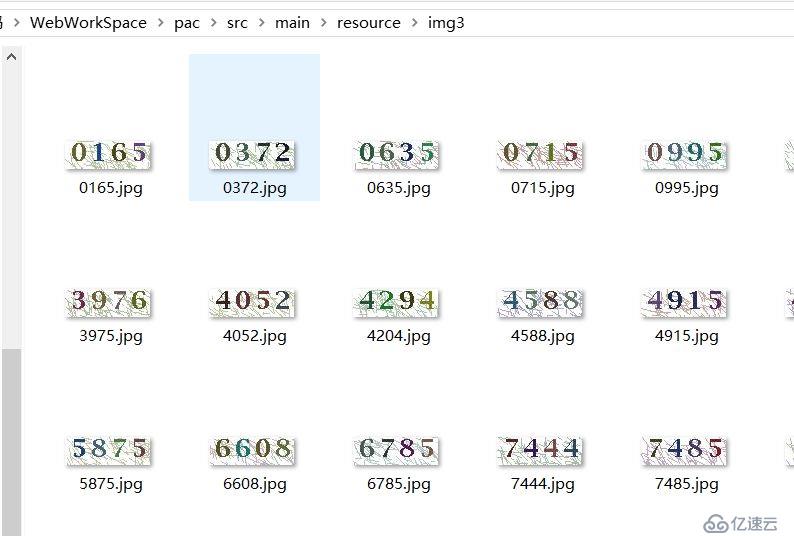
三、清洗切割样本,提取样本特征。图片识别需要尽可能细地区分出特征点。我们观察上图的验证码图片可以发现多个信息:
● 验证码的背景存在着许多干扰线。
● 每个数字分明,所占的位置几乎是均等的。
● 验证码的数字颜色比较深,干扰因素颜色较浅。
我们可以尝试通过颜色的深浅去除干扰因素。先通过灰度处理,将验证码中颜色较浅的点置换成白色,颜色较深的点置换成黑色。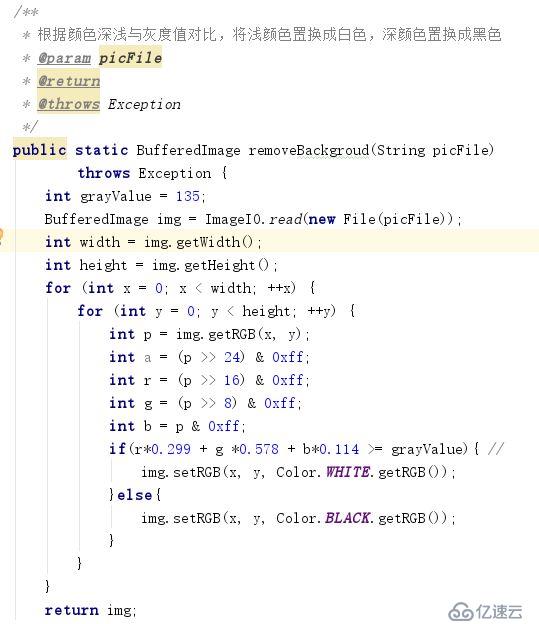
通过改变灰度阈值grayValue不断尝试去除干扰点。最后得到干净的验证码。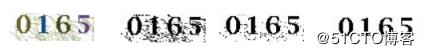
接下来通过识别图片中的黑色点,使用下面的trainData()方法。
沿着黑色点进行矩形切割,得到单个数字的特征样本。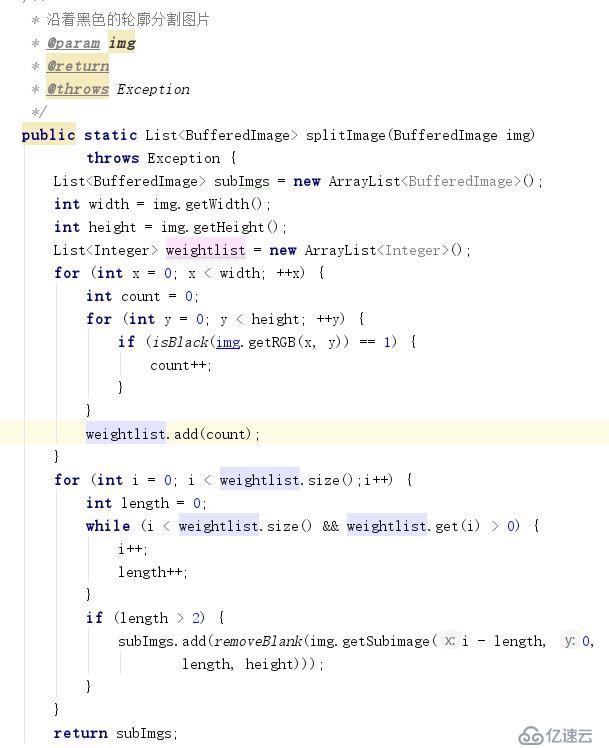

得到的验证码特征样本训练集合如下:
四、提取目标验证码的特征,与训练集合做对比,识别目标验证码图片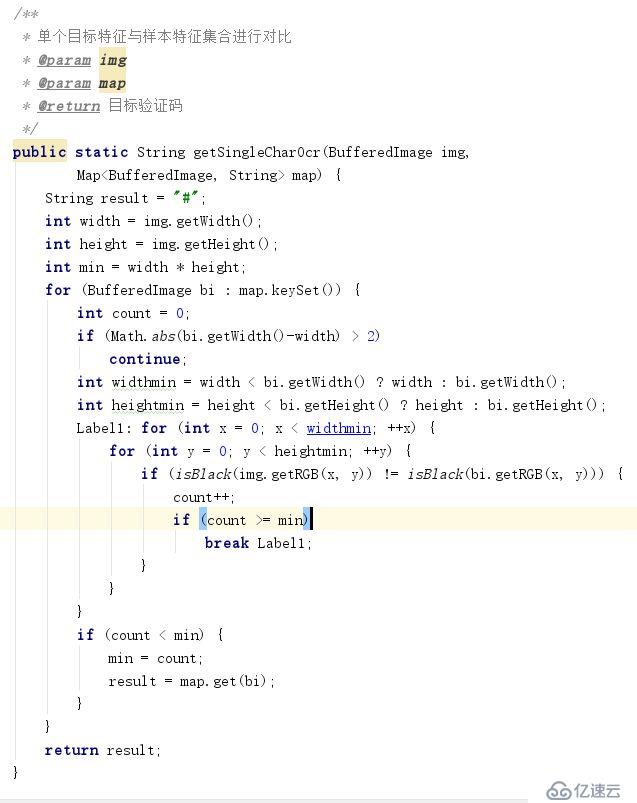
通过上面的三步,我们已经得到了一组样本特征,接下来只需要把将目标验证码同样执行上面的3步。把提取出来的目标验证码特征与样本特征作对比。如果双方绝大部分像素点的颜色相同,则可认为目标验证码与样本内容一致。取样本的文件名,即可等到目标验证的内容了。以下为对比识别的代码。
通过上面的四部操作,我们已经能够识别出一些网站的验证码了。上面使用的方法是通过颜色的深浅,去除干扰素,再提取样本特征进行对比。面对其他的一些验证码需要我们通过观察掌握图片的规律,灵活地使用其他的算法来识别去除干扰素,提取出样本特征。
同样地,在生成验证码的过程中,我们需要避免生成易于去除的干扰素。各个验证码之间在不影响人工识别的情况下尽可能粘连起来,避免被切割分类。
文章来自公众号:睿江云计算
睿江云官网链接:https://www.eflycloud.com/home?from=RJ0024
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





